 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Stable and Storage-efficient Dataset Distillation: Matching Convexified Trajectory
Jun 28, 2024The rapid evolution of deep learning and large language models has led to an exponential growth in the demand for training data, prompting the development of Dataset Distillation methods to address the challenges of managing large datasets. Among these, Matching Training Trajectories (MTT) has been a prominent approach, which replicates the training trajectory of an expert network on real data with a synthetic dataset. However, our investigation found that this method suffers from three significant limitations: 1. Instability of expert trajectory generated by Stochastic Gradient Descent (SGD); 2. Low convergence speed of the distillation process; 3. High storage consumption of the expert trajectory. To address these issues, we offer a new perspective on understanding the essence of Dataset Distillation and MTT through a simple transformation of the objective function, and introduce a novel method called Matching Convexified Trajectory (MCT), which aims to provide better guidance for the student trajectory. MCT leverages insights from the linearized dynamics of Neural Tangent Kernel methods to create a convex combination of expert trajectories, guiding the student network to converge rapidly and stably. This trajectory is not only easier to store, but also enables a continuous sampling strategy during distillation, ensuring thorough learning and fitting of the entire expert trajectory. Comprehensive experiments across three public datasets validate the superiority of MCT over traditional MTT methods.
Watch Your Head: Assembling Projection Heads to Save the Reliability of Federated Models
Feb 26, 2024Federated learning encounters substantial challenges with heterogeneous data, leading to performance degradation and convergence issues. While considerable progress has been achieved in mitigating such an impact, the reliability aspect of federated models has been largely disregarded. In this study, we conduct extensive experiments to investigate the reliability of both generic and personalized federated models. Our exploration uncovers a significant finding: \textbf{federated models exhibit unreliability when faced with heterogeneous data}, demonstrating poor calibration on in-distribution test data and low uncertainty levels on out-of-distribution data. This unreliability is primarily attributed to the presence of biased projection heads, which introduce miscalibration into the federated models. Inspired by this observation, we propose the "Assembled Projection Heads" (APH) method for enhancing the reliability of federated models. By treating the existing projection head parameters as priors, APH randomly samples multiple initialized parameters of projection heads from the prior and further performs targeted fine-tuning on locally available data under varying learning rates. Such a head ensemble introduces parameter diversity into the deterministic model, eliminating the bias and producing reliable predictions via head averaging. We evaluate the effectiveness of the proposed APH method across three prominent federated benchmarks. Experimental results validate the efficacy of APH in model calibration and uncertainty estimation. Notably, APH can be seamlessly integrated into various federated approaches but only requires less than 30\% additional computation cost for 100$\times$ inferences within large models.
Towards Fast and Stable Federated Learning: Confronting Heterogeneity via Knowledge Anchor
Dec 05, 2023Federated learning encounters a critical challenge of data heterogeneity, adversely affecting the performance and convergence of the federated model. Various approaches have been proposed to address this issue, yet their effectiveness is still limited. Recent studies have revealed that the federated model suffers severe forgetting in local training, leading to global forgetting and performance degradation. Although the analysis provides valuable insights, a comprehensive understanding of the vulnerable classes and their impact factors is yet to be established. In this paper, we aim to bridge this gap by systematically analyzing the forgetting degree of each class during local training across different communication rounds. Our observations are: (1) Both missing and non-dominant classes suffer similar severe forgetting during local training, while dominant classes show improvement in performance. (2) When dynamically reducing the sample size of a dominant class, catastrophic forgetting occurs abruptly when the proportion of its samples is below a certain threshold, indicating that the local model struggles to leverage a few samples of a specific class effectively to prevent forgetting. Motivated by these findings, we propose a novel and straightforward algorithm called Federated Knowledge Anchor (FedKA). Assuming that all clients have a single shared sample for each class, the knowledge anchor is constructed before each local training stage by extracting shared samples for missing classes and randomly selecting one sample per class for non-dominant classes. The knowledge anchor is then utilized to correct the gradient of each mini-batch towards the direction of preserving the knowledge of the missing and non-dominant classes. Extensive experimental results demonstrate that our proposed FedKA achieves fast and stable convergence, significantly improving accuracy on popular benchmarks.
