 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Few-Step Generation with Adaptive Matching Distillation
Feb 07, 2026Distribution Matching Distillation (DMD) is a powerful acceleration paradigm, yet its stability is often compromised in Forbidden Zone, regions where the real teacher provides unreliable guidance while the fake teacher exerts insufficient repulsive force. In this work, we propose a unified optimization framework that reinterprets prior art as implicit strategies to avoid these corrupted regions. Based on this insight, we introduce Adaptive Matching Distillation (AMD), a self-correcting mechanism that utilizes reward proxies to explicitly detect and escape Forbidden Zones. AMD dynamically prioritizes corrective gradients via structural signal decomposition and introduces Repulsive Landscape Sharpening to enforce steep energy barriers against failure mode collapse. Extensive experiments across image and video generation tasks (e.g., SDXL, Wan2.1) and rigorous benchmarks (e.g., VBench, GenEval) demonstrate that AMD significantly enhances sample fidelity and training robustness. For instance, AMD improves the HPSv2 score on SDXL from 30.64 to 31.25, outperforming state-of-the-art baselines. These findings validate that explicitly rectifying optimization trajectories within Forbidden Zones is essential for pushing the performance ceiling of few-step generative models.
PISA: Piecewise Sparse Attention Is Wiser for Efficient Diffusion Transformers
Feb 03, 2026Diffusion Transformers are fundamental for video and image generation, but their efficiency is bottlenecked by the quadratic complexity of attention. While block sparse attention accelerates computation by attending only critical key-value blocks, it suffers from degradation at high sparsity by discarding context. In this work, we discover that attention scores of non-critical blocks exhibit distributional stability, allowing them to be approximated accurately and efficiently rather than discarded, which is essentially important for sparse attention design. Motivated by this key insight, we propose PISA, a training-free Piecewise Sparse Attention that covers the full attention span with sub-quadratic complexity. Unlike the conventional keep-or-drop paradigm that directly drop the non-critical block information, PISA introduces a novel exact-or-approximate strategy: it maintains exact computation for critical blocks while efficiently approximating the remainder through block-wise Taylor expansion. This design allows PISA to serve as a faithful proxy to full attention, effectively bridging the gap between speed and quality. Experimental results demonstrate that PISA achieves 1.91 times and 2.57 times speedups on Wan2.1-14B and Hunyuan-Video, respectively, while consistently maintaining the highest quality among sparse attention methods. Notably, even for image generation on FLUX, PISA achieves a 1.2 times acceleration without compromising visual quality. Code is available at: https://github.com/xie-lab-ml/piecewise-sparse-attention.
Towards Principled Learning for Re-ranking in Recommender Systems
Apr 05, 2025



As the final stage of recommender systems, re-ranking presents ordered item lists to users that best match their interests. It plays such a critical role and has become a trending research topic with much attention from both academia and industry. Recent advances of re-ranking are focused on attentive listwise modeling of interactions and mutual influences among items to be re-ranked. However, principles to guide the learning process of a re-ranker, and to measure the quality of the output of the re-ranker, have been always missing. In this paper, we study such principles to learn a good re-ranker. Two principles are proposed, including convergence consistency and adversarial consistency. These two principles can be applied in the learning of a generic re-ranker and improve its performance. We validate such a finding by various baseline methods over different datasets.
