 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Knowledge-Enhanced Two-Stage Reasoner for Multimodal Dialog Systems
Sep 09, 2025


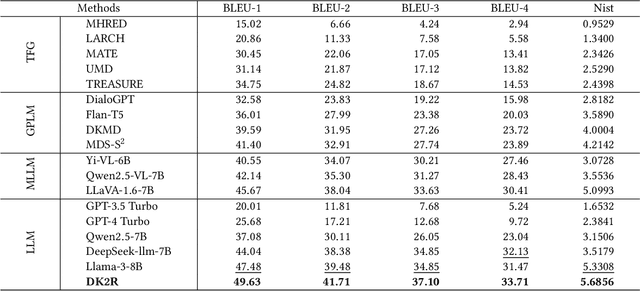
Textual response generation is pivotal for multimodal \mbox{task-oriented} dialog systems, which aims to generate proper textual responses based on the multimodal context. While existing efforts have demonstrated remarkable progress, there still exist the following limitations: 1) \textit{neglect of unstructured review knowledge} and 2) \textit{underutilization of large language models (LLMs)}. Inspired by this, we aim to fully utilize dual knowledge (\textit{i.e., } structured attribute and unstructured review knowledge) with LLMs to promote textual response generation in multimodal task-oriented dialog systems. However, this task is non-trivial due to two key challenges: 1) \textit{dynamic knowledge type selection} and 2) \textit{intention-response decoupling}. To address these challenges, we propose a novel dual knowledge-enhanced two-stage reasoner by adapting LLMs for multimodal dialog systems (named DK2R). To be specific, DK2R first extracts both structured attribute and unstructured review knowledge from external knowledge base given the dialog context. Thereafter, DK2R uses an LLM to evaluate each knowledge type's utility by analyzing LLM-generated provisional probe responses. Moreover, DK2R separately summarizes the intention-oriented key clues via dedicated reasoning, which are further used as auxiliary signals to enhance LLM-based textual response generation. Extensive experiments conducted on a public dataset verify the superiority of DK2R. We have released the codes and parameters.
Transmission Line Outage Probability Prediction Under Extreme Events Using Peter-Clark Bayesian Structural Learning
Nov 18, 2024
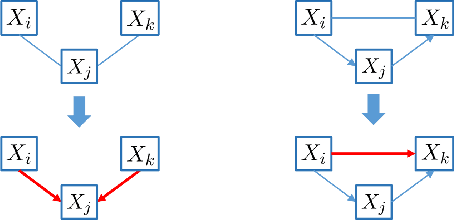
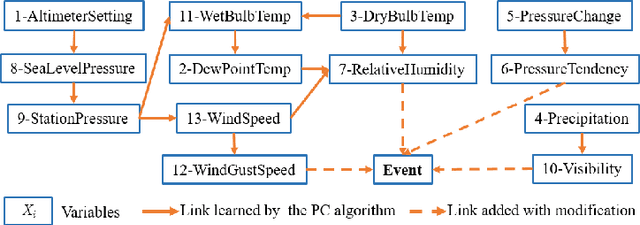
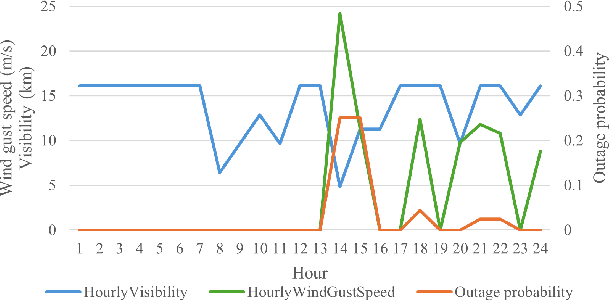
Recent years have seen a notable increase in the frequency and intensity of extreme weather events. With a rising number of power outages caused by these events, accurate prediction of power line outages is essential for safe and reliable operation of power grids. The Bayesian network is a probabilistic model that is very effective for predicting line outages under weather-related uncertainties. However, most existing studies in this area offer general risk assessments, but fall short of providing specific outage probabilities. In this work, we introduce a novel approach for predicting transmission line outage probabilities using a Bayesian network combined with Peter-Clark (PC) structural learning. Our approach not only enables precise outage probability calculations, but also demonstrates better scalability and robust performance, even with limited data. Case studies using data from BPA and NOAA show the effectiveness of this approach, while comparisons with several existing methods further highlight its advantages.
