 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Indexing Internet Search Augmented Generation for Large Language Models
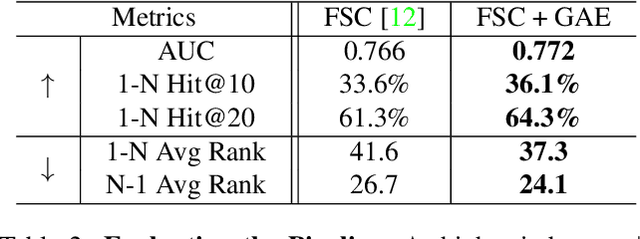
Nov 29, 2024Retrieval augmented generation has emerged as an effective method to enhance large language model performance. This approach typically relies on an internal retrieval module that uses various indexing mechanisms to manage a static pre-processed corpus. However, such a paradigm often falls short when it is necessary to integrate the most up-to-date information that has not been updated into the corpus during generative inference time. In this paper, we explore an alternative approach that leverages standard search engine APIs to dynamically integrate the latest online information (without maintaining any index for any fixed corpus), thereby improving the quality of generated content. We design a collaborative LLM-based paradigm, where we include: (i) a parser-LLM that determines if the Internet augmented generation is demanded and extracts the search keywords if so with a single inference; (ii) a mixed ranking strategy that re-ranks the retrieved HTML files to eliminate bias introduced from the search engine API; and (iii) an extractor-LLM that can accurately and efficiently extract relevant information from the fresh content in each HTML file. We conduct extensive empirical studies to evaluate the performance of this Internet search augmented generation paradigm. The experimental results demonstrate that our method generates content with significantly improved quality. Our system has been successfully deployed in a production environment to serve 01.AI's generative inference requests.
3D Scene Creation and Rendering via Rough Meshes: A Lighting Transfer Avenue
Dec 04, 2022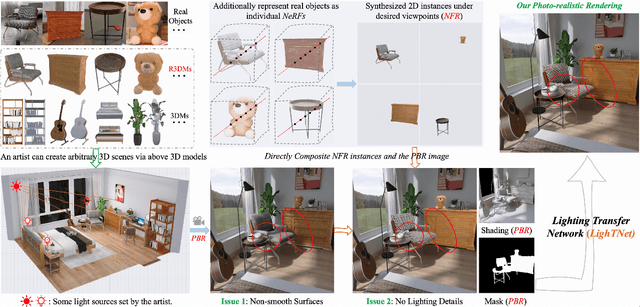



This paper studies how to flexibly integrate reconstructed 3D models into practical 3D modeling pipelines such as 3D scene creation and rendering. Due to the technical difficulty, one can only obtain rough 3D models (R3DMs) for most real objects using existing 3D reconstruction techniques. As a result, physically-based rendering (PBR) would render low-quality images or videos for scenes that are constructed by R3DMs. One promising solution would be representing real-world objects as Neural Fields such as NeRFs, which are able to generate photo-realistic renderings of an object under desired viewpoints. However, a drawback is that the synthesized views through Neural Fields Rendering (NFR) cannot reflect the simulated lighting details on R3DMs in PBR pipelines, especially when object interactions in the 3D scene creation cause local shadows. To solve this dilemma, we propose a lighting transfer network (LighTNet) to bridge NFR and PBR, such that they can benefit from each other. LighTNet reasons about a simplified image composition model, remedies the uneven surface issue caused by R3DMs, and is empowered by several perceptual-motivated constraints and a new Lab angle loss which enhances the contrast between lighting strength and colors. Comparisons demonstrate that LighTNet is superior in synthesizing impressive lighting, and is promising in pushing NFR further in practical 3D modeling workflows. Project page: https://3d-front-future.github.io/LighTNet .
