 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU$^2$Mamba: A Two-level Nested U-structure Mamba for Salient Object Detection
Jun 18, 2026Mamba-based models have emerged as a promising alternative for salient object detection (SOD), offering significant advantages in modeling long sequences. However, existing models often fail to explore contextual information and the depth of the entire architecture. This paper introduces U$^2$Mamba, a powerful and innovative U-structured network for salient object detection. We propose multiscale Mamba U-blocks (MMUBs) that enhance the model depth to improve local feature extraction capabilities. Our newly developed nested U-structure, incorporating MMUBs, enables the network to integrate various receptive fields from shallow and deep layers, thereby collecting richer contextual information and longer-range data without being constrained by resolution. Instead of using the traditional deep supervision scheme and top-level supervised training, we propose a hierarchical training supervision method where the loss is computed at each level during the training process. Extensive experiments demonstrate that U$^2$Mamba achieves highly competitive performance against state-of-the-art methods. The source code is available at \url{https://github.com/JL021/U2Mamba}.
FruitEnsemble: MLLM-Guided Arbitration for Heterogeneous ensemble in Fine-Grained Fruit Recognition
May 20, 2026Fine-grained fruit classification is a critical yet challenging task in agricultural computer vision, primarily hindered by a severe shortage of high-quality datasets and the high visual similarity between classes. To address these challenges, we first constructed a comprehensive dataset comprising 306 fruit categories with 116,233 samples. Moreover, we propose FruitEnsemble, a practical two-stage dynamic inference framework designed to overcome the generalization limitations of static single-model architectures. In the first stage, FruitEnsemble employs a validation-calibrated weighted ensemble of heterogeneous backbones to generate a robust Top-3 candidate pool. To tackle difficult samples, we introduce an expert arbitration mechanism: when ensemble confidence falls below 0.6, a multimodal large language model (MLLM) is triggered to perform rigorous visual verification by integrating external botanical descriptions using Chain-of-Thought (CoT) reasoning. Furthermore, we optimized the training pipeline with a hard sample-aware joint loss. Extensive experiments demonstrate that FruitEnsemble achieves a classification accuracy of 70.49\% and outperforms existing state-of-the-art models. Our framework provides an efficient, deployment-oriented solution for real-world agricultural visual sorting and quality inspection tasks.
* 10 pages,6 figures,submitted to CVPR 2026
Unifying VLM-Guided Flow Matching and Spectral Anomaly Detection for Interpretable Veterinary Diagnosis
Apr 07, 2026Automatic diagnosis of canine pneumothorax is challenged by data scarcity and the need for trustworthy models. To address this, we first introduce a public, pixel-level annotated dataset to facilitate research. We then propose a novel diagnostic paradigm that reframes the task as a synergistic process of signal localization and spectral detection. For localization, our method employs a Vision-Language Model (VLM) to guide an iterative Flow Matching process, which progressively refines segmentation masks to achieve superior boundary accuracy. For detection, the segmented mask is used to isolate features from the suspected lesion. We then apply Random Matrix Theory (RMT), a departure from traditional classifiers, to analyze these features. This approach models healthy tissue as predictable random noise and identifies pneumothorax by detecting statistically significant outlier eigenvalues that represent a non-random pathological signal. The high-fidelity localization from Flow Matching is crucial for purifying the signal, thus maximizing the sensitivity of our RMT detector. This synergy of generative segmentation and first-principles statistical analysis yields a highly accurate and interpretable diagnostic system (source code is available at: https://github.com/Pu-Wang-alt/Canine-pneumothorax).
MambaVoiceCloning: Efficient and Expressive Text-to-Speech via State-Space Modeling and Diffusion Control
Mar 31, 2026MambaVoiceCloning (MVC) asks whether the conditioning path of diffusion-based TTS can be made fully SSM-only at inference, removing all attention and explicit RNN-style recurrence layers across text, rhythm, and prosody, while preserving or improving quality under controlled conditions. MVC combines a gated bidirectional Mamba text encoder, a Temporal Bi-Mamba supervised by a lightweight alignment teacher discarded after training, and an Expressive Mamba with AdaLN modulation, yielding linear-time O(T) conditioning with bounded activation memory and practical finite look-ahead streaming. Unlike prior Mamba-TTS systems that remain hybrid at inference, MVC removes attention-based duration and style modules under a fixed StyleTTS2 mel-diffusion-vocoder backbone. Trained on LJSpeech/LibriTTS and evaluated on VCTK, CSS10 (ES/DE/FR), and long-form Gutenberg passages, MVC achieves modest but statistically reliable gains over StyleTTS2, VITS, and Mamba-attention hybrids in MOS/CMOS, F0 RMSE, MCD, and WER, while reducing encoder parameters to 21M and improving throughput by 1.6x. Diffusion remains the dominant latency source, but SSM-only conditioning improves memory footprint, stability, and deployability.
