 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Recommendation for Large-Scale Advertising
Feb 26, 2026Generative recommendation has recently attracted widespread attention in industry due to its potential for scaling and stronger model capacity. However, deploying real-time generative recommendation in large-scale advertising requires designs beyond large-language-model (LLM)-style training and serving recipes. We present a production-oriented generative recommender co-designed across architecture, learning, and serving, named GR4AD (Generative Recommendation for ADdvertising). As for tokenization, GR4AD proposes UA-SID (Unified Advertisement Semantic ID) to capture complicated business information. Furthermore, GR4AD introduces LazyAR, a lazy autoregressive decoder that relaxes layer-wise dependencies for short, multi-candidate generation, preserving effectiveness while reducing inference cost, which facilitates scaling under fixed serving budgets. To align optimization with business value, GR4AD employs VSL (Value-Aware Supervised Learning) and proposes RSPO (Ranking-Guided Softmax Preference Optimization), a ranking-aware, list-wise reinforcement learning algorithm that optimizes value-based rewards under list-level metrics for continual online updates. For online inference, we further propose dynamic beam serving, which adapts beam width across generation levels and online load to control compute. Large-scale online A/B tests show up to 4.2% ad revenue improvement over an existing DLRM-based stack, with consistent gains from both model scaling and inference-time scaling. GR4AD has been fully deployed in Kuaishou advertising system with over 400 million users and achieves high-throughput real-time serving.
From Principles to Applications: A Comprehensive Survey of Discrete Tokenizers in Generation, Comprehension, Recommendation, and Information Retrieval
Feb 18, 2025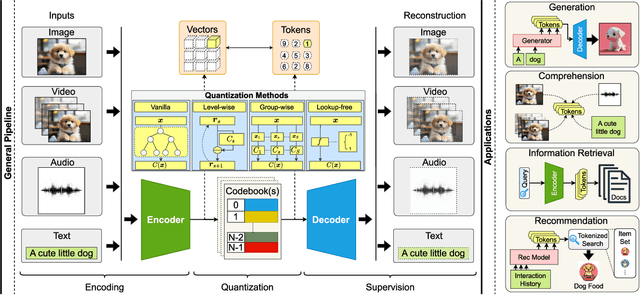
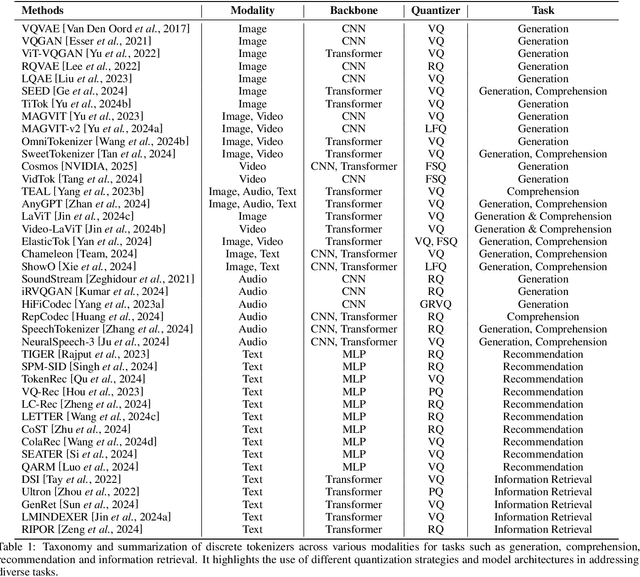
Discrete tokenizers have emerged as indispensable components in modern machine learning systems, particularly within the context of autoregressive modeling and large language models (LLMs). These tokenizers serve as the critical interface that transforms raw, unstructured data from diverse modalities into discrete tokens, enabling LLMs to operate effectively across a wide range of tasks. Despite their central role in generation, comprehension, and recommendation systems, a comprehensive survey dedicated to discrete tokenizers remains conspicuously absent in the literature. This paper addresses this gap by providing a systematic review of the design principles, applications, and challenges of discrete tokenizers. We begin by dissecting the sub-modules of tokenizers and systematically demonstrate their internal mechanisms to provide a comprehensive understanding of their functionality and design. Building on this foundation, we synthesize state-of-the-art methods, categorizing them into multimodal generation and comprehension tasks, and semantic tokens for personalized recommendations. Furthermore, we critically analyze the limitations of existing tokenizers and outline promising directions for future research. By presenting a unified framework for understanding discrete tokenizers, this survey aims to guide researchers and practitioners in addressing open challenges and advancing the field, ultimately contributing to the development of more robust and versatile AI systems.
