 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Semantic Communications for Digital Signals via Carrier Images
Dec 10, 2024Most of current semantic communication (SemCom) frameworks focus on the image transmission, which, however, do not address the problem on how to deliver digital signals without any semantic features. This paper proposes a novel SemCom approach to transmit digital signals by using the image as the carrier signal. Specifically, the proposed approach encodes the digital signal as a binary stream and maps it to mask locations on an image. This allows binary data to be visually represented, enabling the use of existing model, pre-trained Masked Autoencoders (MAE), which are optimized for masked image reconstruction, as the SemCom encoder and decoder. Since MAE can both process and recover masked images, this approach allows for the joint transmission of digital signals and images without additional overhead. In addition, considering the mask tokens transmission encoded by the MAE still faces extra costs, we design a sparse encoding module at the transmitter to encode the mask tokens into a sparse matrix, and it can be recovered at the receiver. Thus, this approach simply needs to transmit the latent representations of the unmasked patches and a sparse matrix, which further reduce the transmission overhead compared with the original MAE encoder. Simulation results show that the approach maintains reliable transmission of digital signals and images even in a high mask ratio of transmitted images.
Adaptive Decentralized Federated Learning in Energy and Latency Constrained Wireless Networks
Mar 29, 2024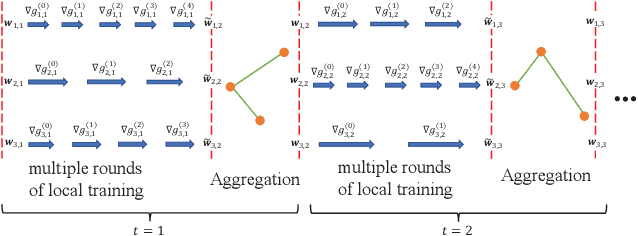
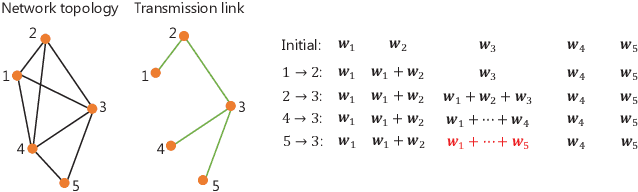
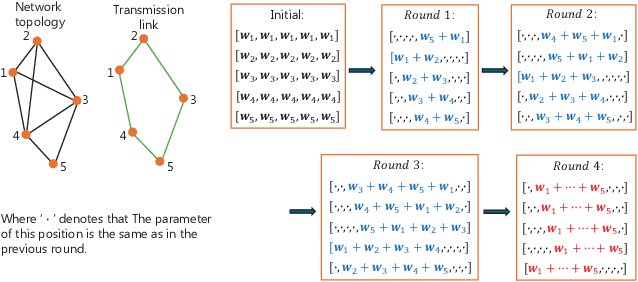
In Federated Learning (FL), with parameter aggregated by a central node, the communication overhead is a substantial concern. To circumvent this limitation and alleviate the single point of failure within the FL framework, recent studies have introduced Decentralized Federated Learning (DFL) as a viable alternative. Considering the device heterogeneity, and energy cost associated with parameter aggregation, in this paper, the problem on how to efficiently leverage the limited resources available to enhance the model performance is investigated. Specifically, we formulate a problem that minimizes the loss function of DFL while considering energy and latency constraints. The proposed solution involves optimizing the number of local training rounds across diverse devices with varying resource budgets. To make this problem tractable, we first analyze the convergence of DFL with edge devices with different rounds of local training. The derived convergence bound reveals the impact of the rounds of local training on the model performance. Then, based on the derived bound, the closed-form solutions of rounds of local training in different devices are obtained. Meanwhile, since the solutions require the energy cost of aggregation as low as possible, we modify different graph-based aggregation schemes to solve this energy consumption minimization problem, which can be applied to different communication scenarios. Finally, a DFL framework which jointly considers the optimized rounds of local training and the energy-saving aggregation scheme is proposed. Simulation results show that, the proposed algorithm achieves a better performance than the conventional schemes with fixed rounds of local training, and consumes less energy than other traditional aggregation schemes.
CartoMark: a benchmark dataset for map pattern recognition and 1 map content retrieval with machine intelligence
Dec 14, 2023



Maps are fundamental medium to visualize and represent the real word in a simple and 16 philosophical way. The emergence of the 3rd wave information has made a proportion of maps are available to be generated ubiquitously, which would significantly enrich the dimensions and perspectives to understand the characteristics of the real world. However, a majority of map dataset have never been discovered, acquired and effectively used, and the map data used in many applications might not be completely fitted for the authentic demands of these applications. This challenge is emerged due to the lack of numerous well-labelled benchmark datasets for implementing the deep learning approaches into identifying complicated map content. Thus, we develop a large-scale benchmark dataset that includes well-labelled dataset for map text annotation recognition, map scene classification, map super-resolution reconstruction, and map style transferring. Furthermore, these well-labelled datasets would facilitate the state-of-the-art machine intelligence technologies to conduct map feature detection, map pattern recognition and map content retrieval. We hope our efforts would be useful for AI-enhanced cartographical applications.