Do Vision-Language Transformers Exhibit Visual Commonsense? An Empirical Study of VCR
May 27, 2024



Visual Commonsense Reasoning (VCR) calls for explanatory reasoning behind question answering over visual scenes. To achieve this goal, a model is required to provide an acceptable rationale as the reason for the predicted answers. Progress on the benchmark dataset stems largely from the recent advancement of Vision-Language Transformers (VL Transformers). These models are first pre-trained on some generic large-scale vision-text datasets, and then the learned representations are transferred to the downstream VCR task. Despite their attractive performance, this paper posits that the VL Transformers do not exhibit visual commonsense, which is the key to VCR. In particular, our empirical results pinpoint several shortcomings of existing VL Transformers: small gains from pre-training, unexpected language bias, limited model architecture for the two inseparable sub-tasks, and neglect of the important object-tag correlation. With these findings, we tentatively suggest some future directions from the aspect of dataset, evaluation metric, and training tricks. We believe this work could make researchers revisit the intuition and goals of VCR, and thus help tackle the remaining challenges in visual reasoning.
CodeS: Natural Language to Code Repository via Multi-Layer Sketch
Mar 25, 2024



The impressive performance of large language models (LLMs) on code-related tasks has shown the potential of fully automated software development. In light of this, we introduce a new software engineering task, namely Natural Language to code Repository (NL2Repo). This task aims to generate an entire code repository from its natural language requirements. To address this task, we propose a simple yet effective framework CodeS, which decomposes NL2Repo into multiple sub-tasks by a multi-layer sketch. Specifically, CodeS includes three modules: RepoSketcher, FileSketcher, and SketchFiller. RepoSketcher first generates a repository's directory structure for given requirements; FileSketcher then generates a file sketch for each file in the generated structure; SketchFiller finally fills in the details for each function in the generated file sketch. To rigorously assess CodeS on the NL2Repo task, we carry out evaluations through both automated benchmarking and manual feedback analysis. For benchmark-based evaluation, we craft a repository-oriented benchmark, SketchEval, and design an evaluation metric, SketchBLEU. For feedback-based evaluation, we develop a VSCode plugin for CodeS and engage 30 participants in conducting empirical studies. Extensive experiments prove the effectiveness and practicality of CodeS on the NL2Repo task.
Interactive Garment Recommendation with User in the Loop
Feb 18, 2024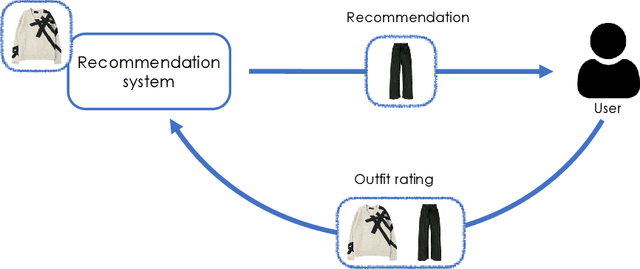
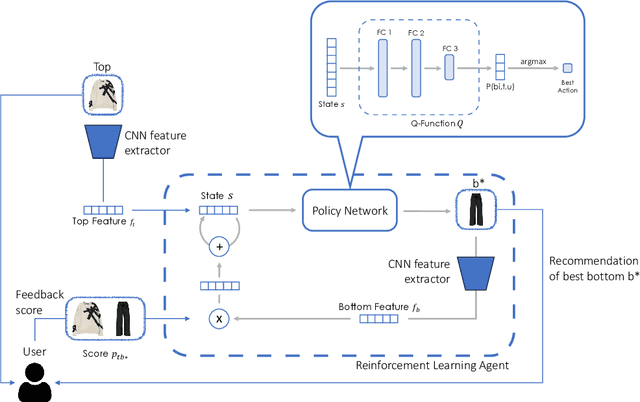

Recommending fashion items often leverages rich user profiles and makes targeted suggestions based on past history and previous purchases. In this paper, we work under the assumption that no prior knowledge is given about a user. We propose to build a user profile on the fly by integrating user reactions as we recommend complementary items to compose an outfit. We present a reinforcement learning agent capable of suggesting appropriate garments and ingesting user feedback so to improve its recommendations and maximize user satisfaction. To train such a model, we resort to a proxy model to be able to simulate having user feedback in the training loop. We experiment on the IQON3000 fashion dataset and we find that a reinforcement learning-based agent becomes capable of improving its recommendations by taking into account personal preferences. Furthermore, such task demonstrated to be hard for non-reinforcement models, that cannot exploit exploration during training.
