 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Fusion Controller: Degradation-aware Image Fusion with Fine-grained Language Instructions
Apr 09, 2025Current image fusion methods struggle to adapt to real-world environments encompassing diverse degradations with spatially varying characteristics. To address this challenge, we propose a robust fusion controller (RFC) capable of achieving degradation-aware image fusion through fine-grained language instructions, ensuring its reliable application in adverse environments. Specifically, RFC first parses language instructions to innovatively derive the functional condition and the spatial condition, where the former specifies the degradation type to remove, while the latter defines its spatial coverage. Then, a composite control priori is generated through a multi-condition coupling network, achieving a seamless transition from abstract language instructions to latent control variables. Subsequently, we design a hybrid attention-based fusion network to aggregate multi-modal information, in which the obtained composite control priori is deeply embedded to linearly modulate the intermediate fused features. To ensure the alignment between language instructions and control outcomes, we introduce a novel language-feature alignment loss, which constrains the consistency between feature-level gains and the composite control priori. Extensive experiments on publicly available datasets demonstrate that our RFC is robust against various composite degradations, particularly in highly challenging flare scenarios.
Change3D: Revisiting Change Detection and Captioning from A Video Modeling Perspective
Mar 24, 2025In this paper, we present Change3D, a framework that reconceptualizes the change detection and captioning tasks through video modeling. Recent methods have achieved remarkable success by regarding each pair of bi-temporal images as separate frames. They employ a shared-weight image encoder to extract spatial features and then use a change extractor to capture differences between the two images. However, image feature encoding, being a task-agnostic process, cannot attend to changed regions effectively. Furthermore, different change extractors designed for various change detection and captioning tasks make it difficult to have a unified framework. To tackle these challenges, Change3D regards the bi-temporal images as comprising two frames akin to a tiny video. By integrating learnable perception frames between the bi-temporal images, a video encoder enables the perception frames to interact with the images directly and perceive their differences. Therefore, we can get rid of the intricate change extractors, providing a unified framework for different change detection and captioning tasks. We verify Change3D on multiple tasks, encompassing change detection (including binary change detection, semantic change detection, and building damage assessment) and change captioning, across eight standard benchmarks. Without bells and whistles, this simple yet effective framework can achieve superior performance with an ultra-light video model comprising only ~6%-13% of the parameters and ~8%-34% of the FLOPs compared to state-of-the-art methods. We hope that Change3D could be an alternative to 2D-based models and facilitate future research.
ChangeViT: Unleashing Plain Vision Transformers for Change Detection
Jun 18, 2024
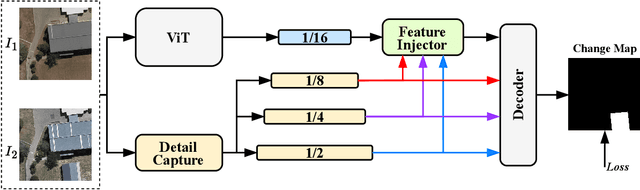


Change detection in remote sensing images is essential for tracking environmental changes on the Earth's surface. Despite the success of vision transformers (ViTs) as backbones in numerous computer vision applications, they remain underutilized in change detection, where convolutional neural networks (CNNs) continue to dominate due to their powerful feature extraction capabilities. In this paper, our study uncovers ViTs' unique advantage in discerning large-scale changes, a capability where CNNs fall short. Capitalizing on this insight, we introduce ChangeViT, a framework that adopts a plain ViT backbone to enhance the performance of large-scale changes. This framework is supplemented by a detail-capture module that generates detailed spatial features and a feature injector that efficiently integrates fine-grained spatial information into high-level semantic learning. The feature integration ensures that ChangeViT excels in both detecting large-scale changes and capturing fine-grained details, providing comprehensive change detection across diverse scales. Without bells and whistles, ChangeViT achieves state-of-the-art performance on three popular high-resolution datasets (i.e., LEVIR-CD, WHU-CD, and CLCD) and one low-resolution dataset (i.e., OSCD), which underscores the unleashed potential of plain ViTs for change detection. Furthermore, thorough quantitative and qualitative analyses validate the efficacy of the introduced modules, solidifying the effectiveness of our approach. The source code is available at https://github.com/zhuduowang/ChangeViT.
