 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoVA: Unified Multimodal Learning for Joint Video-Audio Generation
Dec 15, 2025In this paper, we present JoVA, a unified framework for joint video-audio generation. Despite recent encouraging advances, existing methods face two critical limitations. First, most existing approaches can only generate ambient sounds and lack the capability to produce human speech synchronized with lip movements. Second, recent attempts at unified human video-audio generation typically rely on explicit fusion or modality-specific alignment modules, which introduce additional architecture design and weaken the model simplicity of the original transformers. To address these issues, JoVA employs joint self-attention across video and audio tokens within each transformer layer, enabling direct and efficient cross-modal interaction without the need for additional alignment modules. Furthermore, to enable high-quality lip-speech synchronization, we introduce a simple yet effective mouth-area loss based on facial keypoint detection, which enhances supervision on the critical mouth region during training without compromising architectural simplicity. Extensive experiments on benchmarks demonstrate that JoVA outperforms or is competitive with both unified and audio-driven state-of-the-art methods in lip-sync accuracy, speech quality, and overall video-audio generation fidelity. Our results establish JoVA as an elegant framework for high-quality multimodal generation.
Change3D: Revisiting Change Detection and Captioning from A Video Modeling Perspective
Mar 24, 2025In this paper, we present Change3D, a framework that reconceptualizes the change detection and captioning tasks through video modeling. Recent methods have achieved remarkable success by regarding each pair of bi-temporal images as separate frames. They employ a shared-weight image encoder to extract spatial features and then use a change extractor to capture differences between the two images. However, image feature encoding, being a task-agnostic process, cannot attend to changed regions effectively. Furthermore, different change extractors designed for various change detection and captioning tasks make it difficult to have a unified framework. To tackle these challenges, Change3D regards the bi-temporal images as comprising two frames akin to a tiny video. By integrating learnable perception frames between the bi-temporal images, a video encoder enables the perception frames to interact with the images directly and perceive their differences. Therefore, we can get rid of the intricate change extractors, providing a unified framework for different change detection and captioning tasks. We verify Change3D on multiple tasks, encompassing change detection (including binary change detection, semantic change detection, and building damage assessment) and change captioning, across eight standard benchmarks. Without bells and whistles, this simple yet effective framework can achieve superior performance with an ultra-light video model comprising only ~6%-13% of the parameters and ~8%-34% of the FLOPs compared to state-of-the-art methods. We hope that Change3D could be an alternative to 2D-based models and facilitate future research.
PruneVid: Visual Token Pruning for Efficient Video Large Language Models
Dec 20, 2024



In this paper, we introduce PruneVid, a visual token pruning method designed to enhance the efficiency of multi-modal video understanding. Large Language Models (LLMs) have shown promising performance in video tasks due to their extended capabilities in comprehending visual modalities. However, the substantial redundancy in video data presents significant computational challenges for LLMs. To address this issue, we introduce a training-free method that 1) minimizes video redundancy by merging spatial-temporal tokens, and 2) leverages LLMs' reasoning capabilities to selectively prune visual features relevant to question tokens, enhancing model efficiency. We validate our method across multiple video benchmarks, which demonstrate that PruneVid can prune over 80% of tokens while maintaining competitive performance combined with different model networks. This highlights its superior effectiveness and efficiency compared to existing pruning methods. Code: https://github.com/Visual-AI/PruneVid.
ChangeViT: Unleashing Plain Vision Transformers for Change Detection
Jun 18, 2024
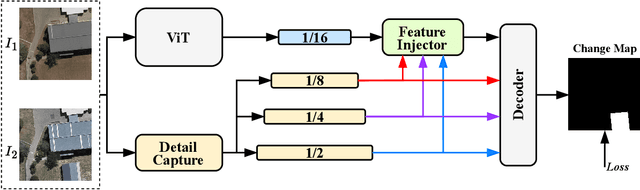


Change detection in remote sensing images is essential for tracking environmental changes on the Earth's surface. Despite the success of vision transformers (ViTs) as backbones in numerous computer vision applications, they remain underutilized in change detection, where convolutional neural networks (CNNs) continue to dominate due to their powerful feature extraction capabilities. In this paper, our study uncovers ViTs' unique advantage in discerning large-scale changes, a capability where CNNs fall short. Capitalizing on this insight, we introduce ChangeViT, a framework that adopts a plain ViT backbone to enhance the performance of large-scale changes. This framework is supplemented by a detail-capture module that generates detailed spatial features and a feature injector that efficiently integrates fine-grained spatial information into high-level semantic learning. The feature integration ensures that ChangeViT excels in both detecting large-scale changes and capturing fine-grained details, providing comprehensive change detection across diverse scales. Without bells and whistles, ChangeViT achieves state-of-the-art performance on three popular high-resolution datasets (i.e., LEVIR-CD, WHU-CD, and CLCD) and one low-resolution dataset (i.e., OSCD), which underscores the unleashed potential of plain ViTs for change detection. Furthermore, thorough quantitative and qualitative analyses validate the efficacy of the introduced modules, solidifying the effectiveness of our approach. The source code is available at https://github.com/zhuduowang/ChangeViT.