DCCF: Deep Comprehensible Color Filter Learning Framework for High-Resolution Image Harmonization
Jul 13, 2022

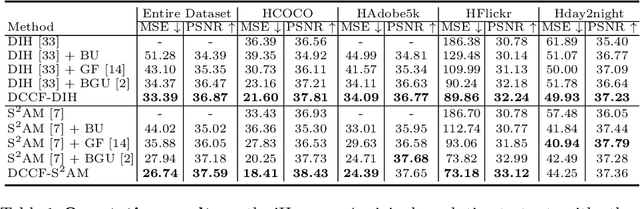
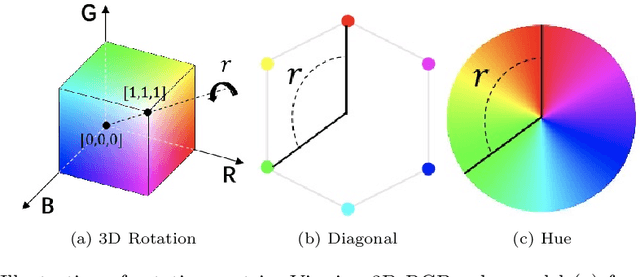
Image color harmonization algorithm aims to automatically match the color distribution of foreground and background images captured in different conditions. Previous deep learning based models neglect two issues that are critical for practical applications, namely high resolution (HR) image processing and model comprehensibility. In this paper, we propose a novel Deep Comprehensible Color Filter (DCCF) learning framework for high-resolution image harmonization. Specifically, DCCF first downsamples the original input image to its low-resolution (LR) counter-part, then learns four human comprehensible neural filters (i.e. hue, saturation, value and attentive rendering filters) in an end-to-end manner, finally applies these filters to the original input image to get the harmonized result. Benefiting from the comprehensible neural filters, we could provide a simple yet efficient handler for users to cooperate with deep model to get the desired results with very little effort when necessary. Extensive experiments demonstrate the effectiveness of DCCF learning framework and it outperforms state-of-the-art post-processing method on iHarmony4 dataset on images' full-resolutions by achieving 7.63% and 1.69% relative improvements on MSE and PSNR respectively.
Ray Priors through Reprojection: Improving Neural Radiance Fields for Novel View Extrapolation
May 12, 2022
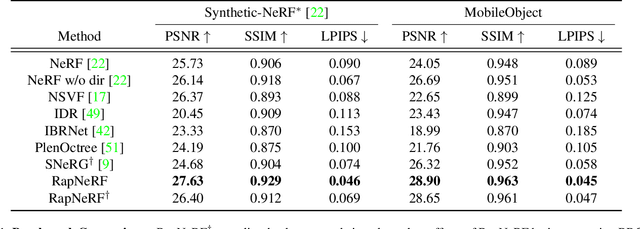
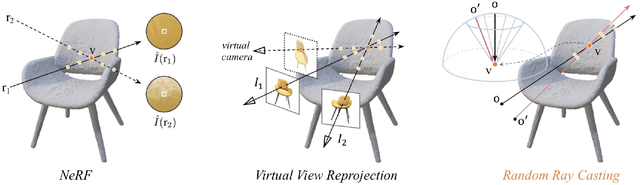
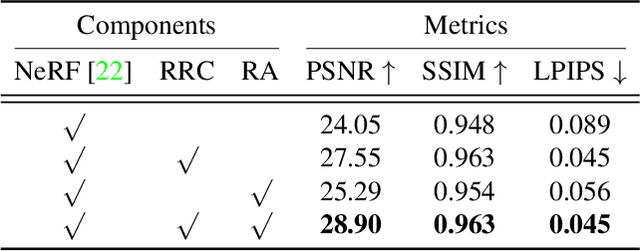
Neural Radiance Fields (NeRF) have emerged as a potent paradigm for representing scenes and synthesizing photo-realistic images. A main limitation of conventional NeRFs is that they often fail to produce high-quality renderings under novel viewpoints that are significantly different from the training viewpoints. In this paper, instead of exploiting few-shot image synthesis, we study the novel view extrapolation setting that (1) the training images can well describe an object, and (2) there is a notable discrepancy between the training and test viewpoints' distributions. We present RapNeRF (RAy Priors) as a solution. Our insight is that the inherent appearances of a 3D surface's arbitrary visible projections should be consistent. We thus propose a random ray casting policy that allows training unseen views using seen views. Furthermore, we show that a ray atlas pre-computed from the observed rays' viewing directions could further enhance the rendering quality for extrapolated views. A main limitation is that RapNeRF would remove the strong view-dependent effects because it leverages the multi-view consistency property.
