 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign$^3$GR: Unified Multi-Level Alignment for LLM-based Generative Recommendation
Nov 14, 2025Large Language Models (LLMs) demonstrate significant advantages in leveraging structured world knowledge and multi-step reasoning capabilities. However, fundamental challenges arise when transforming LLMs into real-world recommender systems due to semantic and behavioral misalignment. To bridge this gap, we propose Align$^3$GR, a novel framework that unifies token-level, behavior modeling-level, and preference-level alignment. Our approach introduces: Dual tokenization fusing user-item semantic and collaborative signals. Enhanced behavior modeling with bidirectional semantic alignment. Progressive DPO strategy combining self-play (SP-DPO) and real-world feedback (RF-DPO) for dynamic preference adaptation. Experiments show Align$^3$GR outperforms the SOTA baseline by +17.8% in Recall@10 and +20.2% in NDCG@10 on the public dataset, with significant gains in online A/B tests and full-scale deployment on an industrial large-scale recommendation platform.
SweetTokenizer: Semantic-Aware Spatial-Temporal Tokenizer for Compact Visual Discretization
Dec 17, 2024



This paper presents the \textbf{S}emantic-a\textbf{W}ar\textbf{E} spatial-t\textbf{E}mporal \textbf{T}okenizer (SweetTokenizer), a compact yet effective discretization approach for vision data. Our goal is to boost tokenizers' compression ratio while maintaining reconstruction fidelity in the VQ-VAE paradigm. Firstly, to obtain compact latent representations, we decouple images or videos into spatial-temporal dimensions, translating visual information into learnable querying spatial and temporal tokens through a \textbf{C}ross-attention \textbf{Q}uery \textbf{A}uto\textbf{E}ncoder (CQAE). Secondly, to complement visual information during compression, we quantize these tokens via a specialized codebook derived from off-the-shelf LLM embeddings to leverage the rich semantics from language modality. Finally, to enhance training stability and convergence, we also introduce a curriculum learning strategy, which proves critical for effective discrete visual representation learning. SweetTokenizer achieves comparable video reconstruction fidelity with only \textbf{25\%} of the tokens used in previous state-of-the-art video tokenizers, and boost video generation results by \textbf{32.9\%} w.r.t gFVD. When using the same token number, we significantly improves video and image reconstruction results by \textbf{57.1\%} w.r.t rFVD on UCF-101 and \textbf{37.2\%} w.r.t rFID on ImageNet-1K. Additionally, the compressed tokens are imbued with semantic information, enabling few-shot recognition capabilities powered by LLMs in downstream applications.
DPF-Nutrition: Food Nutrition Estimation via Depth Prediction and Fusion
Oct 18, 2023



A reasonable and balanced diet is essential for maintaining good health. With the advancements in deep learning, automated nutrition estimation method based on food images offers a promising solution for monitoring daily nutritional intake and promoting dietary health. While monocular image-based nutrition estimation is convenient, efficient, and economical, the challenge of limited accuracy remains a significant concern. To tackle this issue, we proposed DPF-Nutrition, an end-to-end nutrition estimation method using monocular images. In DPF-Nutrition, we introduced a depth prediction module to generate depth maps, thereby improving the accuracy of food portion estimation. Additionally, we designed an RGB-D fusion module that combined monocular images with the predicted depth information, resulting in better performance for nutrition estimation. To the best of our knowledge, this was the pioneering effort that integrated depth prediction and RGB-D fusion techniques in food nutrition estimation. Comprehensive experiments performed on Nutrition5k evaluated the effectiveness and efficiency of DPF-Nutrition.
EENMF: An End-to-End Neural Matching Framework for E-Commerce Sponsored Search
Dec 09, 2018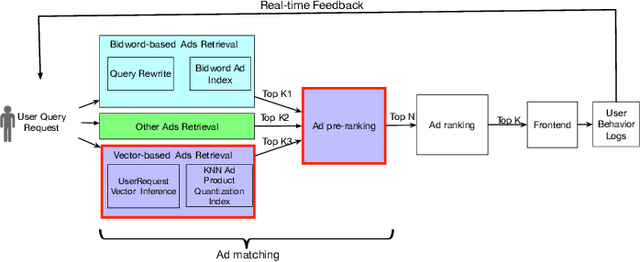
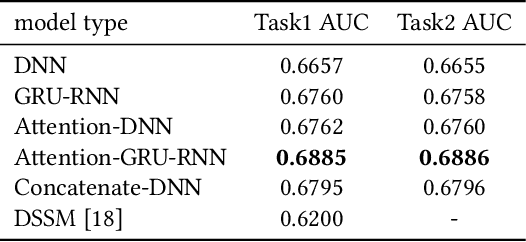
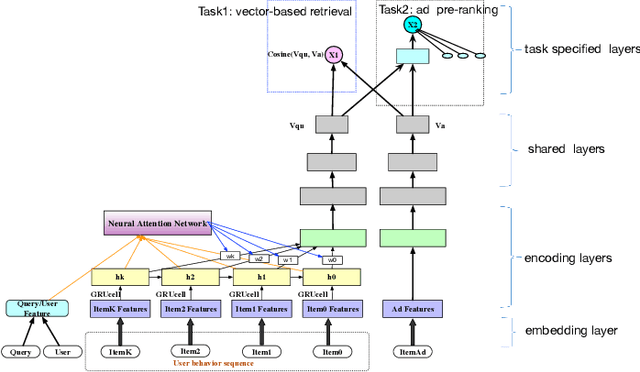
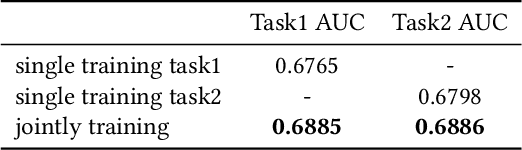
E-commerce sponsored search contributes an important part of revenue for the e-commerce company. In consideration of effectiveness and efficiency, a large-scale sponsored search system commonly adopts a multi-stage architecture. We name these stages as ad retrieval, ad pre-ranking and ad ranking. Ad retrieval and ad pre-ranking are collectively referred to as ad matching in this paper. We propose an end-to-end neural matching framework (EENMF) to model two tasks---vector-based ad retrieval and neural networks based ad pre-ranking. Under the deep matching framework, vector-based ad retrieval harnesses user recent behavior sequence to retrieve relevant ad candidates without the constraint of keyword bidding. Simultaneously, the deep model is employed to perform the global pre-ranking of ad candidates from multiple retrieval paths effectively and efficiently. Besides, the proposed model tries to optimize the pointwise cross-entropy loss which is consistent with the objective of predict models in the ranking stage. We conduct extensive evaluation to validate the performance of the proposed framework. In the real traffic of a large-scale e-commerce sponsored search, the proposed approach significantly outperforms the baseline.