CartoMark: a benchmark dataset for map pattern recognition and 1 map content retrieval with machine intelligence
Dec 14, 2023



Maps are fundamental medium to visualize and represent the real word in a simple and 16 philosophical way. The emergence of the 3rd wave information has made a proportion of maps are available to be generated ubiquitously, which would significantly enrich the dimensions and perspectives to understand the characteristics of the real world. However, a majority of map dataset have never been discovered, acquired and effectively used, and the map data used in many applications might not be completely fitted for the authentic demands of these applications. This challenge is emerged due to the lack of numerous well-labelled benchmark datasets for implementing the deep learning approaches into identifying complicated map content. Thus, we develop a large-scale benchmark dataset that includes well-labelled dataset for map text annotation recognition, map scene classification, map super-resolution reconstruction, and map style transferring. Furthermore, these well-labelled datasets would facilitate the state-of-the-art machine intelligence technologies to conduct map feature detection, map pattern recognition and map content retrieval. We hope our efforts would be useful for AI-enhanced cartographical applications.
Spatio-temporal-spectral-angular observation model that integrates observations from UAV and mobile mapping vehicle for better urban mapping
Sep 05, 2021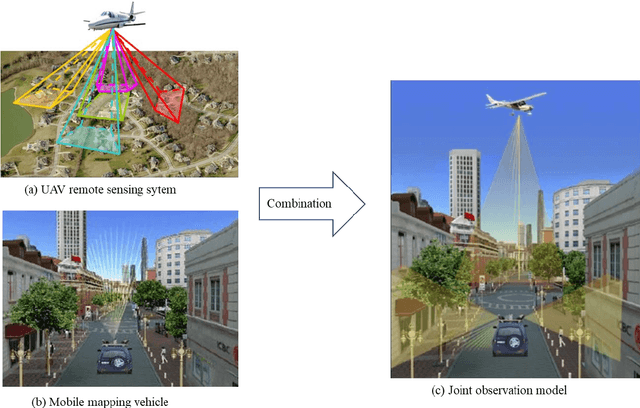
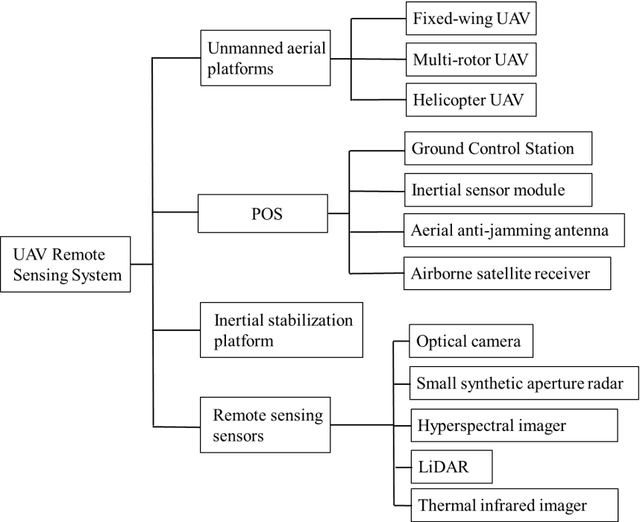

In a complex urban scene, observation from a single sensor unavoidably leads to voids in observations, failing to describe urban objects in a comprehensive manner. In this paper, we propose a spatio-temporal-spectral-angular observation model to integrate observations from UAV and mobile mapping vehicle platform, realizing a joint, coordinated observation operation from both air and ground. We develop a multi-source remote sensing data acquisition system to effectively acquire multi-angle data of complex urban scenes. Multi-source data fusion solves the missing data problem caused by occlusion and achieves accurate, rapid, and complete collection of holographic spatial and temporal information in complex urban scenes. We carried out an experiment on Baisha Town, Chongqing, China and obtained multi-sensor, multi-angle data from UAV and mobile mapping vehicle. We first extracted the point cloud from UAV and then integrated the UAV and mobile mapping vehicle point cloud. The integrated results combined both the characteristic of UAV and mobile mapping vehicle point cloud, confirming the practicability of the proposed joint data acquisition platform and the effectiveness of spatio-temporal-spectral-angular observation model. Compared with the observation from UAV or mobile mapping vehicle alone, the integrated system provides an effective data acquisition solution towards comprehensive urban monitoring.
