 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Knowledge-Enhanced Two-Stage Reasoner for Multimodal Dialog Systems
Sep 09, 2025


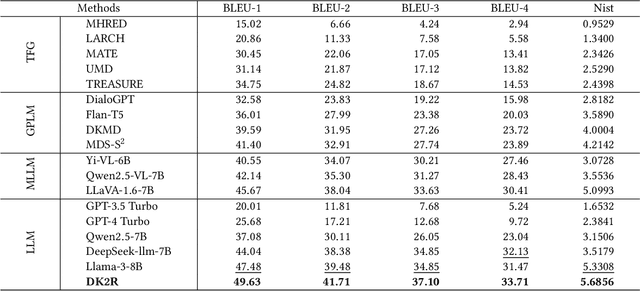
Textual response generation is pivotal for multimodal \mbox{task-oriented} dialog systems, which aims to generate proper textual responses based on the multimodal context. While existing efforts have demonstrated remarkable progress, there still exist the following limitations: 1) \textit{neglect of unstructured review knowledge} and 2) \textit{underutilization of large language models (LLMs)}. Inspired by this, we aim to fully utilize dual knowledge (\textit{i.e., } structured attribute and unstructured review knowledge) with LLMs to promote textual response generation in multimodal task-oriented dialog systems. However, this task is non-trivial due to two key challenges: 1) \textit{dynamic knowledge type selection} and 2) \textit{intention-response decoupling}. To address these challenges, we propose a novel dual knowledge-enhanced two-stage reasoner by adapting LLMs for multimodal dialog systems (named DK2R). To be specific, DK2R first extracts both structured attribute and unstructured review knowledge from external knowledge base given the dialog context. Thereafter, DK2R uses an LLM to evaluate each knowledge type's utility by analyzing LLM-generated provisional probe responses. Moreover, DK2R separately summarizes the intention-oriented key clues via dedicated reasoning, which are further used as auxiliary signals to enhance LLM-based textual response generation. Extensive experiments conducted on a public dataset verify the superiority of DK2R. We have released the codes and parameters.
FineCIR: Explicit Parsing of Fine-Grained Modification Semantics for Composed Image Retrieval
Mar 27, 2025
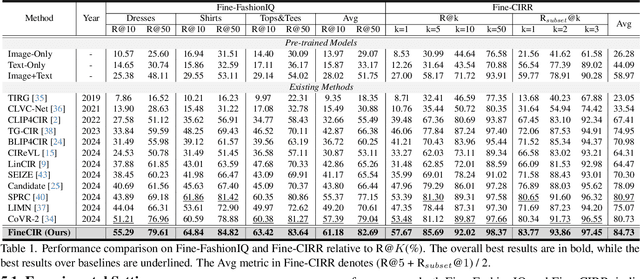
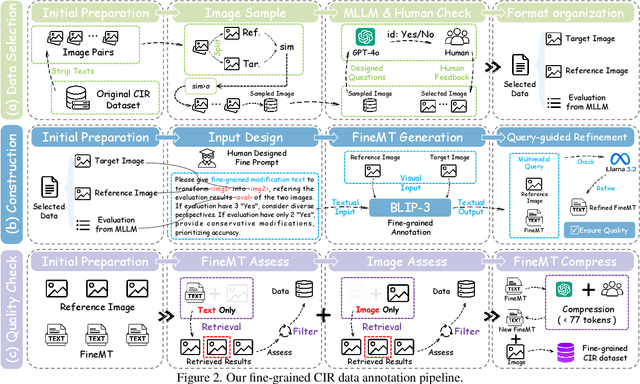
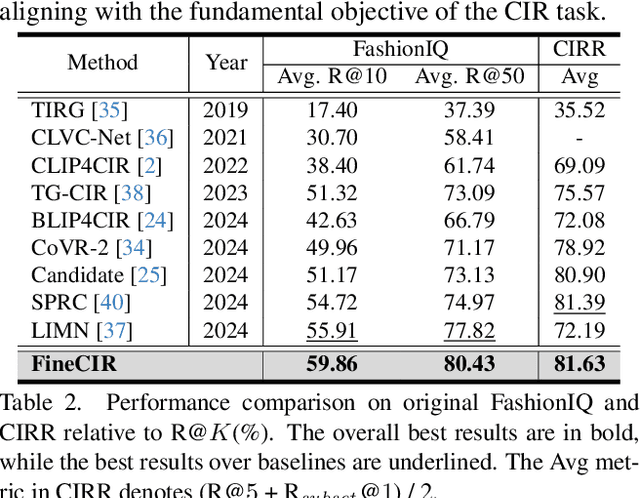
Composed Image Retrieval (CIR) facilitates image retrieval through a multimodal query consisting of a reference image and modification text. The reference image defines the retrieval context, while the modification text specifies desired alterations. However, existing CIR datasets predominantly employ coarse-grained modification text (CoarseMT), which inadequately captures fine-grained retrieval intents. This limitation introduces two key challenges: (1) ignoring detailed differences leads to imprecise positive samples, and (2) greater ambiguity arises when retrieving visually similar images. These issues degrade retrieval accuracy, necessitating manual result filtering or repeated queries. To address these limitations, we develop a robust fine-grained CIR data annotation pipeline that minimizes imprecise positive samples and enhances CIR systems' ability to discern modification intents accurately. Using this pipeline, we refine the FashionIQ and CIRR datasets to create two fine-grained CIR datasets: Fine-FashionIQ and Fine-CIRR. Furthermore, we introduce FineCIR, the first CIR framework explicitly designed to parse the modification text. FineCIR effectively captures fine-grained modification semantics and aligns them with ambiguous visual entities, enhancing retrieval precision. Extensive experiments demonstrate that FineCIR consistently outperforms state-of-the-art CIR baselines on both fine-grained and traditional CIR benchmark datasets. Our FineCIR code and fine-grained CIR datasets are available at https://github.com/SDU-L/FineCIR.git.