SweetTokenizer: Semantic-Aware Spatial-Temporal Tokenizer for Compact Visual Discretization
Dec 17, 2024



This paper presents the \textbf{S}emantic-a\textbf{W}ar\textbf{E} spatial-t\textbf{E}mporal \textbf{T}okenizer (SweetTokenizer), a compact yet effective discretization approach for vision data. Our goal is to boost tokenizers' compression ratio while maintaining reconstruction fidelity in the VQ-VAE paradigm. Firstly, to obtain compact latent representations, we decouple images or videos into spatial-temporal dimensions, translating visual information into learnable querying spatial and temporal tokens through a \textbf{C}ross-attention \textbf{Q}uery \textbf{A}uto\textbf{E}ncoder (CQAE). Secondly, to complement visual information during compression, we quantize these tokens via a specialized codebook derived from off-the-shelf LLM embeddings to leverage the rich semantics from language modality. Finally, to enhance training stability and convergence, we also introduce a curriculum learning strategy, which proves critical for effective discrete visual representation learning. SweetTokenizer achieves comparable video reconstruction fidelity with only \textbf{25\%} of the tokens used in previous state-of-the-art video tokenizers, and boost video generation results by \textbf{32.9\%} w.r.t gFVD. When using the same token number, we significantly improves video and image reconstruction results by \textbf{57.1\%} w.r.t rFVD on UCF-101 and \textbf{37.2\%} w.r.t rFID on ImageNet-1K. Additionally, the compressed tokens are imbued with semantic information, enabling few-shot recognition capabilities powered by LLMs in downstream applications.
DCCF: Deep Comprehensible Color Filter Learning Framework for High-Resolution Image Harmonization
Jul 13, 2022

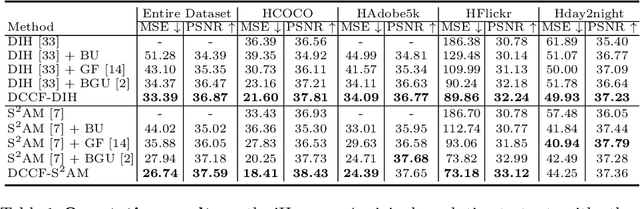
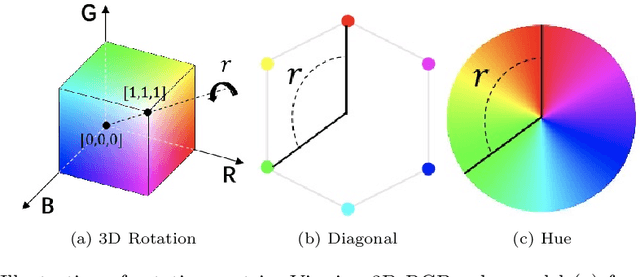
Image color harmonization algorithm aims to automatically match the color distribution of foreground and background images captured in different conditions. Previous deep learning based models neglect two issues that are critical for practical applications, namely high resolution (HR) image processing and model comprehensibility. In this paper, we propose a novel Deep Comprehensible Color Filter (DCCF) learning framework for high-resolution image harmonization. Specifically, DCCF first downsamples the original input image to its low-resolution (LR) counter-part, then learns four human comprehensible neural filters (i.e. hue, saturation, value and attentive rendering filters) in an end-to-end manner, finally applies these filters to the original input image to get the harmonized result. Benefiting from the comprehensible neural filters, we could provide a simple yet efficient handler for users to cooperate with deep model to get the desired results with very little effort when necessary. Extensive experiments demonstrate the effectiveness of DCCF learning framework and it outperforms state-of-the-art post-processing method on iHarmony4 dataset on images' full-resolutions by achieving 7.63% and 1.69% relative improvements on MSE and PSNR respectively.