Label Information Bottleneck for Label Enhancement
Mar 14, 2023



In this work, we focus on the challenging problem of Label Enhancement (LE), which aims to exactly recover label distributions from logical labels, and present a novel Label Information Bottleneck (LIB) method for LE. For the recovery process of label distributions, the label irrelevant information contained in the dataset may lead to unsatisfactory recovery performance. To address this limitation, we make efforts to excavate the essential label relevant information to improve the recovery performance. Our method formulates the LE problem as the following two joint processes: 1) learning the representation with the essential label relevant information, 2) recovering label distributions based on the learned representation. The label relevant information can be excavated based on the "bottleneck" formed by the learned representation. Significantly, both the label relevant information about the label assignments and the label relevant information about the label gaps can be explored in our method. Evaluation experiments conducted on several benchmark label distribution learning datasets verify the effectiveness and competitiveness of LIB. Our source codes are available https://github.com/qinghai-zheng/LIBLE
Semantically Consistent Multi-view Representation Learning
Mar 08, 2023In this work, we devote ourselves to the challenging task of Unsupervised Multi-view Representation Learning (UMRL), which requires learning a unified feature representation from multiple views in an unsupervised manner. Existing UMRL methods mainly concentrate on the learning process in the feature space while ignoring the valuable semantic information hidden in different views. To address this issue, we propose a novel Semantically Consistent Multi-view Representation Learning (SCMRL), which makes efforts to excavate underlying multi-view semantic consensus information and utilize the information to guide the unified feature representation learning. Specifically, SCMRL consists of a within-view reconstruction module and a unified feature representation learning module, which are elegantly integrated by the contrastive learning strategy to simultaneously align semantic labels of both view-specific feature representations and the learned unified feature representation. In this way, the consensus information in the semantic space can be effectively exploited to constrain the learning process of unified feature representation. Compared with several state-of-the-art algorithms, extensive experiments demonstrate its superiority.
Multi-view Semantic Consistency based Information Bottleneck for Clustering
Feb 28, 2023
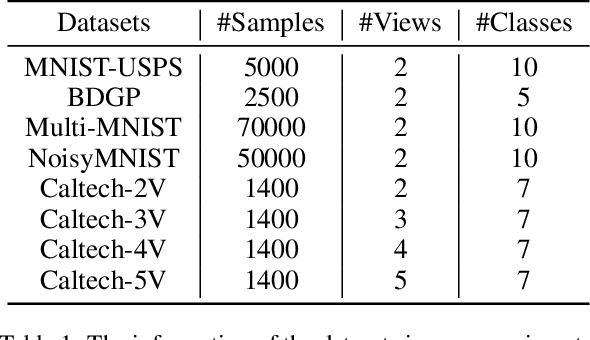

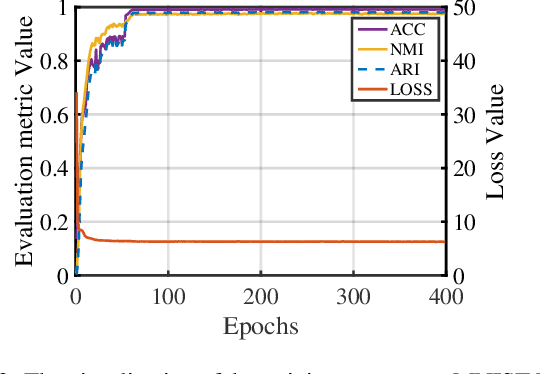
Multi-view clustering can make use of multi-source information for unsupervised clustering. Most existing methods focus on learning a fused representation matrix, while ignoring the influence of private information and noise. To address this limitation, we introduce a novel Multi-view Semantic Consistency based Information Bottleneck for clustering (MSCIB). Specifically, MSCIB pursues semantic consistency to improve the learning process of information bottleneck for different views. It conducts the alignment operation of multiple views in the semantic space and jointly achieves the valuable consistent information of multi-view data. In this way, the learned semantic consistency from multi-view data can improve the information bottleneck to more exactly distinguish the consistent information and learn a unified feature representation with more discriminative consistent information for clustering. Experiments on various types of multi-view datasets show that MSCIB achieves state-of-the-art performance.
