 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChangeViT: Unleashing Plain Vision Transformers for Change Detection
Jun 18, 2024
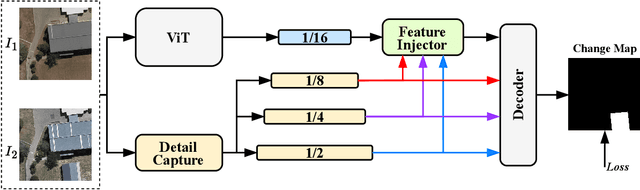


Change detection in remote sensing images is essential for tracking environmental changes on the Earth's surface. Despite the success of vision transformers (ViTs) as backbones in numerous computer vision applications, they remain underutilized in change detection, where convolutional neural networks (CNNs) continue to dominate due to their powerful feature extraction capabilities. In this paper, our study uncovers ViTs' unique advantage in discerning large-scale changes, a capability where CNNs fall short. Capitalizing on this insight, we introduce ChangeViT, a framework that adopts a plain ViT backbone to enhance the performance of large-scale changes. This framework is supplemented by a detail-capture module that generates detailed spatial features and a feature injector that efficiently integrates fine-grained spatial information into high-level semantic learning. The feature integration ensures that ChangeViT excels in both detecting large-scale changes and capturing fine-grained details, providing comprehensive change detection across diverse scales. Without bells and whistles, ChangeViT achieves state-of-the-art performance on three popular high-resolution datasets (i.e., LEVIR-CD, WHU-CD, and CLCD) and one low-resolution dataset (i.e., OSCD), which underscores the unleashed potential of plain ViTs for change detection. Furthermore, thorough quantitative and qualitative analyses validate the efficacy of the introduced modules, solidifying the effectiveness of our approach. The source code is available at https://github.com/zhuduowang/ChangeViT.
DPF-Nutrition: Food Nutrition Estimation via Depth Prediction and Fusion
Oct 18, 2023



A reasonable and balanced diet is essential for maintaining good health. With the advancements in deep learning, automated nutrition estimation method based on food images offers a promising solution for monitoring daily nutritional intake and promoting dietary health. While monocular image-based nutrition estimation is convenient, efficient, and economical, the challenge of limited accuracy remains a significant concern. To tackle this issue, we proposed DPF-Nutrition, an end-to-end nutrition estimation method using monocular images. In DPF-Nutrition, we introduced a depth prediction module to generate depth maps, thereby improving the accuracy of food portion estimation. Additionally, we designed an RGB-D fusion module that combined monocular images with the predicted depth information, resulting in better performance for nutrition estimation. To the best of our knowledge, this was the pioneering effort that integrated depth prediction and RGB-D fusion techniques in food nutrition estimation. Comprehensive experiments performed on Nutrition5k evaluated the effectiveness and efficiency of DPF-Nutrition.