GLSD: The Global Large-Scale Ship Database and Baseline Evaluations
Jun 05, 2021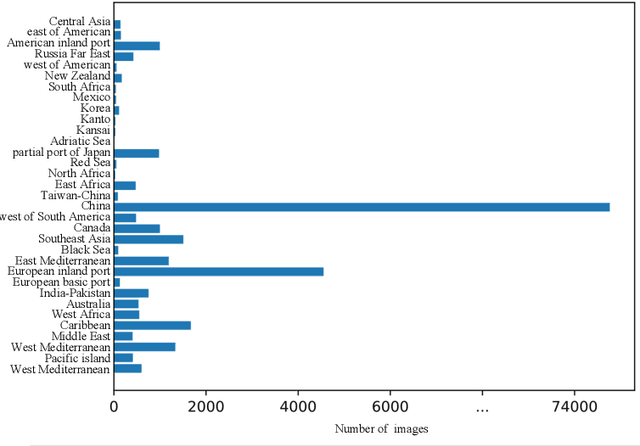


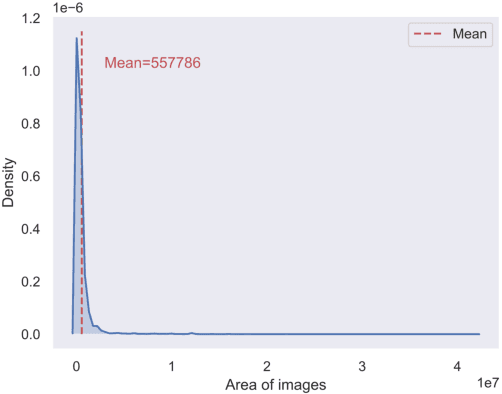
In this paper, we introduce a challenging global large-scale ship database (called GLSD), designed specifically for ship detection tasks. The designed GLSD database includes a total of 140,616 annotated instances from 100,729 images. Based on the collected images, we propose 13 categories that widely exists in international routes. These categories include sailing boat, fishing boat, passenger ship, war ship, general cargo ship, container ship, bulk cargo carrier, barge, ore carrier, speed boat, canoe, oil carrier, and tug. The motivations of developing GLSD include the following: 1) providing a refined ship detection database; 2) providing the worldwide researchers of ship detection and exhaustive label information (bounding box and ship class label) in one uniform global database; and 3) providing a large-scale ship database with geographic information (port and country information) that benefits multi-modal analysis. In addition, we discuss the evaluation protocols given image characteristics in GLSD and analyze the performance of selected state-of-the-art object detection algorithms on GSLD, providing baselines for future studies. More information regarding the designed GLSD can be found at https://github.com/jiaming-wang/GLSD.