Fine-grained Textual Inversion Network for Zero-Shot Composed Image Retrieval
Mar 25, 2025Composed Image Retrieval (CIR) allows users to search target images with a multimodal query, comprising a reference image and a modification text that describes the user's modification demand over the reference image. Nevertheless, due to the expensive labor cost of training data annotation, recent researchers have shifted to the challenging task of zero-shot CIR (ZS-CIR), which targets fulfilling CIR without annotated triplets. The pioneer ZS-CIR studies focus on converting the CIR task into a standard text-to-image retrieval task by pre-training a textual inversion network that can map a given image into a single pseudo-word token. Despite their significant progress, their coarse-grained textual inversion may be insufficient to capture the full content of the image accurately. To overcome this issue, in this work, we propose a novel Fine-grained Textual Inversion Network for ZS-CIR, named FTI4CIR. In particular, FTI4CIR comprises two main components: fine-grained pseudo-word token mapping and tri-wise caption-based semantic regularization. The former maps the image into a subject-oriented pseudo-word token and several attribute-oriented pseudo-word tokens to comprehensively express the image in the textual form, while the latter works on jointly aligning the fine-grained pseudo-word tokens to the real-word token embedding space based on a BLIP-generated image caption template. Extensive experiments conducted on three benchmark datasets demonstrate the superiority of our proposed method.
A Comprehensive Survey on Composed Image Retrieval
Feb 19, 2025



Composed Image Retrieval (CIR) is an emerging yet challenging task that allows users to search for target images using a multimodal query, comprising a reference image and a modification text specifying the user's desired changes to the reference image. Given its significant academic and practical value, CIR has become a rapidly growing area of interest in the computer vision and machine learning communities, particularly with the advances in deep learning. To the best of our knowledge, there is currently no comprehensive review of CIR to provide a timely overview of this field. Therefore, we synthesize insights from over 120 publications in top conferences and journals, including ACM TOIS, SIGIR, and CVPR In particular, we systematically categorize existing supervised CIR and zero-shot CIR models using a fine-grained taxonomy. For a comprehensive review, we also briefly discuss approaches for tasks closely related to CIR, such as attribute-based CIR and dialog-based CIR. Additionally, we summarize benchmark datasets for evaluation and analyze existing supervised and zero-shot CIR methods by comparing experimental results across multiple datasets. Furthermore, we present promising future directions in this field, offering practical insights for researchers interested in further exploration.