MLLM4PUE: Toward Universal Embeddings in Computational Pathology through Multimodal LLMs
Feb 11, 2025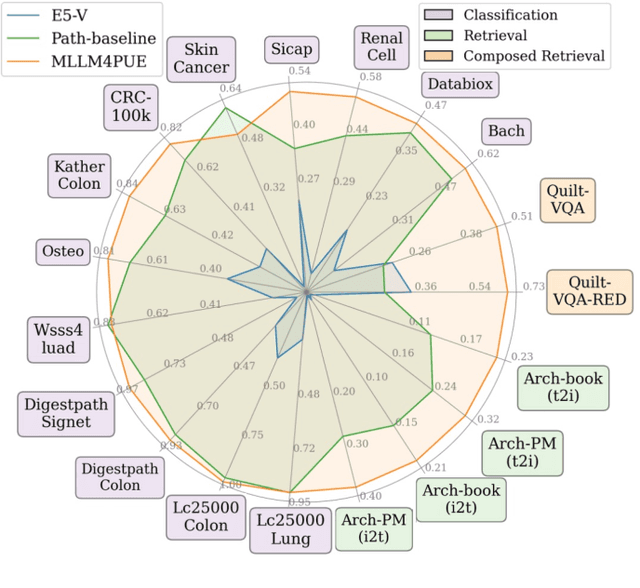
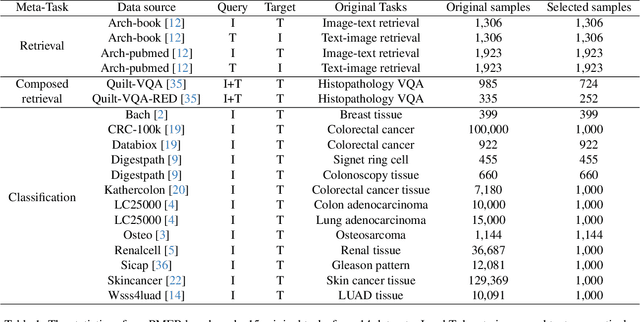
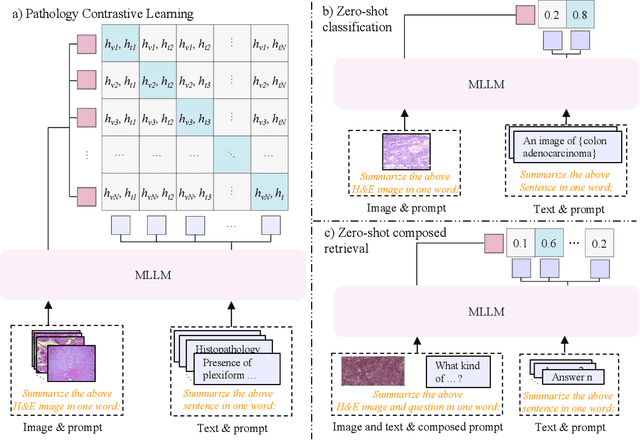
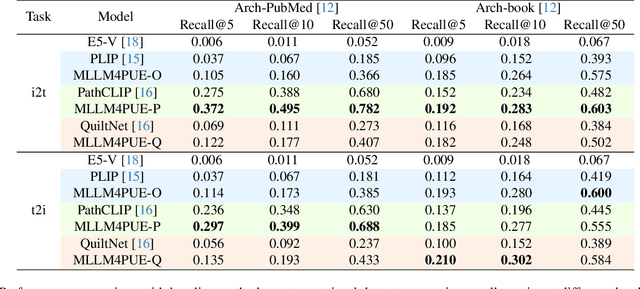
Pathology plays a critical role in diagnosing a wide range of diseases, yet existing approaches often rely heavily on task-specific models trained on extensive, well-labeled datasets. These methods face sustainability challenges due to the diversity of pathologies and the labor-intensive nature of data collection. To address these limitations, we highlight the need for universal multimodal embeddings that can support multiple downstream tasks. Previous approaches often involve fine-tuning CLIP-based models, which handle images and text separately, limiting their ability to capture complex multimodal relationships. Additionally, these models are evaluated across diverse datasets without a unified benchmark for assessing multimodal embeddings in pathology. To address these challenges, we propose MLLM4PUE, a novel framework that leverages Multimodal Large Language Models (MLLMs) to generate Pathology Universal Embeddings. The MLLM4PUE framework not only facilitates robust integration of images and text but also enhances understanding and fusion capabilities across various tasks. We further introduce the Pathology Multimodal Embedding Benchmark (PMEB), a comprehensive benchmark designed to assess the quality of pathology multimodal embeddings. PMEB comprises 15 original tasks drawn from 14 datasets, organized into three meta-tasks: retrieval, classification, and composed retrieval. Experimental results demonstrate the superiority of MLLM4PUE, illustrating MLLM-based models can effectively support a wide range of downstream tasks and unify the research direction for foundation models in pathology.