Pan-sharpening via High-pass Modification Convolutional Neural Network
May 24, 2021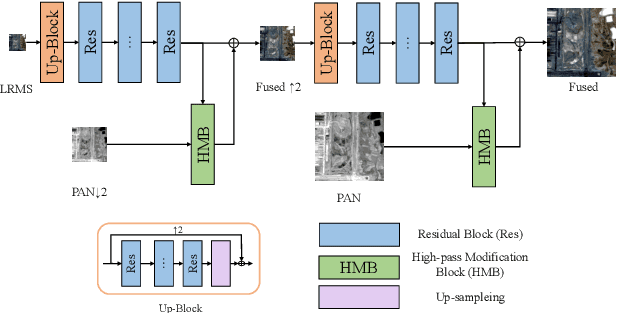

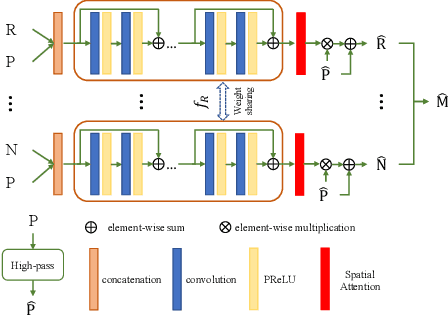

Most existing deep learning-based pan-sharpening methods have several widely recognized issues, such as spectral distortion and insufficient spatial texture enhancement, we propose a novel pan-sharpening convolutional neural network based on a high-pass modification block. Different from existing methods, the proposed block is designed to learn the high-pass information, leading to enhance spatial information in each band of the multi-spectral-resolution images. To facilitate the generation of visually appealing pan-sharpened images, we propose a perceptual loss function and further optimize the model based on high-level features in the near-infrared space. Experiments demonstrate the superior performance of the proposed method compared to the state-of-the-art pan-sharpening methods, both quantitatively and qualitatively. The proposed model is open-sourced at https://github.com/jiaming-wang/HMB.
SSCAN: A Spatial-spectral Cross Attention Network for Hyperspectral Image Denoising
May 23, 2021


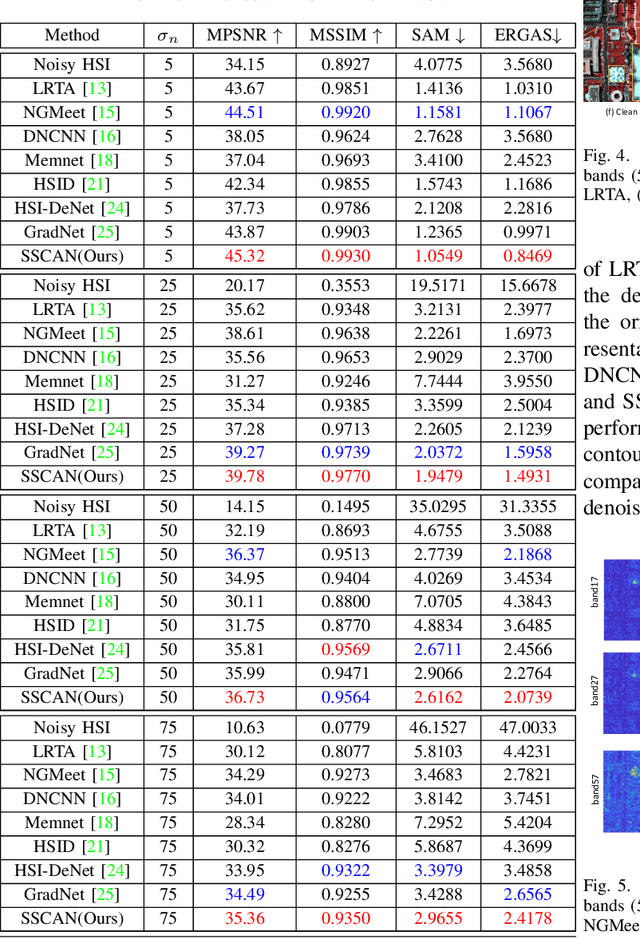
Hyperspectral images (HSIs) have been widely used in a variety of applications thanks to the rich spectral information they are able to provide. Among all HSI processing tasks, HSI denoising is a crucial step. Recently, deep learning-based image denoising methods have made great progress and achieved great performance. However, existing methods tend to ignore the correlations between adjacent spectral bands, leading to problems such as spectral distortion and blurred edges in denoised results. In this study, we propose a novel HSI denoising network, termed SSCAN, that combines group convolutions and attention modules. Specifically, we use a group convolution with a spatial attention module to facilitate feature extraction by directing models' attention to band-wise important features. We propose a spectral-spatial attention block (SSAB) to exploit the spatial and spectral information in hyperspectral images in an effective manner. In addition, we adopt residual learning operations with skip connections to ensure training stability. The experimental results indicate that the proposed SSCAN outperforms several state-of-the-art HSI denoising algorithms.
