 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Feature Interactions from the Perspective of Quadratic Neural Networks for Click-through Rate Prediction
May 23, 2025Hadamard Product (HP) has long been a cornerstone in click-through rate (CTR) prediction tasks due to its simplicity, effectiveness, and ability to capture feature interactions without additional parameters. However, the underlying reasons for its effectiveness remain unclear. In this paper, we revisit HP from the perspective of Quadratic Neural Networks (QNN), which leverage quadratic interaction terms to model complex feature relationships. We further reveal QNN's ability to expand the feature space and provide smooth nonlinear approximations without relying on activation functions. Meanwhile, we find that traditional post-activation does not further improve the performance of the QNN. Instead, mid-activation is a more suitable alternative. Through theoretical analysis and empirical evaluation of 25 QNN neuron formats, we identify a good-performing variant and make further enhancements on it. Specifically, we propose the Multi-Head Khatri-Rao Product as a superior alternative to HP and a Self-Ensemble Loss with dynamic ensemble capability within the same network to enhance computational efficiency and performance. Ultimately, we propose a novel neuron format, QNN-alpha, which is tailored for CTR prediction tasks. Experimental results show that QNN-alpha achieves new state-of-the-art performance on six public datasets while maintaining low inference latency, good scalability, and excellent compatibility. The code, running logs, and detailed hyperparameter configurations are available at: https://github.com/salmon1802/QNN.
Quadratic Interest Network for Multimodal Click-Through Rate Prediction
Apr 24, 2025Multimodal click-through rate (CTR) prediction is a key technique in industrial recommender systems. It leverages heterogeneous modalities such as text, images, and behavioral logs to capture high-order feature interactions between users and items, thereby enhancing the system's understanding of user interests and its ability to predict click behavior. The primary challenge in this field lies in effectively utilizing the rich semantic information from multiple modalities while satisfying the low-latency requirements of online inference in real-world applications. To foster progress in this area, the Multimodal CTR Prediction Challenge Track of the WWW 2025 EReL@MIR Workshop formulates the problem into two tasks: (1) Task 1 of Multimodal Item Embedding: this task aims to explore multimodal information extraction and item representation learning methods that enhance recommendation tasks; and (2) Task 2 of Multimodal CTR Prediction: this task aims to explore what multimodal recommendation model can effectively leverage multimodal embedding features and achieve better performance. In this paper, we propose a novel model for Task 2, named Quadratic Interest Network (QIN) for Multimodal CTR Prediction. Specifically, QIN employs adaptive sparse target attention to extract multimodal user behavior features, and leverages Quadratic Neural Networks to capture high-order feature interactions. As a result, QIN achieved an AUC of 0.9798 on the leaderboard and ranked second in the competition. The model code, training logs, hyperparameter configurations, and checkpoints are available at https://github.com/salmon1802/QIN.