MAMDR: A Model Agnostic Learning Method for Multi-Domain Recommendation
Mar 22, 2022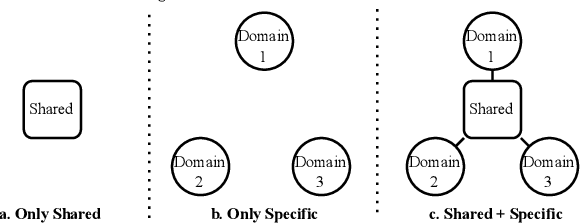
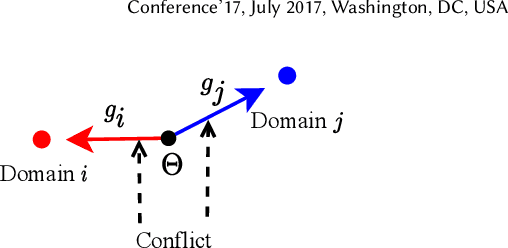
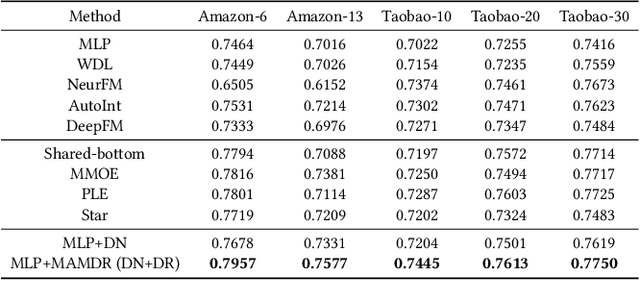
Large-scale e-commercial platforms in the real-world usually contain various recommendation scenarios (domains) to meet demands of diverse customer groups. Multi-Domain Recommendation (MDR), which aims to jointly improve recommendations on all domains, has attracted increasing attention from practitioners and researchers. Existing MDR methods often employ a shared structure to leverage reusable features for all domains and several specific parts to capture domain-specific information. However, data from different domains may conflict with each other and cause shared parameters to stay at a compromised position on the optimization landscape. This could deteriorate the overall performance. Despite the specific parameters are separately learned for each domain, they can easily overfit on data sparsity domains. Furthermore, data distribution differs across domains, making it challenging to develop a general model that can be applied to all circumstances. To address these problems, we propose a novel model agnostic learning method, namely MAMDR, for the multi-domain recommendation. Specifically, we first propose a Domain Negotiation (DN) strategy to alleviate the conflict between domains and learn better shared parameters. Then, we develop a Domain Regularization (DR) scheme to improve the generalization ability of specific parameters by learning from other domains. Finally, we integrate these components into a unified framework and present MAMDR which can be applied to any model structure to perform multi-domain recommendation. Extensive experiments on various real-world datasets and online applications demonstrate both the effectiveness and generalizability of MAMDR.