Performance Analysis for Resource Constrained Decentralized Federated Learning Over Wireless Networks
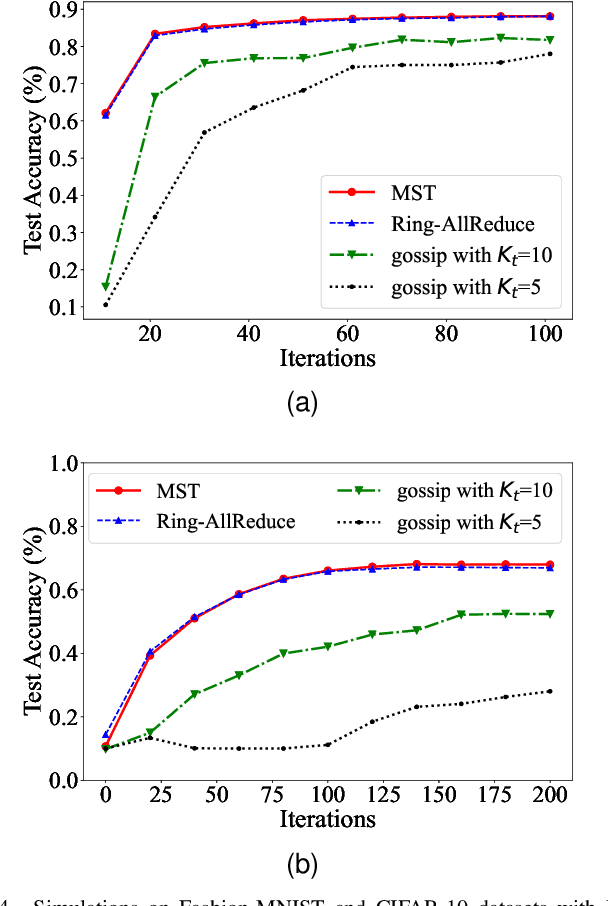
Aug 12, 2023Federated learning (FL) can lead to significant communication overhead and reliance on a central server. To address these challenges, decentralized federated learning (DFL) has been proposed as a more resilient framework. DFL involves parameter exchange between devices through a wireless network. This study analyzes the performance of resource-constrained DFL using different communication schemes (digital and analog) over wireless networks to optimize communication efficiency. Specifically, we provide convergence bounds for both digital and analog transmission approaches, enabling analysis of the model performance trained on DFL. Furthermore, for digital transmission, we investigate and analyze resource allocation between computation and communication and convergence rates, obtaining its communication complexity and the minimum probability of correction communication required for convergence guarantee. For analog transmission, we discuss the impact of channel fading and noise on the model performance and the maximum errors accumulation with convergence guarantee over fading channels. Finally, we conduct numerical simulations to evaluate the performance and convergence rate of convolutional neural networks (CNNs) and Vision Transformer (ViT) trained in the DFL framework on fashion-MNIST and CIFAR-10 datasets. Our simulation results validate our analysis and discussion, revealing how to improve performance by optimizing system parameters under different communication conditions.
Revisiting Communication-Efficient Federated Learning with Balanced Global and Local Updates
May 03, 2022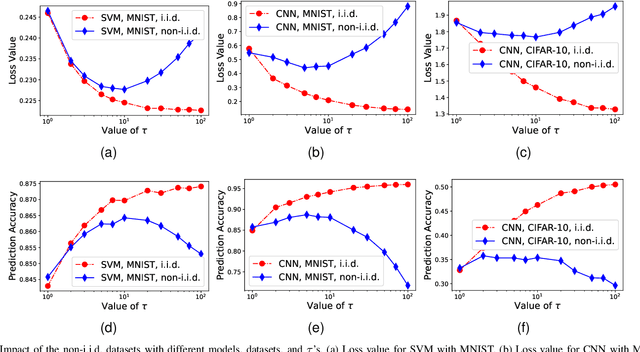
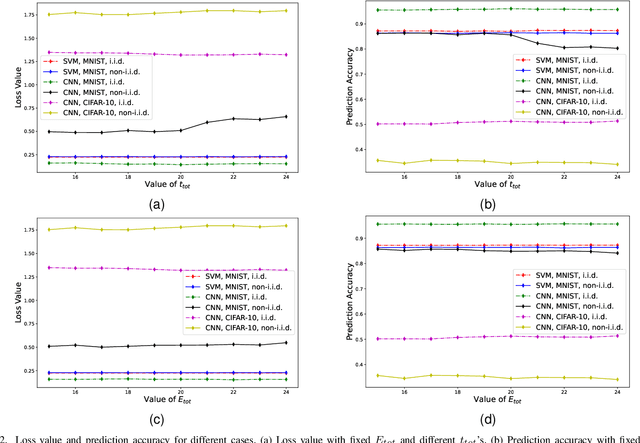
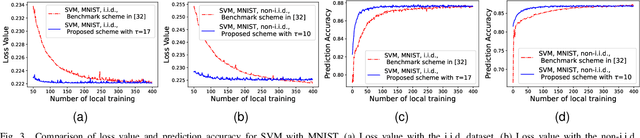
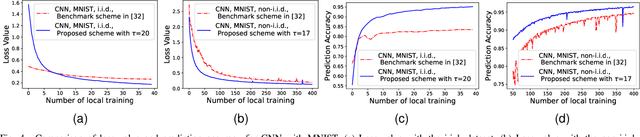
In federated learning (FL), a number of devices train their local models and upload the corresponding parameters or gradients to the base station (BS) to update the global model while protecting their data privacy. However, due to the limited computation and communication resources, the number of local trainings (a.k.a. local update) and that of aggregations (a.k.a. global update) need to be carefully chosen. In this paper, we investigate and analyze the optimal trade-off between the number of local trainings and that of global aggregations to speed up the convergence and enhance the prediction accuracy over the existing works. Our goal is to minimize the global loss function under both the delay and the energy consumption constraints. In order to make the optimization problem tractable, we derive a new and tight upper bound on the loss function, which allows us to obtain closed-form expressions for the number of local trainings and that of global aggregations. Simulation results show that our proposed scheme can achieve a better performance in terms of the prediction accuracy, and converge much faster than the baseline schemes.