Improving Natural Language Capability of Code Large Language Model
Jan 25, 2024Code large language models (Code LLMs) have demonstrated remarkable performance in code generation. Nonetheless, most existing works focus on boosting code LLMs from the perspective of programming capabilities, while their natural language capabilities receive less attention. To fill this gap, we thus propose a novel framework, comprising two modules: AttentionExtractor, which is responsible for extracting key phrases from the user's natural language requirements, and AttentionCoder, which leverages these extracted phrases to generate target code to solve the requirement. This framework pioneers an innovative idea by seamlessly integrating code LLMs with traditional natural language processing tools. To validate the effectiveness of the framework, we craft a new code generation benchmark, called MultiNL-H, covering five natural languages. Extensive experimental results demonstrate the effectiveness of our proposed framework.
A GAN-based data poisoning framework against anomaly detection in vertical federated learning
Jan 17, 2024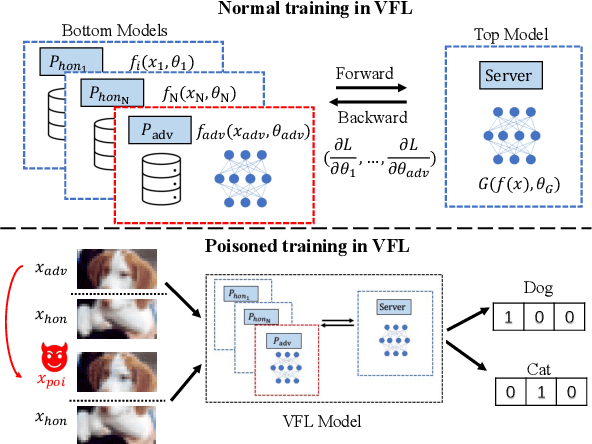
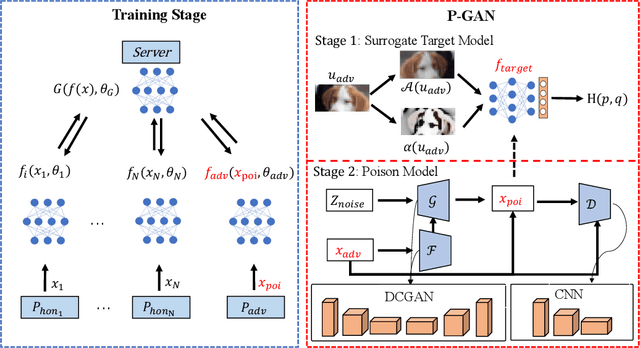
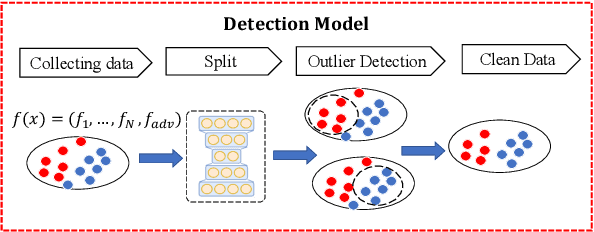
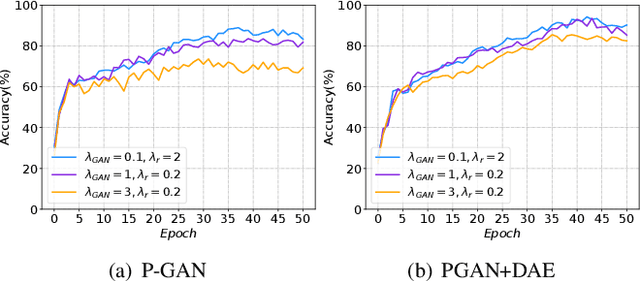
In vertical federated learning (VFL), commercial entities collaboratively train a model while preserving data privacy. However, a malicious participant's poisoning attack may degrade the performance of this collaborative model. The main challenge in achieving the poisoning attack is the absence of access to the server-side top model, leaving the malicious participant without a clear target model. To address this challenge, we introduce an innovative end-to-end poisoning framework P-GAN. Specifically, the malicious participant initially employs semi-supervised learning to train a surrogate target model. Subsequently, this participant employs a GAN-based method to produce adversarial perturbations to degrade the surrogate target model's performance. Finally, the generator is obtained and tailored for VFL poisoning. Besides, we develop an anomaly detection algorithm based on a deep auto-encoder (DAE), offering a robust defense mechanism to VFL scenarios. Through extensive experiments, we evaluate the efficacy of P-GAN and DAE, and further analyze the factors that influence their performance.
