 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Multi-Objective Bayesian Optimization with Scalable Batch Evaluations for Sample-Efficient De Novo Molecular Design
Dec 19, 2025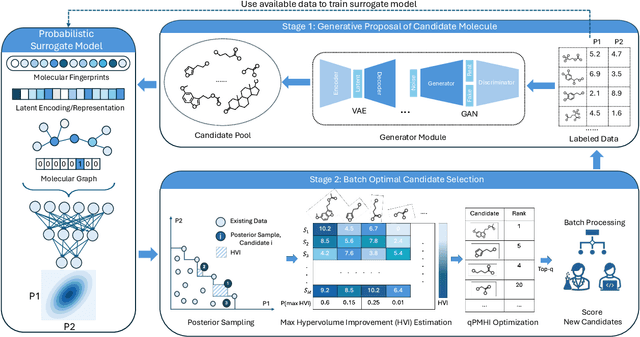
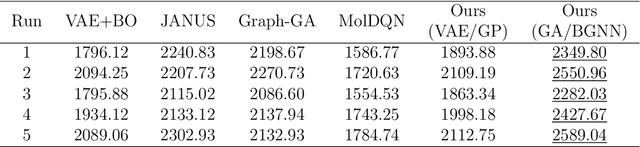
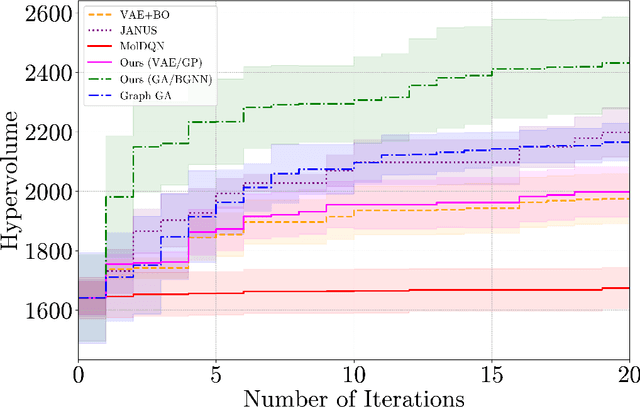

Designing molecules that must satisfy multiple, often conflicting objectives is a central challenge in molecular discovery. The enormous size of chemical space and the cost of high-fidelity simulations have driven the development of machine learning-guided strategies for accelerating design with limited data. Among these, Bayesian optimization (BO) offers a principled framework for sample-efficient search, while generative models provide a mechanism to propose novel, diverse candidates beyond fixed libraries. However, existing methods that couple the two often rely on continuous latent spaces, which introduces both architectural entanglement and scalability challenges. This work introduces an alternative, modular "generate-then-optimize" framework for de novo multi-objective molecular design/discovery. At each iteration, a generative model is used to construct a large, diverse pool of candidate molecules, after which a novel acquisition function, qPMHI (multi-point Probability of Maximum Hypervolume Improvement), is used to optimally select a batch of candidates most likely to induce the largest Pareto front expansion. The key insight is that qPMHI decomposes additively, enabling exact, scalable batch selection via only simple ranking of probabilities that can be easily estimated with Monte Carlo sampling. We benchmark the framework against state-of-the-art latent-space and discrete molecular optimization methods, demonstrating significant improvements across synthetic benchmarks and application-driven tasks. Specifically, in a case study related to sustainable energy storage, we show that our approach quickly uncovers novel, diverse, and high-performing organic (quinone-based) cathode materials for aqueous redox flow battery applications.
Metadata Enrichment of Long Text Documents using Large Language Models
Jun 26, 2025In this project, we semantically enriched and enhanced the metadata of long text documents, theses and dissertations, retrieved from the HathiTrust Digital Library in English published from 1920 to 2020 through a combination of manual efforts and large language models. This dataset provides a valuable resource for advancing research in areas such as computational social science, digital humanities, and information science. Our paper shows that enriching metadata using LLMs is particularly beneficial for digital repositories by introducing additional metadata access points that may not have originally been foreseen to accommodate various content types. This approach is particularly effective for repositories that have significant missing data in their existing metadata fields, enhancing search results and improving the accessibility of the digital repository.
