 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFBS:Buffer Gradient Selection in Semi-asynchronous Federated Learning
Jun 15, 2025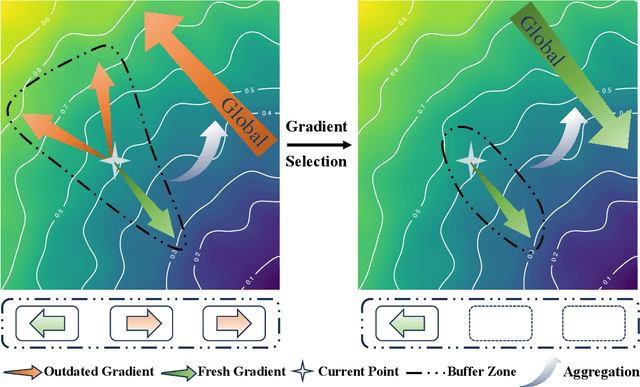



Asynchronous federated learning (AFL) accelerates training by eliminating the need to wait for stragglers, but its asynchronous nature introduces gradient staleness, where outdated gradients degrade performance. Existing solutions address this issue with gradient buffers, forming a semi-asynchronous framework. However, this approach struggles when buffers accumulate numerous stale gradients, as blindly aggregating all gradients can harm training. To address this, we propose AFBS (Asynchronous FL Buffer Selection), the first algorithm to perform gradient selection within buffers while ensuring privacy protection. Specifically, the client sends the random projection encrypted label distribution matrix before training, and the server performs client clustering based on it. During training, server scores and selects gradients within each cluster based on their informational value, discarding low-value gradients to enhance semi-asynchronous federated learning. Extensive experiments in highly heterogeneous system and data environments demonstrate AFBS's superior performance compared to state-of-the-art methods. Notably, on the most challenging task, CIFAR-100, AFBS improves accuracy by up to 4.8% over the previous best algorithm and reduces the time to reach target accuracy by 75%.
HFedCKD: Toward Robust Heterogeneous Federated Learning via Data-free Knowledge Distillation and Two-way Contrast
Mar 09, 2025Most current federated learning frameworks are modeled as static processes, ignoring the dynamic characteristics of the learning system. Under the limited communication budget of the central server, the flexible model architecture of a large number of clients participating in knowledge transfer requires a lower participation rate, active clients have uneven contributions, and the client scale seriously hinders the performance of FL. We consider a more general and practical federation scenario and propose a system heterogeneous federation method based on data-free knowledge distillation and two-way contrast (HFedCKD). We apply the Inverse Probability Weighted Distillation (IPWD) strategy to the data-free knowledge transfer framework. The generator completes the data features of the nonparticipating clients. IPWD implements a dynamic evaluation of the prediction contribution of each client under different data distributions. Based on the antibiased weighting of its prediction loss, the weight distribution of each client is effectively adjusted to fairly integrate the knowledge of participating clients. At the same time, the local model is split into a feature extractor and a classifier. Through differential contrast learning, the feature extractor is aligned with the global model in the feature space, while the classifier maintains personalized decision-making capabilities. HFedCKD effectively alleviates the knowledge offset caused by a low participation rate under data-free knowledge distillation and improves the performance and stability of the model. We conduct extensive experiments on image and IoT datasets to comprehensively evaluate and verify the generalization and robustness of the proposed HFedCKD framework.
TPFL: A Trustworthy Personalized Federated Learning Framework via Subjective Logic
Oct 16, 2024Federated learning (FL) enables collaborative model training across distributed clients while preserving data privacy. Despite its widespread adoption, most FL approaches focusing solely on privacy protection fall short in scenarios where trustworthiness is crucial, necessitating advancements in secure training, dependable decision-making mechanisms, robustness on corruptions, and enhanced performance with Non-IID data. To bridge this gap, we introduce Trustworthy Personalized Federated Learning (TPFL) framework designed for classification tasks via subjective logic in this paper. Specifically, TPFL adopts a unique approach by employing subjective logic to construct federated models, providing probabilistic decisions coupled with an assessment of uncertainty rather than mere probability assignments. By incorporating a trainable heterogeneity prior to the local training phase, TPFL effectively mitigates the adverse effects of data heterogeneity. Model uncertainty and instance uncertainty are further utilized to ensure the safety and reliability of the training and inference stages. Through extensive experiments on widely recognized federated learning benchmarks, we demonstrate that TPFL not only achieves competitive performance compared with advanced methods but also exhibits resilience against prevalent malicious attacks, robustness on domain shifts, and reliability in high-stake scenarios.
Watch Your Head: Assembling Projection Heads to Save the Reliability of Federated Models
Feb 26, 2024Federated learning encounters substantial challenges with heterogeneous data, leading to performance degradation and convergence issues. While considerable progress has been achieved in mitigating such an impact, the reliability aspect of federated models has been largely disregarded. In this study, we conduct extensive experiments to investigate the reliability of both generic and personalized federated models. Our exploration uncovers a significant finding: \textbf{federated models exhibit unreliability when faced with heterogeneous data}, demonstrating poor calibration on in-distribution test data and low uncertainty levels on out-of-distribution data. This unreliability is primarily attributed to the presence of biased projection heads, which introduce miscalibration into the federated models. Inspired by this observation, we propose the "Assembled Projection Heads" (APH) method for enhancing the reliability of federated models. By treating the existing projection head parameters as priors, APH randomly samples multiple initialized parameters of projection heads from the prior and further performs targeted fine-tuning on locally available data under varying learning rates. Such a head ensemble introduces parameter diversity into the deterministic model, eliminating the bias and producing reliable predictions via head averaging. We evaluate the effectiveness of the proposed APH method across three prominent federated benchmarks. Experimental results validate the efficacy of APH in model calibration and uncertainty estimation. Notably, APH can be seamlessly integrated into various federated approaches but only requires less than 30\% additional computation cost for 100$\times$ inferences within large models.
Towards Fast and Stable Federated Learning: Confronting Heterogeneity via Knowledge Anchor
Dec 05, 2023Federated learning encounters a critical challenge of data heterogeneity, adversely affecting the performance and convergence of the federated model. Various approaches have been proposed to address this issue, yet their effectiveness is still limited. Recent studies have revealed that the federated model suffers severe forgetting in local training, leading to global forgetting and performance degradation. Although the analysis provides valuable insights, a comprehensive understanding of the vulnerable classes and their impact factors is yet to be established. In this paper, we aim to bridge this gap by systematically analyzing the forgetting degree of each class during local training across different communication rounds. Our observations are: (1) Both missing and non-dominant classes suffer similar severe forgetting during local training, while dominant classes show improvement in performance. (2) When dynamically reducing the sample size of a dominant class, catastrophic forgetting occurs abruptly when the proportion of its samples is below a certain threshold, indicating that the local model struggles to leverage a few samples of a specific class effectively to prevent forgetting. Motivated by these findings, we propose a novel and straightforward algorithm called Federated Knowledge Anchor (FedKA). Assuming that all clients have a single shared sample for each class, the knowledge anchor is constructed before each local training stage by extracting shared samples for missing classes and randomly selecting one sample per class for non-dominant classes. The knowledge anchor is then utilized to correct the gradient of each mini-batch towards the direction of preserving the knowledge of the missing and non-dominant classes. Extensive experimental results demonstrate that our proposed FedKA achieves fast and stable convergence, significantly improving accuracy on popular benchmarks.