CAST-LUT: Tokenizer-Guided HSV Look-Up Tables for Purple Flare Removal
Nov 10, 2025Purple flare, a diffuse chromatic aberration artifact commonly found around highlight areas, severely degrades the tone transition and color of the image. Existing traditional methods are based on hand-crafted features, which lack flexibility and rely entirely on fixed priors, while the scarcity of paired training data critically hampers deep learning. To address this issue, we propose a novel network built upon decoupled HSV Look-Up Tables (LUTs). The method aims to simplify color correction by adjusting the Hue (H), Saturation (S), and Value (V) components independently. This approach resolves the inherent color coupling problems in traditional methods. Our model adopts a two-stage architecture: First, a Chroma-Aware Spectral Tokenizer (CAST) converts the input image from RGB space to HSV space and independently encodes the Hue (H) and Value (V) channels into a set of semantic tokens describing the Purple flare status; second, the HSV-LUT module takes these tokens as input and dynamically generates independent correction curves (1D-LUTs) for the three channels H, S, and V. To effectively train and validate our model, we built the first large-scale purple flare dataset with diverse scenes. We also proposed new metrics and a loss function specifically designed for this task. Extensive experiments demonstrate that our model not only significantly outperforms existing methods in visual effects but also achieves state-of-the-art performance on all quantitative metrics.
UHD Image Dehazing via anDehazeFormer with Atmospheric-aware KV Cache
May 20, 2025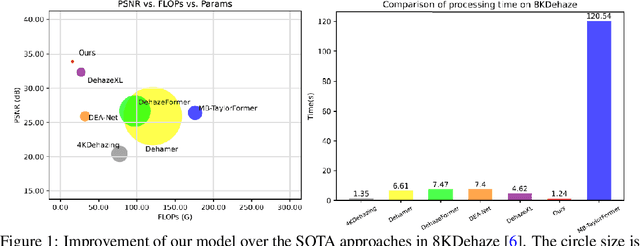



In this paper, we propose an efficient visual transformer framework for ultra-high-definition (UHD) image dehazing that addresses the key challenges of slow training speed and high memory consumption for existing methods. Our approach introduces two key innovations: 1) an \textbf{a}daptive \textbf{n}ormalization mechanism inspired by the nGPT architecture that enables ultra-fast and stable training with a network with a restricted range of parameter expressions; and 2) we devise an atmospheric scattering-aware KV caching mechanism that dynamically optimizes feature preservation based on the physical haze formation model. The proposed architecture improves the training convergence speed by \textbf{5 $\times$} while reducing memory overhead, enabling real-time processing of 50 high-resolution images per second on an RTX4090 GPU. Experimental results show that our approach maintains state-of-the-art dehazing quality while significantly improving computational efficiency for 4K/8K image restoration tasks. Furthermore, we provide a new dehazing image interpretable method with the help of an integrated gradient attribution map. Our code can be found here: https://anonymous.4open.science/r/anDehazeFormer-632E/README.md.
AgentPolyp: Accurate Polyp Segmentation via Image Enhancement Agent
Apr 15, 2025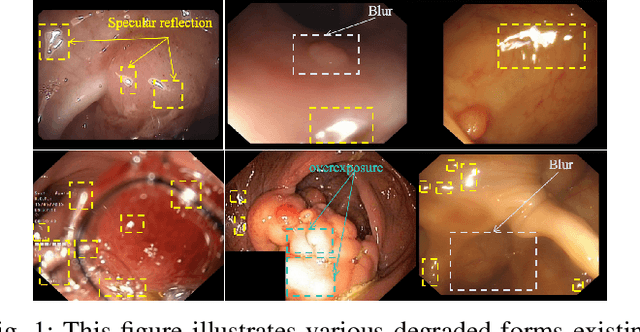
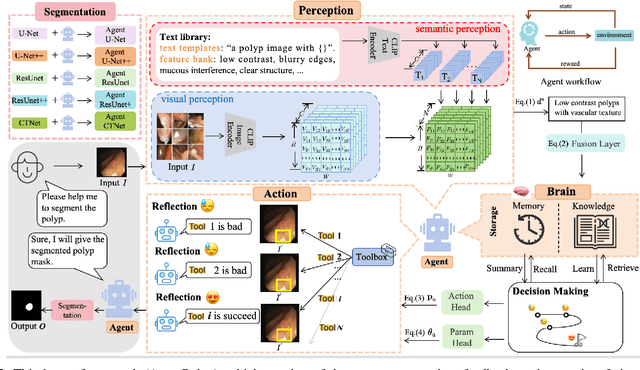
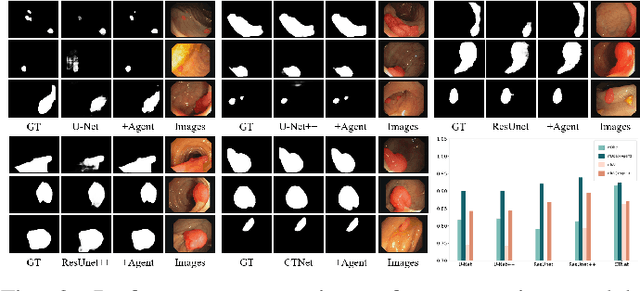
Since human and environmental factors interfere, captured polyp images usually suffer from issues such as dim lighting, blur, and overexposure, which pose challenges for downstream polyp segmentation tasks. To address the challenges of noise-induced degradation in polyp images, we present AgentPolyp, a novel framework integrating CLIP-based semantic guidance and dynamic image enhancement with a lightweight neural network for segmentation. The agent first evaluates image quality using CLIP-driven semantic analysis (e.g., identifying ``low-contrast polyps with vascular textures") and adapts reinforcement learning strategies to dynamically apply multi-modal enhancement operations (e.g., denoising, contrast adjustment). A quality assessment feedback loop optimizes pixel-level enhancement and segmentation focus in a collaborative manner, ensuring robust preprocessing before neural network segmentation. This modular architecture supports plug-and-play extensions for various enhancement algorithms and segmentation networks, meeting deployment requirements for endoscopic devices.