Compositional Image Retrieval via Instruction-Aware Contrastive Learning
Dec 07, 2024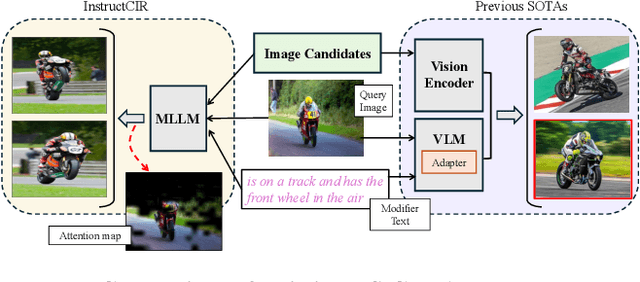
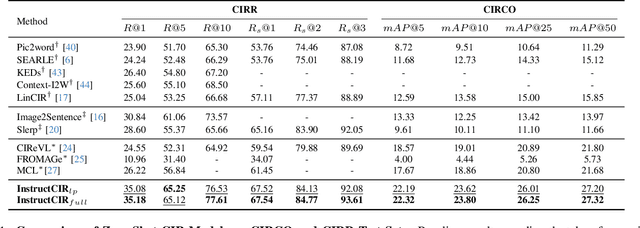

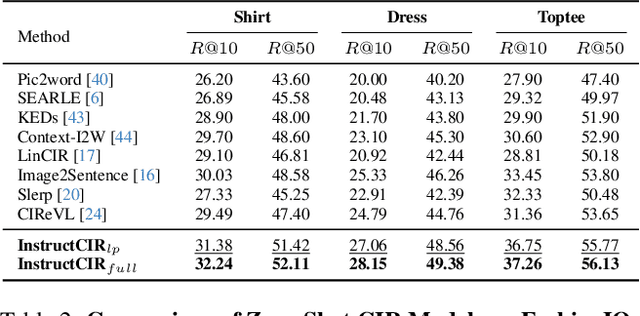
Composed Image Retrieval (CIR) involves retrieving a target image based on a composed query of an image paired with text that specifies modifications or changes to the visual reference. CIR is inherently an instruction-following task, as the model needs to interpret and apply modifications to the image. In practice, due to the scarcity of annotated data in downstream tasks, Zero-Shot CIR (ZS-CIR) is desirable. While existing ZS-CIR models based on CLIP have shown promising results, their capability in interpreting and following modification instructions remains limited. Some research attempts to address this by incorporating Large Language Models (LLMs). However, these approaches still face challenges in effectively integrating multimodal information and instruction understanding. To tackle above challenges, we propose a novel embedding method utilizing an instruction-tuned Multimodal LLM (MLLM) to generate composed representation, which significantly enhance the instruction following capability for a comprehensive integration between images and instructions. Nevertheless, directly applying MLLMs introduces a new challenge since MLLMs are primarily designed for text generation rather than embedding extraction as required in CIR. To address this, we introduce a two-stage training strategy to efficiently learn a joint multimodal embedding space and further refining the ability to follow modification instructions by tuning the model in a triplet dataset similar to the CIR format. Extensive experiments on four public datasets: FashionIQ, CIRR, GeneCIS, and CIRCO demonstrates the superior performance of our model, outperforming state-of-the-art baselines by a significant margin. Codes are available at the GitHub repository.