Exploiting Diverse Characteristics and Adversarial Ambivalence for Domain Adaptive Segmentation
Jan 07, 2021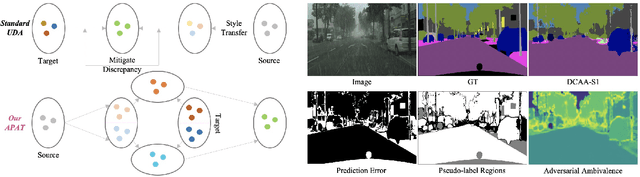
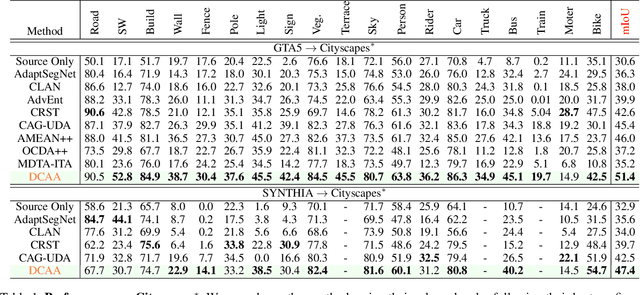
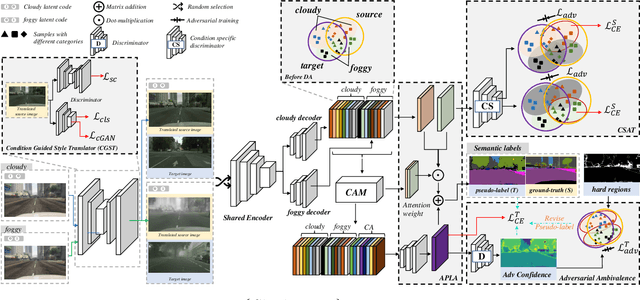
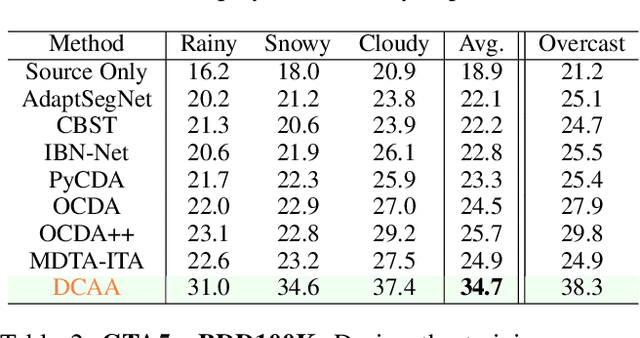
Adapting semantic segmentation models to new domains is an important but challenging problem. Recently enlightening progress has been made, but the performance of existing methods are unsatisfactory on real datasets where the new target domain comprises of heterogeneous sub-domains (e.g., diverse weather characteristics). We point out that carefully reasoning about the multiple modalities in the target domain can improve the robustness of adaptation models. To this end, we propose a condition-guided adaptation framework that is empowered by a special attentive progressive adversarial training (APAT) mechanism and a novel self-training policy. The APAT strategy progressively performs condition-specific alignment and attentive global feature matching. The new self-training scheme exploits the adversarial ambivalences of easy and hard adaptation regions and the correlations among target sub-domains effectively. We evaluate our method (DCAA) on various adaptation scenarios where the target images vary in weather conditions. The comparisons against baselines and the state-of-the-art approaches demonstrate the superiority of DCAA over the competitors.
3D-FRONT: 3D Furnished Rooms with layOuts and semaNTics
Nov 18, 2020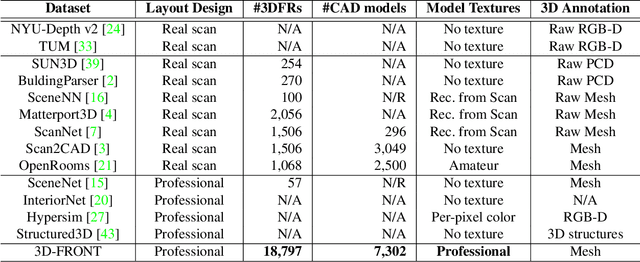
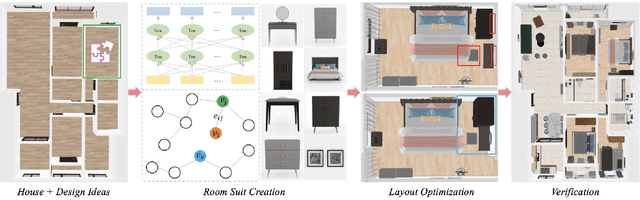
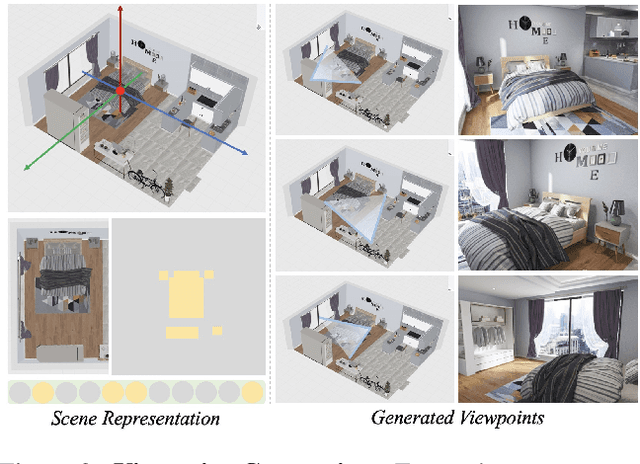
