 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Communication-Efficient Federated Learning with Balanced Global and Local Updates
Paper and Code
May 03, 2022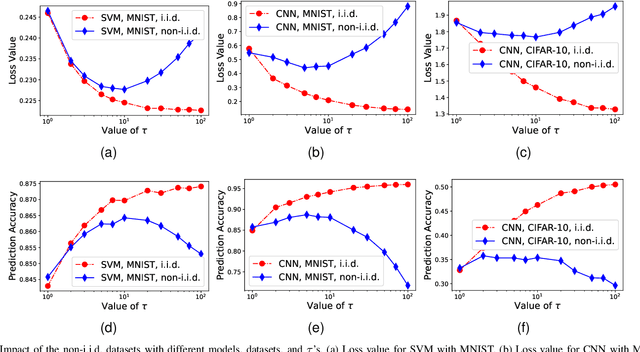
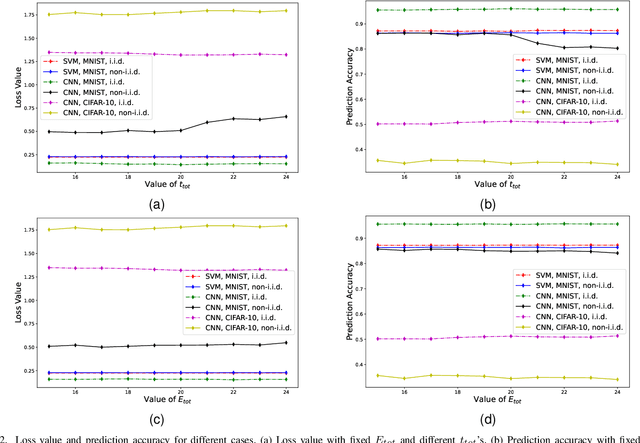
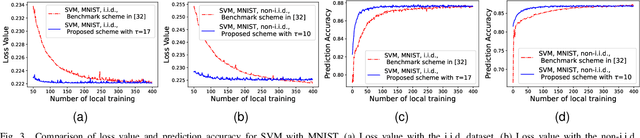
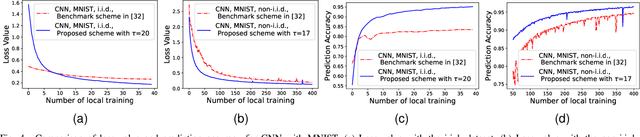
In federated learning (FL), a number of devices train their local models and upload the corresponding parameters or gradients to the base station (BS) to update the global model while protecting their data privacy. However, due to the limited computation and communication resources, the number of local trainings (a.k.a. local update) and that of aggregations (a.k.a. global update) need to be carefully chosen. In this paper, we investigate and analyze the optimal trade-off between the number of local trainings and that of global aggregations to speed up the convergence and enhance the prediction accuracy over the existing works. Our goal is to minimize the global loss function under both the delay and the energy consumption constraints. In order to make the optimization problem tractable, we derive a new and tight upper bound on the loss function, which allows us to obtain closed-form expressions for the number of local trainings and that of global aggregations. Simulation results show that our proposed scheme can achieve a better performance in terms of the prediction accuracy, and converge much faster than the baseline schemes.