Skim then Focus: Integrating Contextual and Fine-grained Views for Repetitive Action Counting
Jun 13, 2024



The key to action counting is accurately locating each video's repetitive actions. Instead of estimating the probability of each frame belonging to an action directly, we propose a dual-branch network, i.e., SkimFocusNet, working in a two-step manner. The model draws inspiration from empirical observations indicating that humans typically engage in coarse skimming of entire sequences to grasp the general action pattern initially, followed by a finer, frame-by-frame focus to determine if it aligns with the target action. Specifically, SkimFocusNet incorporates a skim branch and a focus branch. The skim branch scans the global contextual information throughout the sequence to identify potential target action for guidance. Subsequently, the focus branch utilizes the guidance to diligently identify repetitive actions using a long-short adaptive guidance (LSAG) block. Additionally, we have observed that videos in existing datasets often feature only one type of repetitive action, which inadequately represents real-world scenarios. To more accurately describe real-life situations, we establish the Multi-RepCount dataset, which includes videos containing multiple repetitive motions. On Multi-RepCount, our SkimFoucsNet can perform specified action counting, that is, to enable counting a particular action type by referencing an exemplary video. This capability substantially exhibits the robustness of our method. Extensive experiments demonstrate that SkimFocusNet achieves state-of-the-art performances with significant improvements. We also conduct a thorough ablation study to evaluate the network components. The source code will be published upon acceptance.
FROSTER: Frozen CLIP Is A Strong Teacher for Open-Vocabulary Action Recognition
Feb 05, 2024In this paper, we introduce FROSTER, an effective framework for open-vocabulary action recognition. The CLIP model has achieved remarkable success in a range of image-based tasks, benefiting from its strong generalization capability stemming from pretaining on massive image-text pairs. However, applying CLIP directly to the open-vocabulary action recognition task is challenging due to the absence of temporal information in CLIP's pretraining. Further, fine-tuning CLIP on action recognition datasets may lead to overfitting and hinder its generalizability, resulting in unsatisfactory results when dealing with unseen actions. To address these issues, FROSTER employs a residual feature distillation approach to ensure that CLIP retains its generalization capability while effectively adapting to the action recognition task. Specifically, the residual feature distillation treats the frozen CLIP model as a teacher to maintain the generalizability exhibited by the original CLIP and supervises the feature learning for the extraction of video-specific features to bridge the gap between images and videos. Meanwhile, it uses a residual sub-network for feature distillation to reach a balance between the two distinct objectives of learning generalizable and video-specific features. We extensively evaluate FROSTER on open-vocabulary action recognition benchmarks under both base-to-novel and cross-dataset settings. FROSTER consistently achieves state-of-the-art performance on all datasets across the board. Project page: https://visual-ai.github.io/froster.
Condition-Adaptive Graph Convolution Learning for Skeleton-Based Gait Recognition
Aug 13, 2023



Graph convolutional networks have been widely applied in skeleton-based gait recognition. A key challenge in this task is to distinguish the individual walking styles of different subjects across various views. Existing state-of-the-art methods employ uniform convolutions to extract features from diverse sequences and ignore the effects of viewpoint changes. To overcome these limitations, we propose a condition-adaptive graph (CAG) convolution network that can dynamically adapt to the specific attributes of each skeleton sequence and the corresponding view angle. In contrast to using fixed weights for all joints and sequences, we introduce a joint-specific filter learning (JSFL) module in the CAG method, which produces sequence-adaptive filters at the joint level. The adaptive filters capture fine-grained patterns that are unique to each joint, enabling the extraction of diverse spatial-temporal information about body parts. Additionally, we design a view-adaptive topology learning (VATL) module that generates adaptive graph topologies. These graph topologies are used to correlate the joints adaptively according to the specific view conditions. Thus, CAG can simultaneously adjust to various walking styles and viewpoints. Experiments on the two most widely used datasets (i.e., CASIA-B and OU-MVLP) show that CAG surpasses all previous skeleton-based methods. Moreover, the recognition performance can be enhanced by simply combining CAG with appearance-based methods, demonstrating the ability of CAG to provide useful complementary information.The source code will be available at https://github.com/OliverHxh/CAG.