We introduce 3D-FRONT (3D Furnished Rooms with layOuts and semaNTics), a new, large-scale, and comprehensive repository of synthetic indoor scenes highlighted by professionally designed layouts and a large number of rooms populated by high-quality textured 3D models with style compatibility. From layout semantics down to texture details of individual objects, our dataset is freely available to the academic community and beyond. Currently, 3D-FRONT contains 18,797 rooms diversely furnished by 3D objects, far surpassing all publicly available scene datasets. In addition, the 7,302 furniture objects all come with high-quality textures. While the floorplans and layout designs are directly sourced from professional creations, the interior designs in terms of furniture styles, color, and textures have been carefully curated based on a recommender system we develop to attain consistent styles as expert designs. Furthermore, we release Trescope, a light-weight rendering tool, to support benchmark rendering of 2D images and annotations from 3D-FRONT. We demonstrate two applications, interior scene synthesis and texture synthesis, that are especially tailored to the strengths of our new dataset. The project page is at: https://tianchi.aliyun.com/specials/promotion/alibaba-3d-scene-dataset.
Hard Example Generation by Texture Synthesis for Cross-domain Shape Similarity Learning
Oct 27, 2020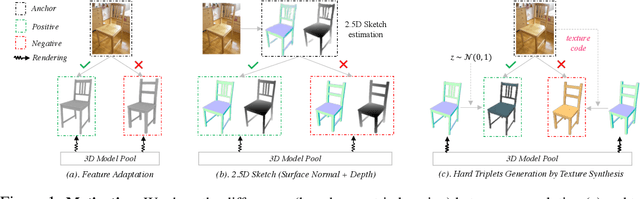
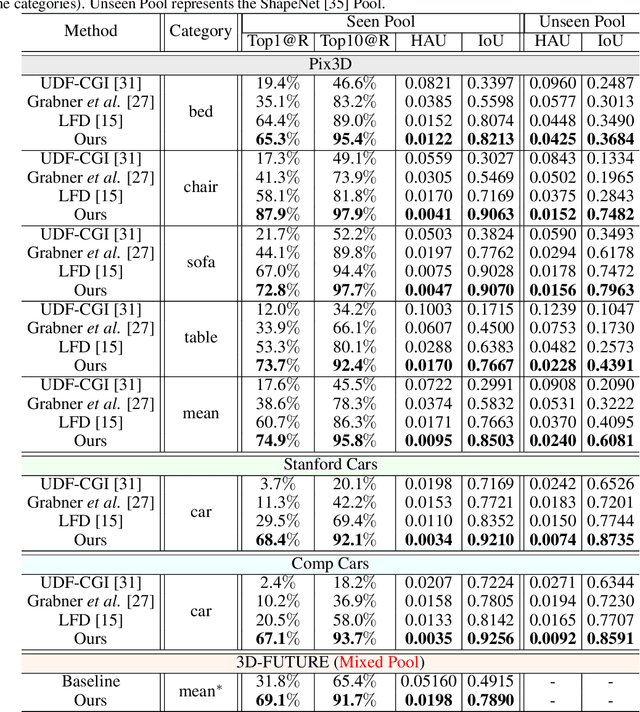
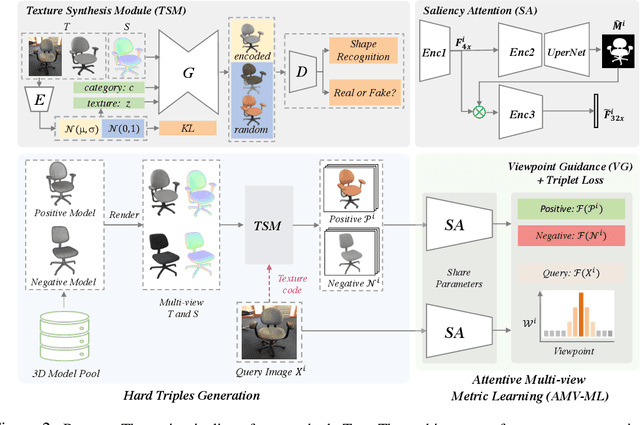
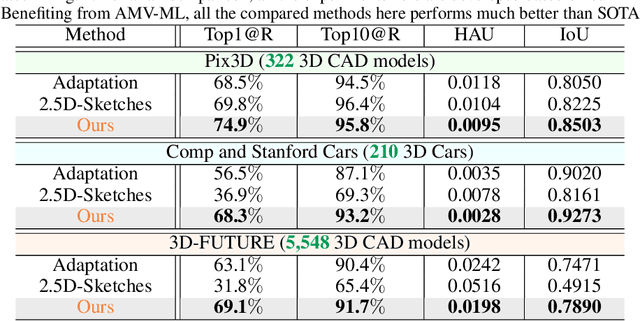
Image-based 3D shape retrieval (IBSR) aims to find the corresponding 3D shape of a given 2D image from a large 3D shape database. The common routine is to map 2D images and 3D shapes into an embedding space and define (or learn) a shape similarity measure. While metric learning with some adaptation techniques seems to be a natural solution to shape similarity learning, the performance is often unsatisfactory for fine-grained shape retrieval. In the paper, we identify the source of the poor