Identify Then Recommend: Towards Unsupervised Group Recommendation
Oct 31, 2024Group Recommendation (GR), which aims to recommend items to groups of users, has become a promising and practical direction for recommendation systems. This paper points out two issues of the state-of-the-art GR models. (1) The pre-defined and fixed number of user groups is inadequate for real-time industrial recommendation systems, where the group distribution can shift dynamically. (2) The training schema of existing GR methods is supervised, necessitating expensive user-group and group-item labels, leading to significant annotation costs. To this end, we present a novel unsupervised group recommendation framework named \underline{I}dentify \underline{T}hen \underline{R}ecommend (\underline{ITR}), where it first identifies the user groups in an unsupervised manner even without the pre-defined number of groups, and then two pre-text tasks are designed to conduct self-supervised group recommendation. Concretely, at the group identification stage, we first estimate the adaptive density of each user point, where areas with higher densities are more likely to be recognized as group centers. Then, a heuristic merge-and-split strategy is designed to discover the user groups and decision boundaries. Subsequently, at the self-supervised learning stage, the pull-and-repulsion pre-text task is proposed to optimize the user-group distribution. Besides, the pseudo group recommendation pre-text task is designed to assist the recommendations. Extensive experiments demonstrate the superiority and effectiveness of ITR on both user recommendation (e.g., 22.22\% NDCG@5 $\uparrow$) and group recommendation (e.g., 22.95\% NDCG@5 $\uparrow$). Furthermore, we deploy ITR on the industrial recommender and achieve promising results.
Towards Stable and Storage-efficient Dataset Distillation: Matching Convexified Trajectory
Jun 28, 2024The rapid evolution of deep learning and large language models has led to an exponential growth in the demand for training data, prompting the development of Dataset Distillation methods to address the challenges of managing large datasets. Among these, Matching Training Trajectories (MTT) has been a prominent approach, which replicates the training trajectory of an expert network on real data with a synthetic dataset. However, our investigation found that this method suffers from three significant limitations: 1. Instability of expert trajectory generated by Stochastic Gradient Descent (SGD); 2. Low convergence speed of the distillation process; 3. High storage consumption of the expert trajectory. To address these issues, we offer a new perspective on understanding the essence of Dataset Distillation and MTT through a simple transformation of the objective function, and introduce a novel method called Matching Convexified Trajectory (MCT), which aims to provide better guidance for the student trajectory. MCT leverages insights from the linearized dynamics of Neural Tangent Kernel methods to create a convex combination of expert trajectories, guiding the student network to converge rapidly and stably. This trajectory is not only easier to store, but also enables a continuous sampling strategy during distillation, ensuring thorough learning and fitting of the entire expert trajectory. Comprehensive experiments across three public datasets validate the superiority of MCT over traditional MTT methods.
Your decision path does matter in pre-training industrial recommenders with multi-source behaviors
May 27, 2024

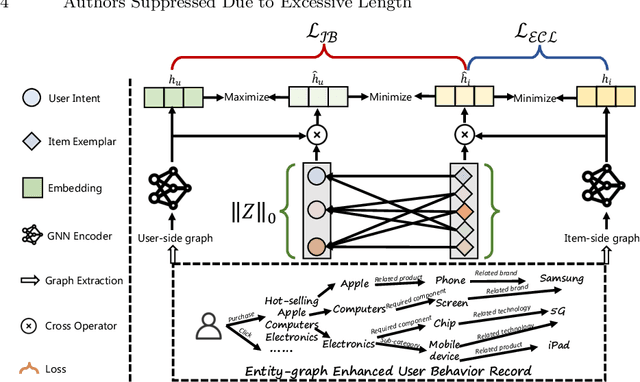

Online service platforms offering a wide range of services through miniapps have become crucial for users who visit these platforms with clear intentions to find services they are interested in. Aiming at effective content delivery, cross-domain recommendation are introduced to learn high-quality representations by transferring behaviors from data-rich scenarios. However, these methods overlook the impact of the decision path that users take when conduct behaviors, that is, users ultimately exhibit different behaviors based on various intents. To this end, we propose HIER, a novel Hierarchical decIsion path Enhanced Representation learning for cross-domain recommendation. With the help of graph neural networks for high-order topological information of the knowledge graph between multi-source behaviors, we further adaptively learn decision paths through well-designed exemplar-level and information bottleneck based contrastive learning. Extensive experiments in online and offline environments show the superiority of HIER.