Enhancing LLM with Evolutionary Fine Tuning for News Summary Generation
Jul 08, 2023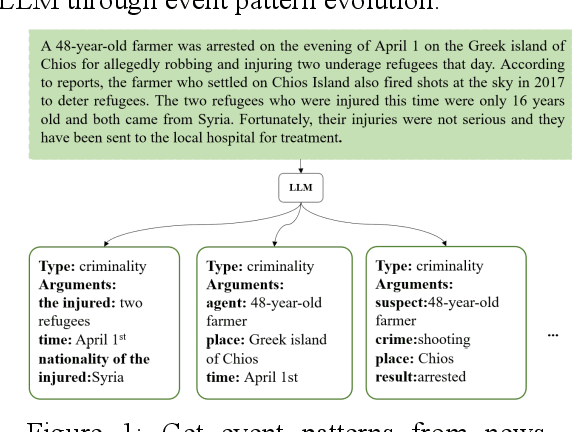
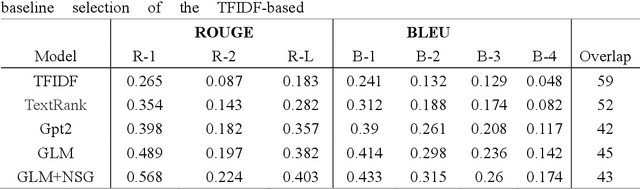
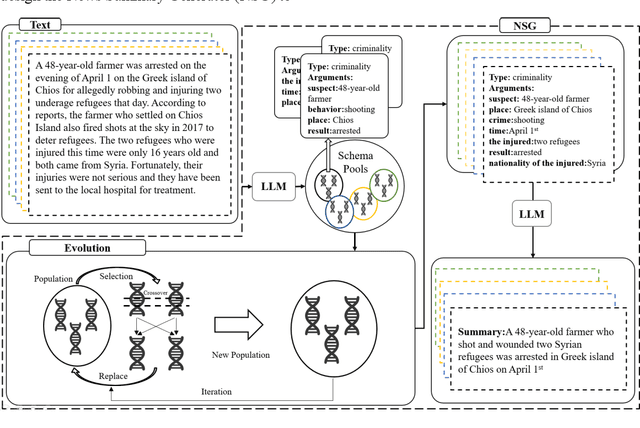
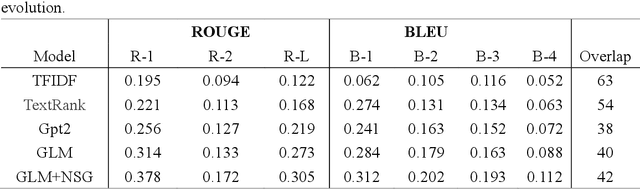
News summary generation is an important task in the field of intelligence analysis, which can provide accurate and comprehensive information to help people better understand and respond to complex real-world events. However, traditional news summary generation methods face some challenges, which are limited by the model itself and the amount of training data, as well as the influence of text noise, making it difficult to generate reliable information accurately. In this paper, we propose a new paradigm for news summary generation using LLM with powerful natural language understanding and generative capabilities. We use LLM to extract multiple structured event patterns from the events contained in news paragraphs, evolve the event pattern population with genetic algorithm, and select the most adaptive event pattern to input into the LLM to generate news summaries. A News Summary Generator (NSG) is designed to select and evolve the event pattern populations and generate news summaries. The experimental results show that the news summary generator is able to generate accurate and reliable news summaries with some generalization ability.