performance and propose a practical solution to this problem. We find that the shape difference between a negative pair is entangled with the texture gap, making metric learning ineffective in pushing away negative pairs. To tackle this issue, we develop a geometry-focused multi-view metric learning framework empowered by texture synthesis. The synthesis of textures for 3D shape models creates hard triplets, which suppress the adverse effects of rich texture in 2D images, thereby push the network to focus more on discovering geometric characteristics. Our approach shows state-of-the-art performance on a recently released large-scale 3D-FUTURE[1] repository, as well as three widely studied benchmarks, including Pix3D[2], Stanford Cars[3], and Comp Cars[4]. Codes will be made publicly available at: https://github.com/3D-FRONT-FUTURE/IBSR-texture
3D-FUTURE: 3D Furniture shape with TextURE
Sep 21, 2020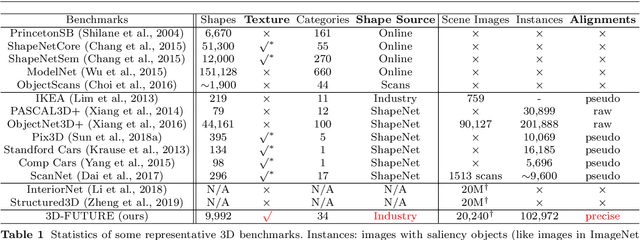
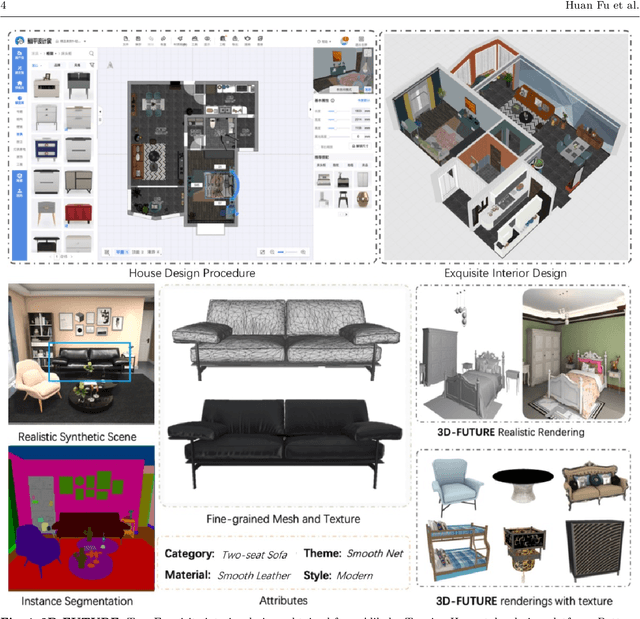
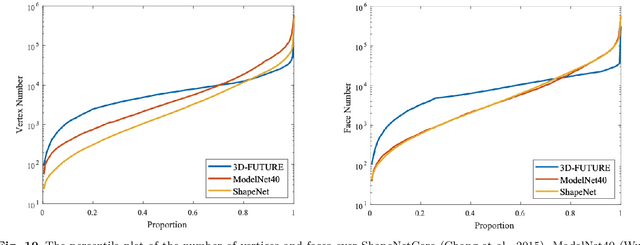
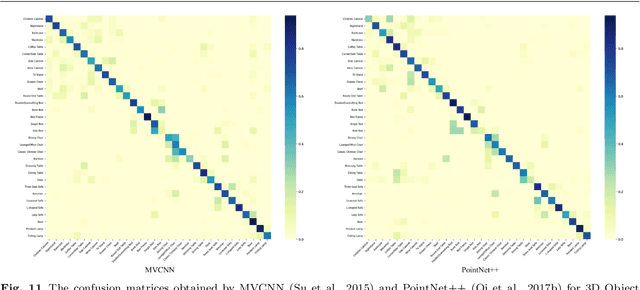
The 3D CAD shapes in current 3D benchmarks are mostly collected from online model repositories. Thus, they typically have insufficient geometric details and less informative textures, making them less attractive for comprehensive and subtle research in areas such as high-quality 3D mesh and texture recovery. This paper presents 3D Furniture shape with TextURE (3D-FUTURE): a richly-annotated and large-scale repository of 3D furniture shapes in the household scenario. At the time of this technical report, 3D-FUTURE contains 20,240 clean and realistic synthetic images of 5,000 different rooms. There are 9,992 unique detailed 3D instances of furniture with high-resolution textures. Experienced designers developed the room scenes, and the 3D CAD shapes in the scene