Automatic Teaching Platform on Vision Language Retrieval Augmented Generation
Mar 07, 2025Automating teaching presents unique challenges, as replicating human interaction and adaptability is complex. Automated systems cannot often provide nuanced, real-time feedback that aligns with students' individual learning paces or comprehension levels, which can hinder effective support for diverse needs. This is especially challenging in fields where abstract concepts require adaptive explanations. In this paper, we propose a vision language retrieval augmented generation (named VL-RAG) system that has the potential to bridge this gap by delivering contextually relevant, visually enriched responses that can enhance comprehension. By leveraging a database of tailored answers and images, the VL-RAG system can dynamically retrieve information aligned with specific questions, creating a more interactive and engaging experience that fosters deeper understanding and active student participation. It allows students to explore concepts visually and verbally, promoting deeper understanding and reducing the need for constant human oversight while maintaining flexibility to expand across different subjects and course material.
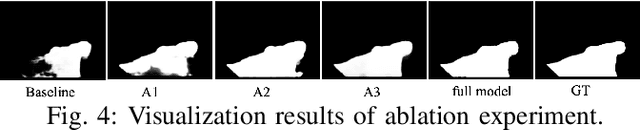
SST-EM: Advanced Metrics for Evaluating Semantic, Spatial and Temporal Aspects in Video Editing
Jan 13, 2025


Video editing models have advanced significantly, but evaluating their performance remains challenging. Traditional metrics, such as CLIP text and image scores, often fall short: text scores are limited by inadequate training data and hierarchical dependencies, while image scores fail to assess temporal consistency. We present SST-EM (Semantic, Spatial, and Temporal Evaluation Metric), a novel evaluation framework that leverages modern Vision-Language Models (VLMs), Object Detection, and Temporal Consistency checks. SST-EM comprises four components: (1) semantic extraction from frames using a VLM, (2) primary object tracking with Object Detection, (3) focused object refinement via an LLM agent, and (4) temporal consistency assessment using a Vision Transformer (ViT). These components are integrated into a unified metric with weights derived from human evaluations and regression analysis. The name SST-EM reflects its focus on Semantic, Spatial, and Temporal aspects of video evaluation. SST-EM provides a comprehensive evaluation of semantic fidelity and temporal smoothness in video editing. The source code is available in the \textbf{\href{https://github.com/custommetrics-sst/SST_CustomEvaluationMetrics.git}{GitHub Repository}}.
Confident Pseudo-labeled Diffusion Augmentation for Canine Cardiomegaly Detection
Jan 13, 2025



Canine cardiomegaly, marked by an enlarged heart, poses serious health risks if undetected, requiring accurate diagnostic methods. Current detection models often rely on small, poorly annotated datasets and struggle to generalize across diverse imaging conditions, limiting their real-world applicability. To address these issues, we propose a Confident Pseudo-labeled Diffusion Augmentation (CDA) model for identifying canine cardiomegaly. Our approach addresses the challenge of limited high-quality training data by employing diffusion models to generate synthetic X-ray images and annotate Vertebral Heart Score key points, thereby expanding the dataset. We also employ a pseudo-labeling strategy with Monte Carlo Dropout to select high-confidence labels, refine the synthetic dataset, and improve accuracy. Iteratively incorporating these labels enhances the model's performance, overcoming the limitations of existing approaches. Experimental results show that the CDA model outperforms traditional methods, achieving state-of-the-art accuracy in canine cardiomegaly detection. The code implementation is available at https://github.com/Shira7z/CDA.