 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Principled Learning for Re-ranking in Recommender Systems
Apr 05, 2025



As the final stage of recommender systems, re-ranking presents ordered item lists to users that best match their interests. It plays such a critical role and has become a trending research topic with much attention from both academia and industry. Recent advances of re-ranking are focused on attentive listwise modeling of interactions and mutual influences among items to be re-ranked. However, principles to guide the learning process of a re-ranker, and to measure the quality of the output of the re-ranker, have been always missing. In this paper, we study such principles to learn a good re-ranker. Two principles are proposed, including convergence consistency and adversarial consistency. These two principles can be applied in the learning of a generic re-ranker and improve its performance. We validate such a finding by various baseline methods over different datasets.
RNE: A Scalable Network Embedding for Billion-scale Recommendation
Apr 09, 2020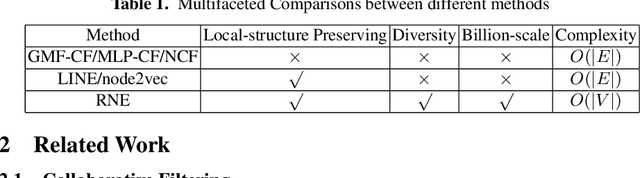
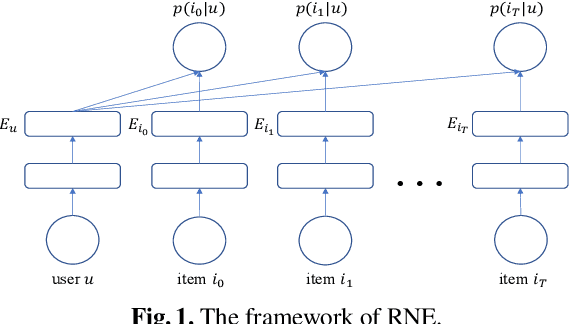


Nowadays designing a real recommendation system has been a critical problem for both academic and industry. However, due to the huge number of users and items, the diversity and dynamic property of the user interest, how to design a scalable recommendation system, which is able to efficiently produce effective and diverse recommendation results on billion-scale scenarios, is still a challenging and open problem for existing methods. In this paper, given the user-item interaction graph, we propose RNE, a data-efficient Recommendation-based Network Embedding method, to give personalized and diverse items to users. Specifically, we propose a diversity- and dynamics-aware neighbor sampling method for network embedding. On the one hand, the method is able to preserve the local structure between the users and items while modeling the diversity and dynamic property of the user interest to boost the recommendation quality. On the other hand the sampling method can reduce the complexity of the whole method theoretically to make it possible for billion-scale recommendation. We also implement the designed algorithm in a distributed way to further improves its scalability. Experimentally, we deploy RNE on a recommendation scenario of Taobao, the largest E-commerce platform in China, and train it on a billion-scale user-item graph. As is shown on several online metrics on A/B testing, RNE is able to achieve both high-quality and diverse results compared with CF-based methods. We also conduct the offline experiments on Pinterest dataset comparing with several state-of-the-art recommendation methods and network embedding methods. The results demonstrate that our method is able to produce a good result while runs much faster than the baseline methods.
NetDP: An Industrial-Scale Distributed Network Representation Framework for Default Prediction in Ant Credit Pay
Apr 01, 2020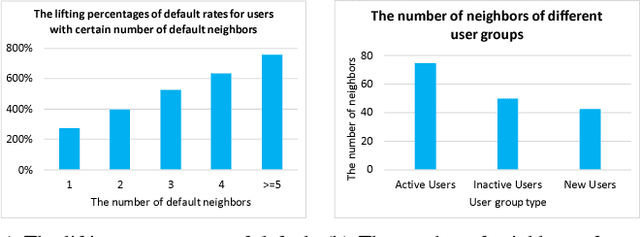
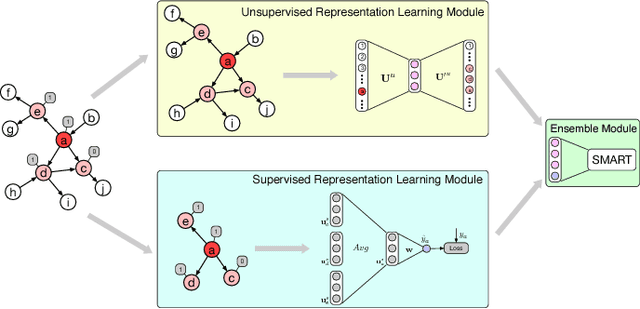