are used for industrial production. Given the well-organized 3D-FUTURE, we provide baseline experiments on several widely studied tasks, such as joint 2D instance segmentation and 3D object pose estimation, image-based 3D shape retrieval, 3D object reconstruction from a single image, and texture recovery for 3D shapes, to facilitate related future researches on our database.
TPG-DNN: A Method for User Intent Prediction Based on Total Probability Formula and GRU Loss with Multi-task Learning
Aug 05, 2020

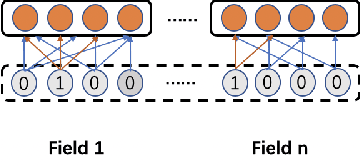

The E-commerce platform has become the principal battleground where people search, browse and pay for whatever they want. Critical as is to improve the online shopping experience for customers and merchants, how to find a proper approach for user intent prediction are paid great attention in both industry and academia. In this paper, we propose a novel user intent prediction model, TPG-DNN, to complete the challenging task, which is based on adaptive gated recurrent unit (GRU) loss function with multi-task learning. We creatively use the GRU structure and total probability formula as the loss function to model the users' whole online purchase process. Besides, the multi-task weight adjustment mechanism can make the final loss function dynamically adjust the importance between different tasks through data variance. According to the test result of experiments conducted on Taobao daily and promotion data sets, the proposed model performs much better than existing click through rate (CTR) models. At present, the proposed user intent prediction model has been widely used for the coupon allocation, advertisement and recommendation on Taobao platform, which greatly improve the user experience and shopping efficiency, and benefit the gross merchandise volume (GMV) promotion as well.