Ensemble Learning via Knowledge Transfer for CTR Prediction
Nov 25, 2024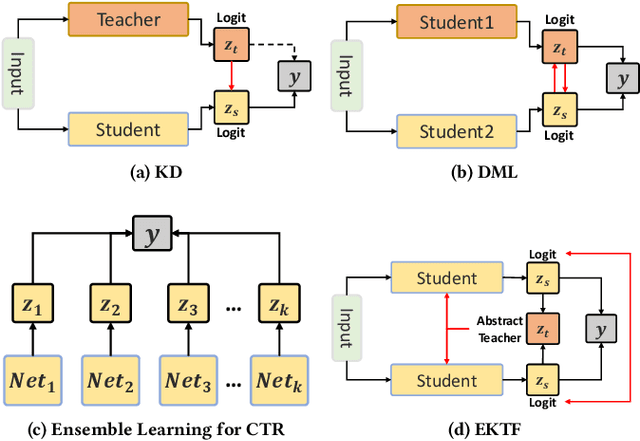
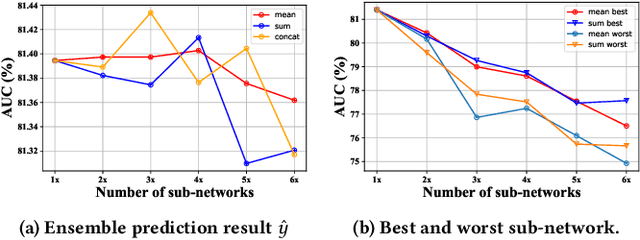
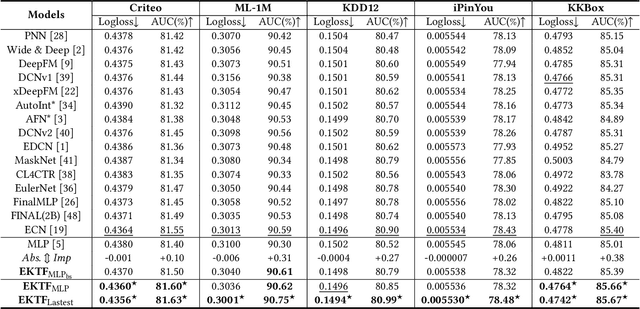
Click-through rate (CTR) prediction plays a critical role in recommender systems and web searches. While many existing methods utilize ensemble learning to improve model performance, they typically limit the ensemble to two or three sub-networks, with little exploration of larger ensembles. In this paper, we investigate larger ensemble networks and find three inherent limitations in commonly used ensemble learning method: (1) performance degradation with more networks; (2) sharp decline and high variance in sub-network performance; (3) large discrepancies between sub-network and ensemble predictions. To simultaneously address the above limitations, this paper investigates potential solutions from the perspectives of Knowledge Distillation (KD) and Deep Mutual Learning (DML). Based on the empirical performance of these methods, we combine them to propose a novel model-agnostic Ensemble Knowledge Transfer Framework (EKTF). Specifically, we employ the collective decision-making of the students as an abstract teacher to guide each student (sub-network) towards more effective learning. Additionally, we encourage mutual learning among students to enable knowledge acquisition from different views. To address the issue of balancing the loss hyperparameters, we design a novel examination mechanism to ensure tailored teaching from teacher-to-student and selective learning in peer-to-peer. Experimental results on five real-world datasets demonstrate the effectiveness and compatibility of EKTF. The code, running logs, and detailed hyperparameter configurations are available at: https://github.com/salmon1802/EKTF.
Feature Interaction Fusion Self-Distillation Network For CTR Prediction
Nov 13, 2024


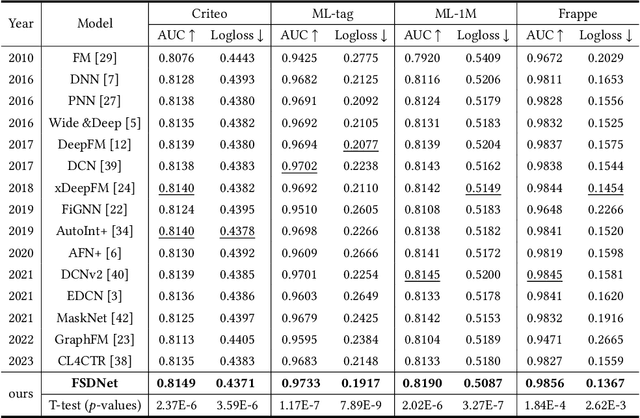
Click-Through Rate (CTR) prediction plays a vital role in recommender systems, online advertising, and search engines. Most of the current approaches model feature interactions through stacked or parallel structures, with some employing knowledge distillation for model compression. However, we observe some limitations with these approaches: (1) In parallel structure models, the explicit and implicit components are executed independently and simultaneously, which leads to insufficient information sharing within the feature set. (2) The introduction of knowledge distillation technology brings about the problems of complex teacher-student framework design and low knowledge transfer efficiency. (3) The dataset and the process of constructing high-order feature interactions contain significant noise, which limits the model's effectiveness. To address these limitations, we propose FSDNet, a CTR prediction framework incorporating a plug-and-play fusion self-distillation module. Specifically, FSDNet forms connections between explicit and implicit feature interactions at each layer, enhancing the sharing of information between different features. The deepest fusion layer is then used as the teacher model, utilizing self-distillation to guide the training of shallow layers. Empirical evaluation across four benchmark datasets validates the framework's efficacy and generalization capabilities. The code is available on https://anonymous.4open.science/r/FSDNet.