SyMANTIC: An Efficient Symbolic Regression Method for Interpretable and Parsimonious Model Discovery in Science and Beyond
Feb 05, 2025



Symbolic regression (SR) is an emerging branch of machine learning focused on discovering simple and interpretable mathematical expressions from data. Although a wide-variety of SR methods have been developed, they often face challenges such as high computational cost, poor scalability with respect to the number of input dimensions, fragility to noise, and an inability to balance accuracy and complexity. This work introduces SyMANTIC, a novel SR algorithm that addresses these challenges. SyMANTIC efficiently identifies (potentially several) low-dimensional descriptors from a large set of candidates (from $\sim 10^5$ to $\sim 10^{10}$ or more) through a unique combination of mutual information-based feature selection, adaptive feature expansion, and recursively applied $\ell_0$-based sparse regression. In addition, it employs an information-theoretic measure to produce an approximate set of Pareto-optimal equations, each offering the best-found accuracy for a given complexity. Furthermore, our open-source implementation of SyMANTIC, built on the PyTorch ecosystem, facilitates easy installation and GPU acceleration. We demonstrate the effectiveness of SyMANTIC across a range of problems, including synthetic examples, scientific benchmarks, real-world material property predictions, and chaotic dynamical system identification from small datasets. Extensive comparisons show that SyMANTIC uncovers similar or more accurate models at a fraction of the cost of existing SR methods.
Zero-Indexing Internet Search Augmented Generation for Large Language Models
Nov 29, 2024Retrieval augmented generation has emerged as an effective method to enhance large language model performance. This approach typically relies on an internal retrieval module that uses various indexing mechanisms to manage a static pre-processed corpus. However, such a paradigm often falls short when it is necessary to integrate the most up-to-date information that has not been updated into the corpus during generative inference time. In this paper, we explore an alternative approach that leverages standard search engine APIs to dynamically integrate the latest online information (without maintaining any index for any fixed corpus), thereby improving the quality of generated content. We design a collaborative LLM-based paradigm, where we include: (i) a parser-LLM that determines if the Internet augmented generation is demanded and extracts the search keywords if so with a single inference; (ii) a mixed ranking strategy that re-ranks the retrieved HTML files to eliminate bias introduced from the search engine API; and (iii) an extractor-LLM that can accurately and efficiently extract relevant information from the fresh content in each HTML file. We conduct extensive empirical studies to evaluate the performance of this Internet search augmented generation paradigm. The experimental results demonstrate that our method generates content with significantly improved quality. Our system has been successfully deployed in a production environment to serve 01.AI's generative inference requests.
TQA-Bench: Evaluating LLMs for Multi-Table Question Answering with Scalable Context and Symbolic Extension
Nov 29, 2024The advent of large language models (LLMs) has unlocked great opportunities in complex data management tasks, particularly in question answering (QA) over complicated multi-table relational data. Despite significant progress, systematically evaluating LLMs on multi-table QA remains a critical challenge due to the inherent complexity of analyzing heterogeneous table structures and potential large scale of serialized relational data. Existing benchmarks primarily focus on single-table QA, failing to capture the intricacies of reasoning across multiple relational tables, as required in real-world domains such as finance, healthcare, and e-commerce. To address this gap, we present TQA-Bench, a new multi-table QA benchmark designed to evaluate the capabilities of LLMs in tackling complex QA tasks over relational data. Our benchmark incorporates diverse relational database instances sourced from real-world public datasets and introduces a flexible sampling mechanism to create tasks with varying multi-table context lengths, ranging from 8K to 64K tokens. To ensure robustness and reliability, we integrate symbolic extensions into the evaluation framework, enabling the assessment of LLM reasoning capabilities beyond simple data retrieval or probabilistic pattern matching. We systematically evaluate a range of LLMs, both open-source and closed-source, spanning model scales from 7 billion to 70 billion parameters. Our extensive experiments reveal critical insights into the performance of LLMs in multi-table QA, highlighting both challenges and opportunities for advancing their application in complex, data-driven environments. Our benchmark implementation and results are available at https://github.com/Relaxed-System-Lab/TQA-Bench.