MCoCo: Multi-level Consistency Collaborative Multi-view Clustering
Feb 26, 2023



Multi-view clustering can explore consistent information from different views to guide clustering. Most existing works focus on pursuing shallow consistency in the feature space and integrating the information of multiple views into a unified representation for clustering. These methods did not fully consider and explore the consistency in the semantic space. To address this issue, we proposed a novel Multi-level Consistency Collaborative learning framework (MCoCo) for multi-view clustering. Specifically, MCoCo jointly learns cluster assignments of multiple views in feature space and aligns semantic labels of different views in semantic space by contrastive learning. Further, we designed a multi-level consistency collaboration strategy, which utilizes the consistent information of semantic space as a self-supervised signal to collaborate with the cluster assignments in feature space. Thus, different levels of spaces collaborate with each other while achieving their own consistency goals, which makes MCoCo fully mine the consistent information of different views without fusion. Compared with state-of-the-art methods, extensive experiments demonstrate the effectiveness and superiority of our method.
Query-graph with Cross-gating Attention Model for Text-to-Audio Grounding
Jun 27, 2021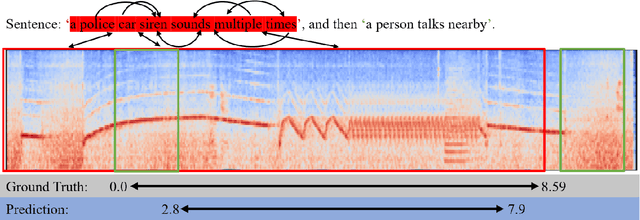



In this paper, we address the text-to-audio grounding issue, namely, grounding the segments of the sound event described by a natural language query in the untrimmed audio. This is a newly proposed but challenging audio-language task, since it requires to not only precisely localize all the on- and off-sets of the desired segments in the audio, but to perform comprehensive acoustic and linguistic understandings and reason the multimodal interactions between the audio and query. To tackle those problems, the existing method treats the query holistically as a single unit by a global query representation, which fails to highlight the keywords that contain rich semantics. Besides, this method has not fully exploited interactions between the query and audio. Moreover, since the audio and queries are arbitrary and variable in length, many meaningless parts of them are not filtered out in this method, which hinders the grounding of the desired segments. To this end, we propose a novel Query Graph with Cross-gating Attention (QGCA) model, which models the comprehensive relations between the words in query through a novel query graph. Besides, to capture the fine-grained interactions between audio and query, a cross-modal attention module that assigns higher weights to the keywords is introduced to generate the snippet-specific query representations. Finally, we also design a cross-gating module to emphasize the crucial parts as well as weaken the irrelevant ones in the audio and query. We extensively evaluate the proposed QGCA model on the public Audiogrounding dataset with significant improvements over several state-of-the-art methods. Moreover, further ablation study shows the consistent effectiveness of different modules in the proposed QGCA model.