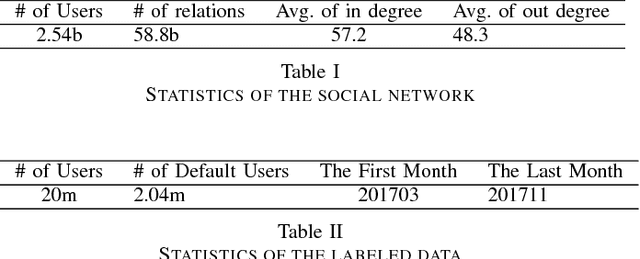
Ant Credit Pay is a consumer credit service in Ant Financial Service Group. Similar to credit card, loan default is one of the major risks of this credit product. Hence, effective algorithm for default prediction is the key to losses reduction and profits increment for the company. However, the challenges facing in our scenario are different from those in conventional credit card service. The first one is scalability. The huge volume of users and their behaviors in Ant Financial requires the ability to process industrial-scale data and perform model training efficiently. The second challenges is the cold-start problem. Different from the manual review for credit card application in conventional banks, the credit limit of Ant Credit Pay is automatically offered to users based on the knowledge learned from big data. However, default prediction for new users is suffered from lack of enough credit behaviors. It requires that the proposal should leverage other new data source to alleviate the cold-start problem. Considering the above challenges and the special scenario in Ant Financial, we try to incorporate default prediction with network information to alleviate the cold-start problem. In this paper, we propose an industrial-scale distributed network representation framework, termed NetDP, for default prediction in Ant Credit Pay. The proposal explores network information generated by various interaction between users, and blends unsupervised and supervised network representation in a unified framework for default prediction problem. Moreover, we present a parameter-server-based distributed implement of our proposal to handle the scalability challenge. Experimental results demonstrate the effectiveness of our proposal, especially in cold-start problem, as well as the efficiency for industrial-scale dataset.
InfDetect: a Large Scale Graph-based Fraud Detection System for E-Commerce Insurance
Mar 12, 2020
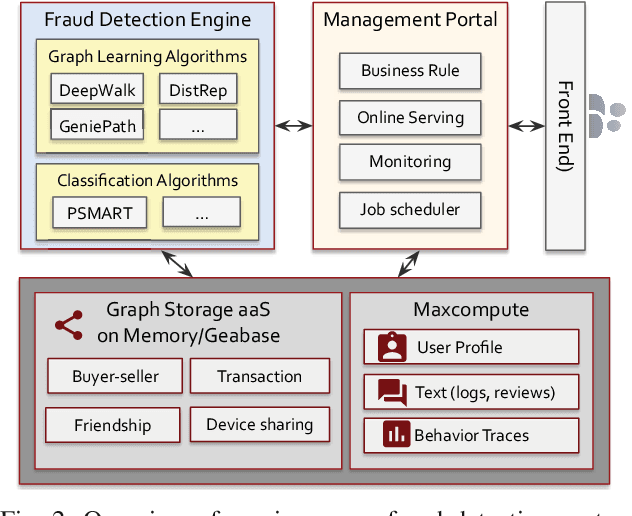
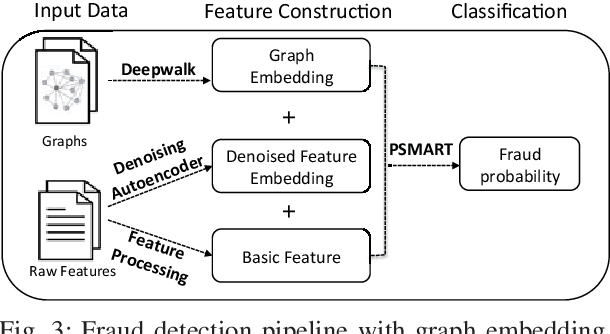

The insurance industry has been creating innovative products around the emerging online shopping activities. Such e-commerce insurance is designed to protect buyers from potential risks such as impulse purchases and counterfeits. Fraudulent claims towards online insurance typically involve multiple parties such as buyers, sellers, and express companies, and they could lead to heavy financial losses. In order to uncover the relations behind organized fraudsters and detect fraudulent claims, we developed a large-scale insurance fraud detection system, i.e., InfDetect, which provides interfaces for commonly used graphs, standard data processing procedures, and a uniform graph learning platform. InfDetect is able to process big graphs containing up to 100 millions of nodes and billions of edges. In this paper, we investigate different graphs to facilitate fraudster mining, such as a device-sharing graph, a transaction graph, a friendship graph, and a buyer-seller graph. These graphs are fed to a uniform graph learning platform containing supervised and unsupervised graph learning algorithms. Cases on widely applied e-commerce insurance are described to demonstrate the usage and capability of our system. InfDetect has successfully detected thousands of fraudulent claims and saved over tens of thousands of dollars daily.
Generating Natural Language Adversarial Examples on a Large Scale with Generative Models
Mar 10, 2020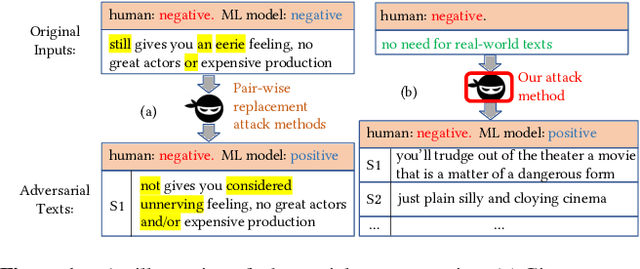