GaitGS: Temporal Feature Learning in Granularity and Span Dimension for Gait Recognition
Jun 01, 2023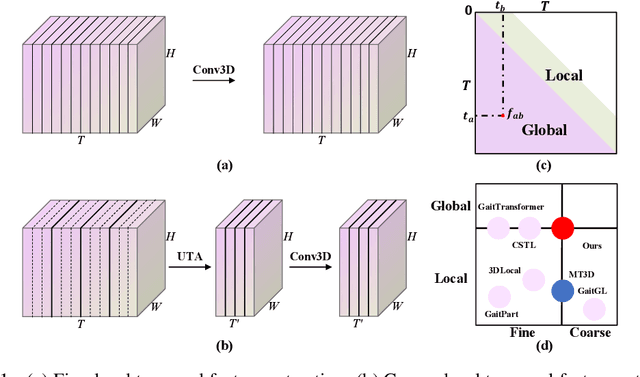
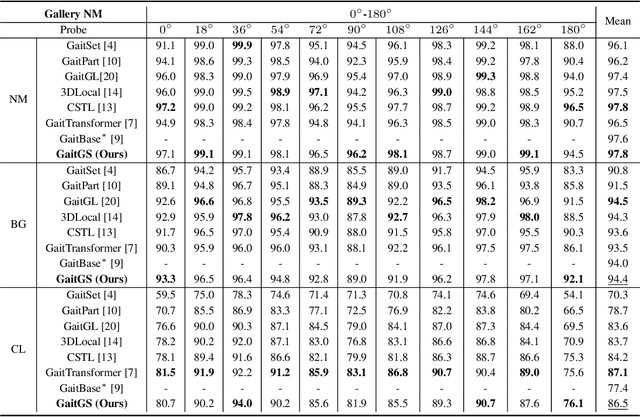
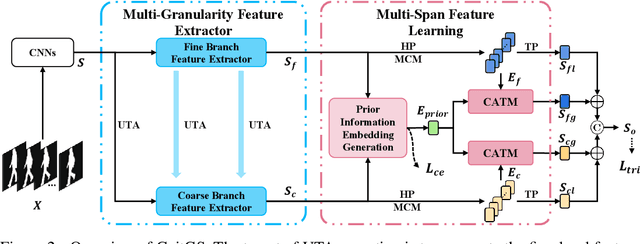
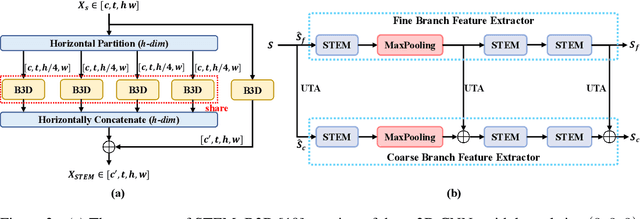
Gait recognition is an emerging biological recognition technology that identifies and verifies individuals based on their walking patterns. However, many current methods are limited in their use of temporal information. In order to fully harness the potential of gait recognition, it is crucial to consider temporal features at various granularities and spans. Hence, in this paper, we propose a novel framework named GaitGS, which aggregates temporal features in the granularity dimension and span dimension simultaneously. Specifically, Multi-Granularity Feature Extractor (MGFE) is proposed to focus on capturing the micro-motion and macro-motion information at the frame level and unit level respectively. Moreover, we present Multi-Span Feature Learning (MSFL) module to generate global and local temporal representations. On three popular gait datasets, extensive experiments demonstrate the state-of-the-art performance of our method. Our method achieves the Rank-1 accuracies of 92.9% (+0.5%), 52.0% (+1.4%), and 97.5% (+0.8%) on CASIA-B, GREW, and OU-MVLP respectively. The source code will be released soon.