PathM3: A Multimodal Multi-Task Multiple Instance Learning Framework for Whole Slide Image Classification and Captioning
Mar 13, 2024In the field of computational histopathology, both whole slide images (WSIs) and diagnostic captions provide valuable insights for making diagnostic decisions. However, aligning WSIs with diagnostic captions presents a significant challenge. This difficulty arises from two main factors: 1) Gigapixel WSIs are unsuitable for direct input into deep learning models, and the redundancy and correlation among the patches demand more attention; and 2) Authentic WSI diagnostic captions are extremely limited, making it difficult to train an effective model. To overcome these obstacles, we present PathM3, a multimodal, multi-task, multiple instance learning (MIL) framework for WSI classification and captioning. PathM3 adapts a query-based transformer to effectively align WSIs with diagnostic captions. Given that histopathology visual patterns are redundantly distributed across WSIs, we aggregate each patch feature with MIL method that considers the correlations among instances. Furthermore, our PathM3 overcomes data scarcity in WSI-level captions by leveraging limited WSI diagnostic caption data in the manner of multi-task joint learning. Extensive experiments with improved classification accuracy and caption generation demonstrate the effectiveness of our method on both WSI classification and captioning task.
Towards Efficient Replay in Federated Incremental Learning
Mar 09, 2024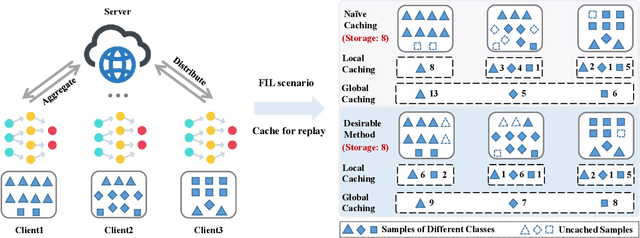

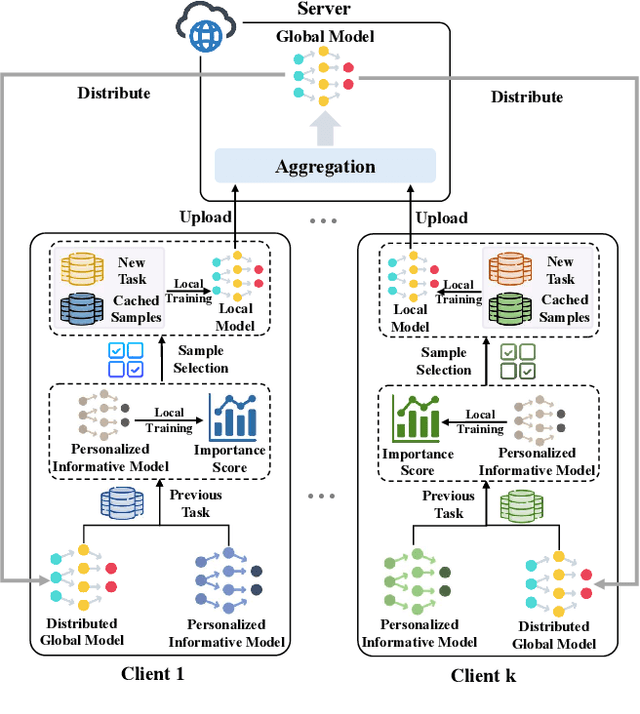

In Federated Learning (FL), the data in each client is typically assumed fixed or static. However, data often comes in an incremental manner in real-world applications, where the data domain may increase dynamically. In this work, we study catastrophic forgetting with data heterogeneity in Federated Incremental Learning (FIL) scenarios where edge clients may lack enough storage space to retain full data. We propose to employ a simple, generic framework for FIL named Re-Fed, which can coordinate each client to cache important samples for replay. More specifically, when a new task arrives, each client first caches selected previous samples based on their global and local importance. Then, the client trains the local model with both the cached samples and the samples from the new task. Theoretically, we analyze the ability of Re-Fed to discover important samples for replay thus alleviating the catastrophic forgetting problem. Moreover, we empirically show that Re-Fed achieves competitive performance compared to state-of-the-art methods.