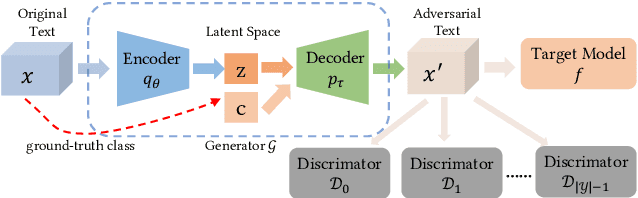

Today text classification models have been widely used. However, these classifiers are found to be easily fooled by adversarial examples. Fortunately, standard attacking methods generate adversarial texts in a pair-wise way, that is, an adversarial text can only be created from a real-world text by replacing a few words. In many applications, these texts are limited in numbers, therefore their corresponding adversarial examples are often not diverse enough and sometimes hard to read, thus can be easily detected by humans and cannot create chaos at a large scale. In this paper, we propose an end to end solution to efficiently generate adversarial texts from scratch using generative models, which are not restricted to perturbing the given texts. We call it unrestricted adversarial text generation. Specifically, we train a conditional variational autoencoder (VAE) with an additional adversarial loss to guide the generation of adversarial examples. Moreover, to improve the validity of adversarial texts, we utilize discrimators and the training framework of generative adversarial networks (GANs) to make adversarial texts consistent with real data. Experimental results on sentiment analysis demonstrate the scalability and efficiency of our method. It can attack text classification models with a higher success rate than existing methods, and provide acceptable quality for humans in the meantime.
A Semi-supervised Graph Attentive Network for Financial Fraud Detection
Feb 28, 2020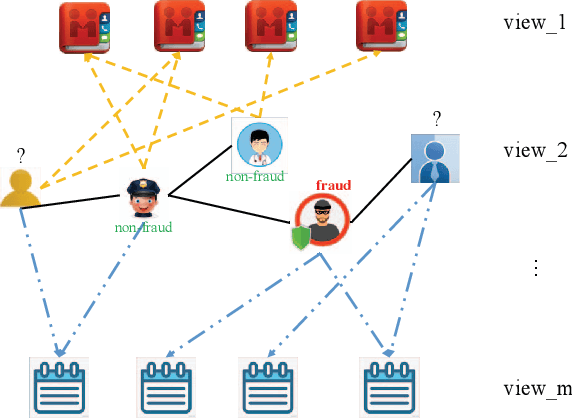
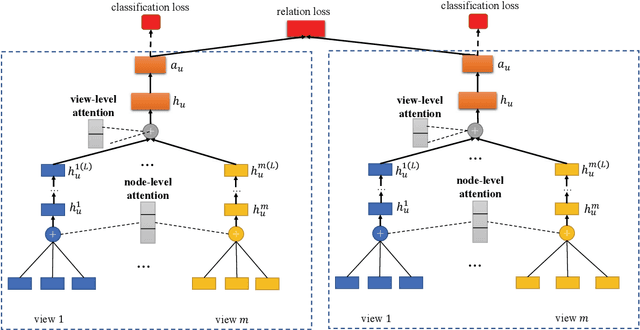
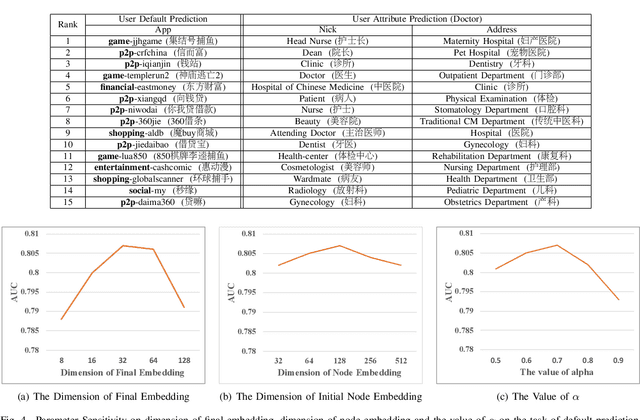

With the rapid growth of financial services, fraud detection has been a very important problem to guarantee a healthy environment for both users and providers. Conventional solutions for fraud detection mainly use some rule-based methods or distract some features manually to perform prediction. However, in financial services, users have rich interactions and they themselves always show multifaceted information. These data form a large multiview network, which is not fully exploited by conventional methods. Additionally, among the network, only very few of the users are labelled, which also poses a great challenge for only utilizing labeled data to achieve a satisfied performance on fraud detection. To address the problem, we expand the labeled data through their social relations to get the unlabeled data and propose a semi-supervised attentive graph neural network, namedSemiGNN to utilize the multi-view labeled and unlabeled data for fraud detection. Moreover, we propose a hierarchical attention mechanism to better correlate different neighbors and different views. Simultaneously, the attention mechanism can make the model interpretable and tell what are the important factors for the fraud and why the users are predicted as fraud. Experimentally, we conduct the prediction task on the users of Alipay, one of the largest third-party online and offline cashless payment platform serving more than 4 hundreds of million users in China. By utilizing the social relations and the user attributes, our method can achieve a better accuracy compared with the state-of-the-art methods on two tasks. Moreover, the interpretable results also give interesting intuitions regarding the tasks.