Graph Contrastive Learning for Skeleton-based Action Recognition
Jan 26, 2023
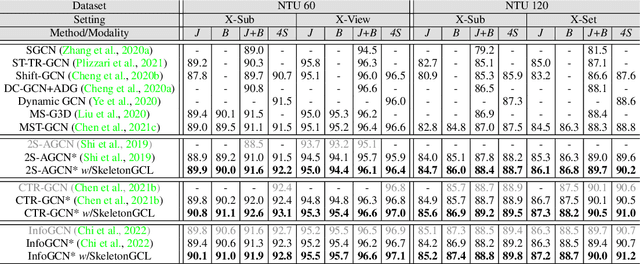

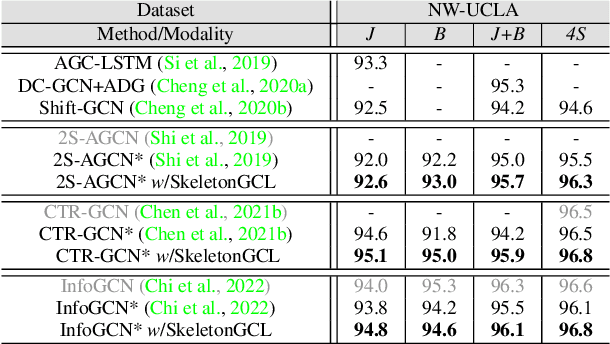
In the field of skeleton-based action recognition, current top-performing graph convolutional networks (GCNs) exploit intra-sequence context to construct adaptive graphs for feature aggregation. However, we argue that such context is still \textit{local} since the rich cross-sequence relations have not been explicitly investigated. In this paper, we propose a graph contrastive learning framework for skeleton-based action recognition (\textit{SkeletonGCL}) to explore the \textit{global} context across all sequences. In specific, SkeletonGCL associates graph learning across sequences by enforcing graphs to be class-discriminative, \emph{i.e.,} intra-class compact and inter-class dispersed, which improves the GCN capacity to distinguish various action patterns. Besides, two memory banks are designed to enrich cross-sequence context from two complementary levels, \emph{i.e.,} instance and semantic levels, enabling graph contrastive learning in multiple context scales. Consequently, SkeletonGCL establishes a new training paradigm, and it can be seamlessly incorporated into current GCNs. Without loss of generality, we combine SkeletonGCL with three GCNs (2S-ACGN, CTR-GCN, and InfoGCN), and achieve consistent improvements on NTU60, NTU120, and NW-UCLA benchmarks. The source code will be available at \url{https://github.com/OliverHxh/SkeletonGCL}.
Context-Sensitive Temporal Feature Learning for Gait Recognition
Apr 08, 2022
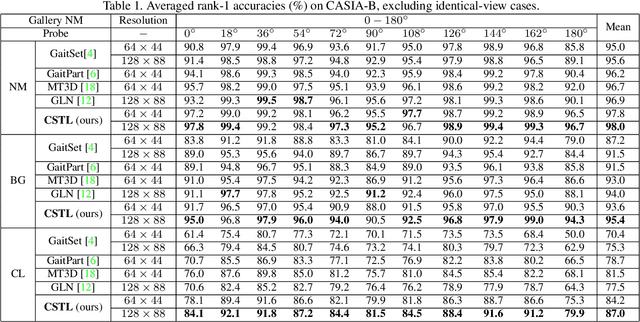

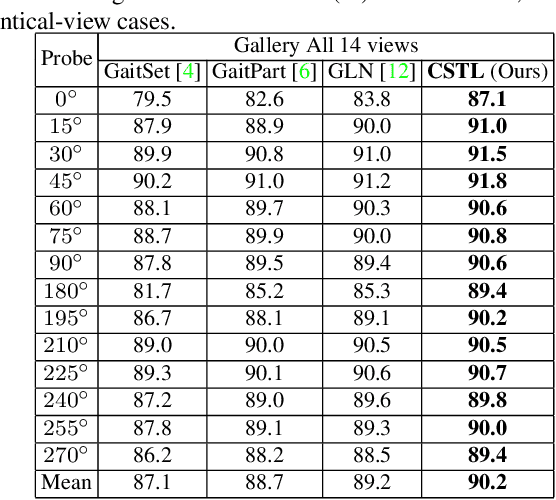
Although gait recognition has drawn increasing research attention recently, it remains challenging to learn discriminative temporal representation, since the silhouette differences are quite subtle in spatial domain. Inspired by the observation that human can distinguish gaits of different subjects by adaptively focusing on temporal clips with different time scales, we propose a context-sensitive temporal feature learning (CSTL) network for gait recognition. CSTL produces temporal features in three scales, and adaptively aggregates them according to the contextual information from local and global perspectives. Specifically, CSTL contains an adaptive temporal aggregation module that subsequently performs local relation modeling and global relation modeling to fuse the multi-scale features. Besides, in order to remedy the spatial feature corruption caused by temporal operations, CSTL incorporates a salient spatial feature learning (SSFL) module to select groups of discriminative spatial features. Particularly, we utilize transformers to implement the global relation modeling and the SSFL module. To the best of our knowledge, this is the first work that adopts transformer in gait recognition. Extensive experiments conducted on three datasets demonstrate the state-of-the-art performance. Concretely, we achieve rank-1 accuracies of 98.7%, 96.2% and 88.7% under normal-walking, bag-carrying and coat-wearing conditions on CASIA-B, 97.5% on OU-MVLP and 50.6% on GREW.