Pseudo-triplet Guided Few-shot Composed Image Retrieval
Jul 08, 2024



Composed Image Retrieval (CIR) is a challenging task that aims to retrieve the target image based on a multimodal query, i.e., a reference image and its corresponding modification text. While previous supervised or zero-shot learning paradigms all fail to strike a good trade-off between time-consuming annotation cost and retrieval performance, recent researchers introduced the task of few-shot CIR (FS-CIR) and proposed a textual inversion-based network based on pretrained CLIP model to realize it. Despite its promising performance, the approach suffers from two key limitations: insufficient multimodal query composition training and indiscriminative training triplet selection. To address these two limitations, in this work, we propose a novel two-stage pseudo triplet guided few-shot CIR scheme, dubbed PTG-FSCIR. In the first stage, we employ a masked training strategy and advanced image caption generator to construct pseudo triplets from pure image data to enable the model to acquire primary knowledge related to multimodal query composition. In the second stage, based on active learning, we design a pseudo modification text-based query-target distance metric to evaluate the challenging score for each unlabeled sample. Meanwhile, we propose a robust top range-based random sampling strategy according to the 3-$\sigma$ rule in statistics, to sample the challenging samples for fine-tuning the pretrained model. Notably, our scheme is plug-and-play and compatible with any existing supervised CIR models. We tested our scheme across three backbones on three public datasets (i.e., FashionIQ, CIRR, and Birds-to-Words), achieving maximum improvements of 26.4%, 25.5% and 21.6% respectively, demonstrating our scheme's effectiveness.
Interactive Garment Recommendation with User in the Loop
Feb 18, 2024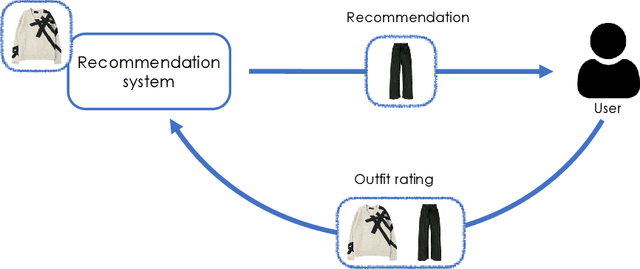
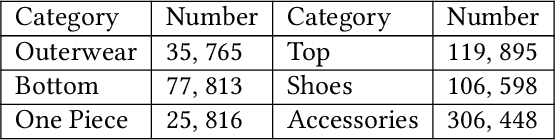
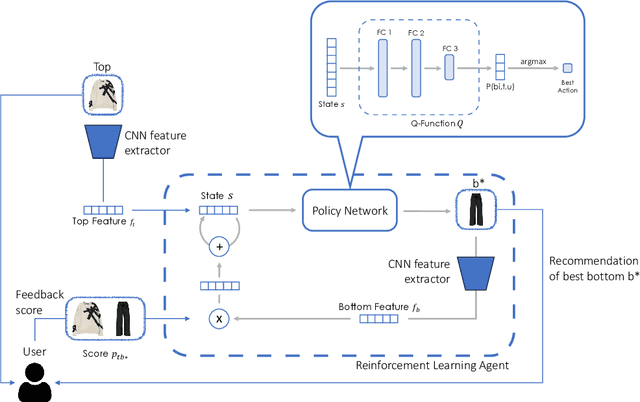

Recommending fashion items often leverages rich user profiles and makes targeted suggestions based on past history and previous purchases. In this paper, we work under the assumption that no prior knowledge is given about a user. We propose to build a user profile on the fly by integrating user reactions as we recommend complementary items to compose an outfit. We present a reinforcement learning agent capable of suggesting appropriate garments and ingesting user feedback so to improve its recommendations and maximize user satisfaction. To train such a model, we resort to a proxy model to be able to simulate having user feedback in the training loop. We experiment on the IQON3000 fashion dataset and we find that a reinforcement learning-based agent becomes capable of improving its recommendations by taking into account personal preferences. Furthermore, such task demonstrated to be hard for non-reinforcement models, that cannot exploit exploration during training.