Dual Semantic Knowledge Composed Multimodal Dialog Systems
May 17, 2023
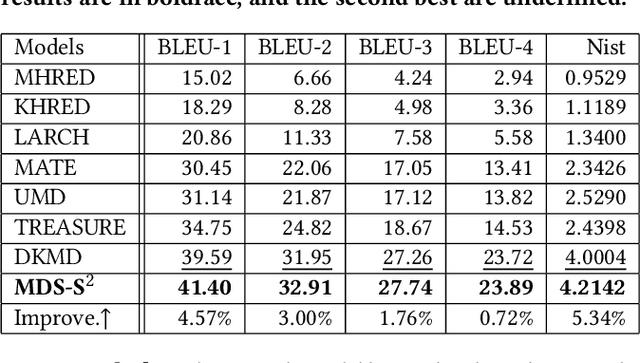
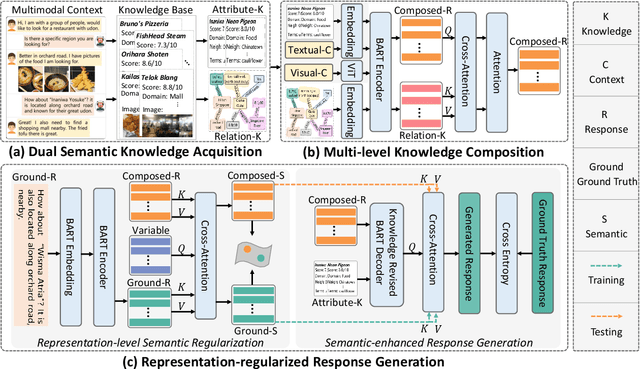
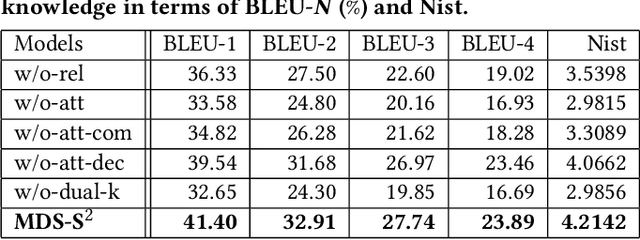
Textual response generation is an essential task for multimodal task-oriented dialog systems.Although existing studies have achieved fruitful progress, they still suffer from two critical limitations: 1) focusing on the attribute knowledge but ignoring the relation knowledge that can reveal the correlations between different entities and hence promote the response generation}, and 2) only conducting the cross-entropy loss based output-level supervision but lacking the representation-level regularization. To address these limitations, we devise a novel multimodal task-oriented dialog system (named MDS-S2). Specifically, MDS-S2 first simultaneously acquires the context related attribute and relation knowledge from the knowledge base, whereby the non-intuitive relation knowledge is extracted by the n-hop graph walk. Thereafter, considering that the attribute knowledge and relation knowledge can benefit the responding to different levels of questions, we design a multi-level knowledge composition module in MDS-S2 to obtain the latent composed response representation. Moreover, we devise a set of latent query variables to distill the semantic information from the composed response representation and the ground truth response representation, respectively, and thus conduct the representation-level semantic regularization. Extensive experiments on a public dataset have verified the superiority of our proposed MDS-S2. We have released the codes and parameters to facilitate the research community.
Multimodal Dialog Systems with Dual Knowledge-enhanced Generative Pretrained Language Model
Jul 16, 2022
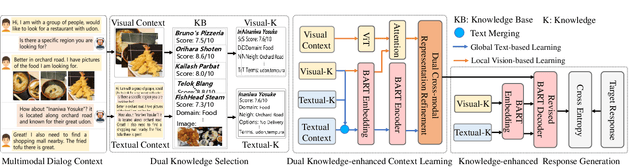
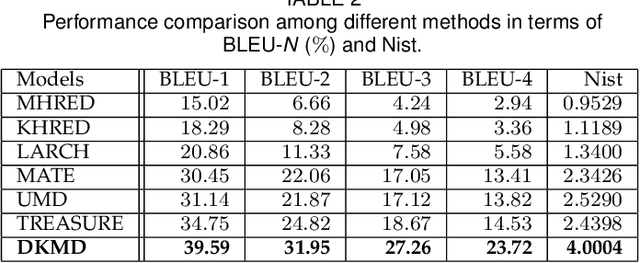
Text response generation for multimodal task-oriented dialog systems, which aims to generate the proper text response given the multimodal context, is an essential yet challenging task. Although existing efforts have achieved compelling success, they still suffer from two pivotal limitations: 1) overlook the benefit of generative pre-training, and 2) ignore the textual context related knowledge. To address these limitations, we propose a novel dual knowledge-enhanced generative pretrained language model for multimodal task-oriented dialog systems (DKMD), consisting of three key components: dual knowledge selection, dual knowledge-enhanced context learning, and knowledge-enhanced response generation. To be specific, the dual knowledge selection component aims to select the related knowledge according to both textual and visual modalities of the given context. Thereafter, the dual knowledge-enhanced context learning component targets seamlessly integrating the selected knowledge into the multimodal context learning from both global and local perspectives, where the cross-modal semantic relation is also explored. Moreover, the knowledge-enhanced response generation component comprises a revised BART decoder, where an additional dot-product knowledge-decoder attention sub-layer is introduced for explicitly utilizing the knowledge to advance the text response generation. Extensive experiments on a public dataset verify the superiority of the proposed DKMD over state-of-the-art competitors.