Tensor-based Intrinsic Subspace Representation Learning for Multi-view Clustering
Nov 12, 2020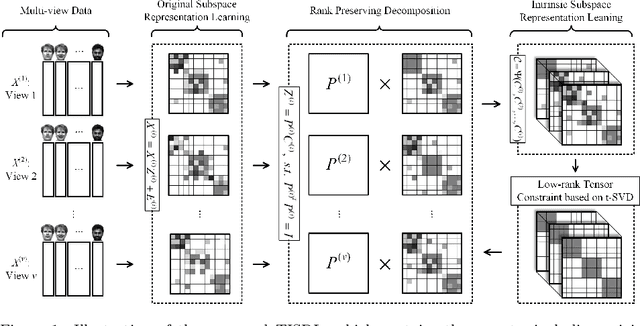

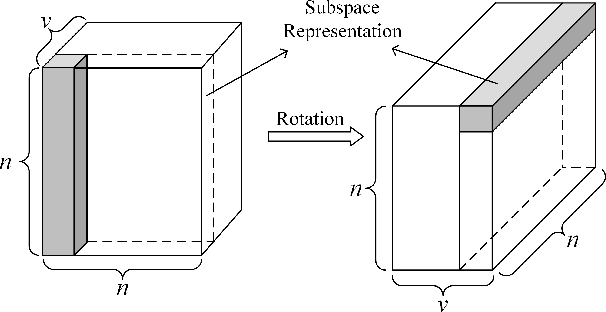
As a hot research topic, many multi-view clustering approaches are proposed over the past few years. Nevertheless, most existing algorithms merely take the consensus information among different views into consideration for clustering. Actually, it may hinder the multi-view clustering performance in real-life applications, since different views usually contain diverse statistic properties. To address this problem, we propose a novel Tensor-based Intrinsic Subspace Representation Learning (TISRL) for multi-view clustering in this paper. Concretely, the rank preserving decomposition is proposed firstly to effectively deal with the diverse statistic information contained in different views. Then, to achieve the intrinsic subspace representation, the tensor-singular value decomposition based low-rank tensor constraint is also utilized in our method. It can be seen that specific information contained in different views is fully investigated by the rank preserving decomposition, and the high-order correlations of multi-view data are also mined by the low-rank tensor constraint. The objective function can be optimized by an augmented Lagrangian multiplier based alternating direction minimization algorithm. Experimental results on nine common used real-world multi-view datasets illustrate the superiority of TISRL.
Multi-view Subspace Clustering Networks with Local and Global Graph Information
