 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on Composed Image Retrieval
Feb 19, 2025



Composed Image Retrieval (CIR) is an emerging yet challenging task that allows users to search for target images using a multimodal query, comprising a reference image and a modification text specifying the user's desired changes to the reference image. Given its significant academic and practical value, CIR has become a rapidly growing area of interest in the computer vision and machine learning communities, particularly with the advances in deep learning. To the best of our knowledge, there is currently no comprehensive review of CIR to provide a timely overview of this field. Therefore, we synthesize insights from over 120 publications in top conferences and journals, including ACM TOIS, SIGIR, and CVPR In particular, we systematically categorize existing supervised CIR and zero-shot CIR models using a fine-grained taxonomy. For a comprehensive review, we also briefly discuss approaches for tasks closely related to CIR, such as attribute-based CIR and dialog-based CIR. Additionally, we summarize benchmark datasets for evaluation and analyze existing supervised and zero-shot CIR methods by comparing experimental results across multiple datasets. Furthermore, we present promising future directions in this field, offering practical insights for researchers interested in further exploration.
Towards Stable and Storage-efficient Dataset Distillation: Matching Convexified Trajectory
Jun 28, 2024The rapid evolution of deep learning and large language models has led to an exponential growth in the demand for training data, prompting the development of Dataset Distillation methods to address the challenges of managing large datasets. Among these, Matching Training Trajectories (MTT) has been a prominent approach, which replicates the training trajectory of an expert network on real data with a synthetic dataset. However, our investigation found that this method suffers from three significant limitations: 1. Instability of expert trajectory generated by Stochastic Gradient Descent (SGD); 2. Low convergence speed of the distillation process; 3. High storage consumption of the expert trajectory. To address these issues, we offer a new perspective on understanding the essence of Dataset Distillation and MTT through a simple transformation of the objective function, and introduce a novel method called Matching Convexified Trajectory (MCT), which aims to provide better guidance for the student trajectory. MCT leverages insights from the linearized dynamics of Neural Tangent Kernel methods to create a convex combination of expert trajectories, guiding the student network to converge rapidly and stably. This trajectory is not only easier to store, but also enables a continuous sampling strategy during distillation, ensuring thorough learning and fitting of the entire expert trajectory. Comprehensive experiments across three public datasets validate the superiority of MCT over traditional MTT methods.
Unsupervised Temporal Action Localization via Self-paced Incremental Learning
Dec 12, 2023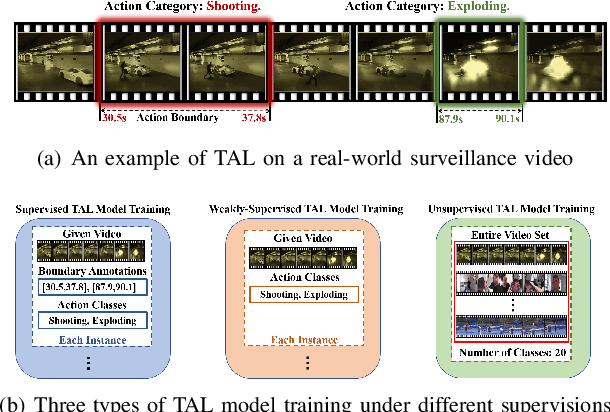
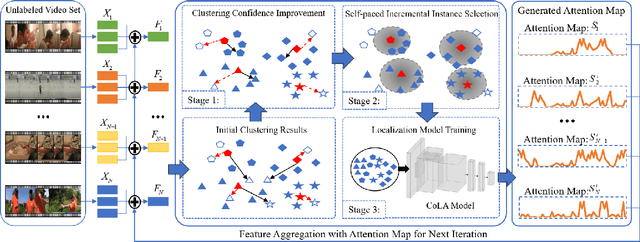
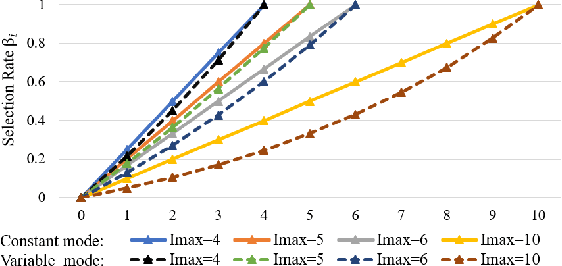
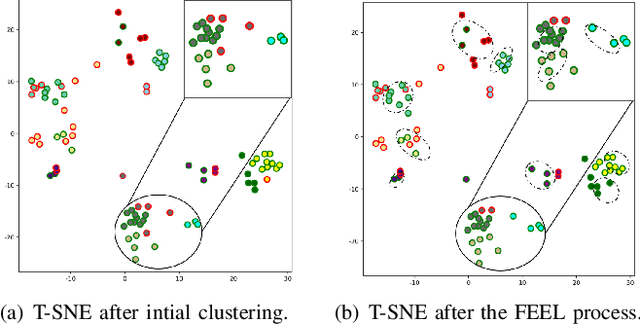
Recently, temporal action localization (TAL) has garnered significant interest in information retrieval community. However, existing supervised/weakly supervised methods are heavily dependent on extensive labeled temporal boundaries and action categories, which is labor-intensive and time-consuming. Although some unsupervised methods have utilized the ``iteratively clustering and localization'' paradigm for TAL, they still suffer from two pivotal impediments: 1) unsatisfactory video clustering confidence, and 2) unreliable video pseudolabels for model training. To address these limitations, we present a novel self-paced incremental learning model to enhance clustering and localization training simultaneously, thereby facilitating more effective unsupervised TAL. Concretely, we improve the clustering confidence through exploring the contextual feature-robust visual information. Thereafter, we design two (constant- and variable- speed) incremental instance learning strategies for easy-to-hard model training, thus ensuring the reliability of these video pseudolabels and further improving overall localization performance. Extensive experiments on two public datasets have substantiated the superiority of our model over several state-of-the-art competitors.