Unsupervised Remote Sensing Super-Resolution via Migration Image Prior
May 23, 2021

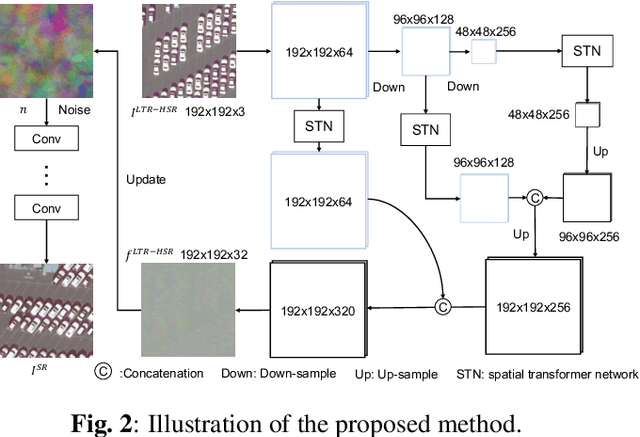
Recently, satellites with high temporal resolution have fostered wide attention in various practical applications. Due to limitations of bandwidth and hardware cost, however, the spatial resolution of such satellites is considerably low, largely limiting their potentials in scenarios that require spatially explicit information. To improve image resolution, numerous approaches based on training low-high resolution pairs have been proposed to address the super-resolution (SR) task. Despite their success, however, low/high spatial resolution pairs are usually difficult to obtain in satellites with a high temporal resolution, making such approaches in SR impractical to use. In this paper, we proposed a new unsupervised learning framework, called "MIP", which achieves SR tasks without low/high resolution image pairs. First, random noise maps are fed into a designed generative adversarial network (GAN) for reconstruction. Then, the proposed method converts the reference image to latent space as the migration image prior. Finally, we update the input noise via an implicit method, and further transfer the texture and structured information from the reference image. Extensive experimental results on the Draper dataset show that MIP achieves significant improvements over state-of-the-art methods both quantitatively and qualitatively. The proposed MIP is open-sourced at http://github.com/jiaming-wang/MIP.
Region Convolutional Features for Multi-Label Remote Sensing Image Retrieval
Jul 23, 2018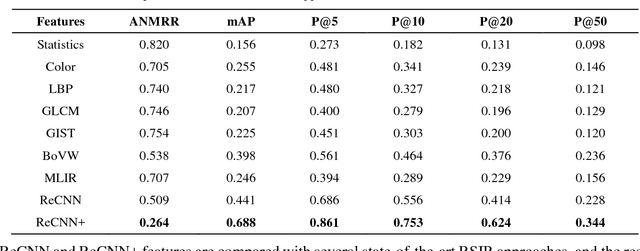
Conventional remote sensing image retrieval (RSIR) systems usually perform single-label retrieval where each image is annotated by a single label representing the most significant semantic content of the image. This assumption, however, ignores the complexity of remote sensing images, where an image might have multiple classes (i.e., multiple labels), thus resulting in worse retrieval performance. We therefore propose a novel multi-label RSIR approach with fully convolutional networks (FCN). In our approach, we first train a FCN model using a pixel-wise labeled dataset,and the trained FCN is then used to predict the segmentation maps of each image in the considered archive. We finally extract region convolutional features of each image based on its segmentation map.The region features can be either used to perform region-based retrieval or further post-processed to obtain a feature vector for similarity measure. The experimental results show that our approach achieves state-of-the-art performance in contrast to conventional single-label and recent multi-label RSIR approaches.