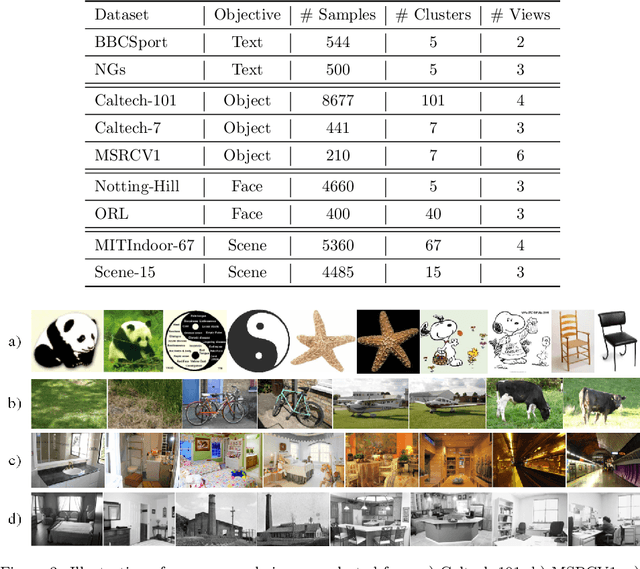
Oct 24, 2020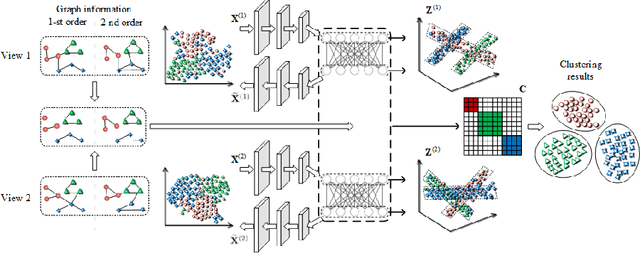
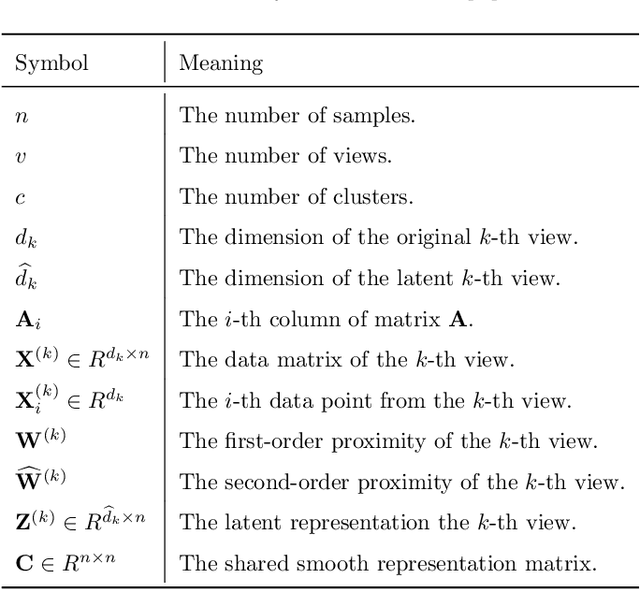
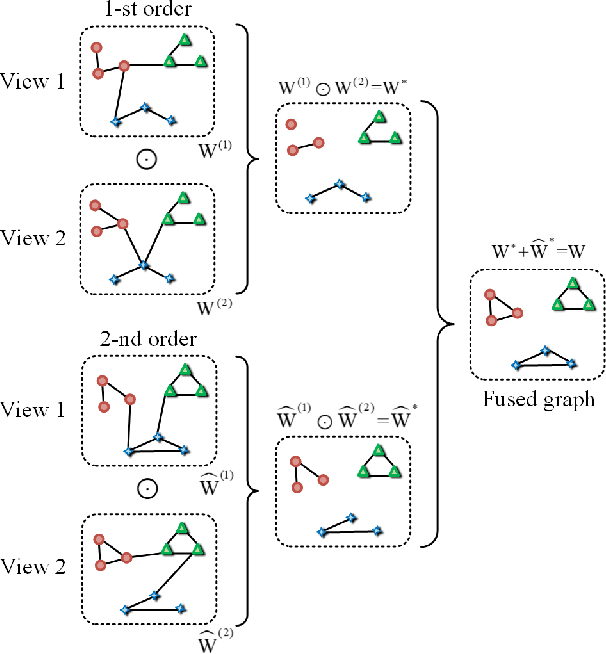
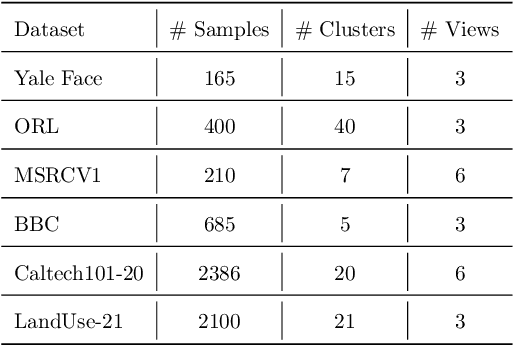
This study investigates the problem of multi-view subspace clustering, the goal of which is to explore the underlying grouping structure of data collected from different fields or measurements. Since data do not always comply with the linear subspace models in many real-world applications, most existing multi-view subspace clustering methods that based on the shallow linear subspace models may fail in practice. Furthermore, underlying graph information of multi-view data is always ignored in most existing multi-view subspace clustering methods. To address aforementioned limitations, we proposed the novel multi-view subspace clustering networks with local and global graph information, termed MSCNLG, in this paper. Specifically, autoencoder networks are employed on multiple views to achieve latent smooth representations that are suitable for the linear assumption. Simultaneously, by integrating fused multi-view graph information into self-expressive layers, the proposed MSCNLG obtains the common shared multi-view subspace representation, which can be used to get clustering results by employing the standard spectral clustering algorithm. As an end-to-end trainable framework, the proposed method fully investigates the valuable information of multiple views. Comprehensive experiments on six benchmark datasets validate the effectiveness and superiority of the proposed MSCNLG.