DCNv3: Towards Next Generation Deep Cross Network for CTR Prediction
Jul 19, 2024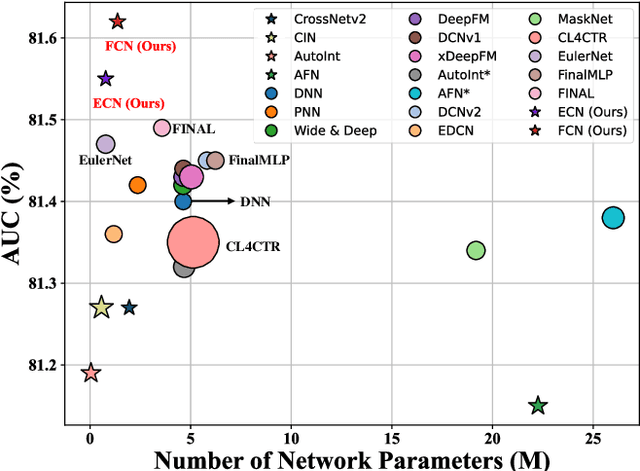

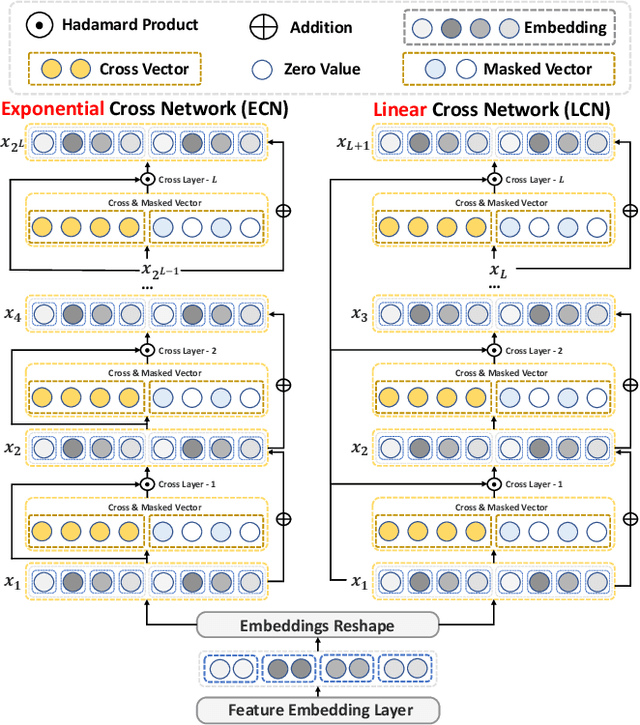

Deep & Cross Network and its derivative models have become an important paradigm in click-through rate (CTR) prediction due to their effective balance between computational cost and performance. However, these models face four major limitations: (1) while most models claim to capture high-order feature interactions, they often do so implicitly and non-interpretably through deep neural networks (DNN), which limits the trustworthiness of the model's predictions; (2) the performance of existing explicit feature interaction methods is often weaker than that of implicit DNN, undermining their necessity; (3) many models fail to adaptively filter noise while enhancing the order of feature interactions; (4) the fusion methods of most models cannot provide suitable supervision signals for their different interaction methods. To address the identified limitations, this paper proposes the next generation Deep Cross Network (DCNv3) and Shallow & Deep Cross Network (SDCNv3). These models ensure interpretability in feature interaction modeling while exponentially increasing the order of feature interactions to achieve genuine Deep Crossing rather than just Deep & Cross. Additionally, we employ a Self-Mask operation to filter noise and reduce the number of parameters in the cross network by half. In the fusion layer, we use a simple yet effective loss weight calculation method called Tri-BCE to provide appropriate supervision signals. Comprehensive experiments on six datasets demonstrate the effectiveness, efficiency, and interpretability of DCNv3 and SDCNv3. The code, running logs, and detailed hyperparameter configurations are available at: https://anonymous.4open.science/r/DCNv3-E352.
Dual-domain Collaborative Denoising for Social Recommendation
May 08, 2024

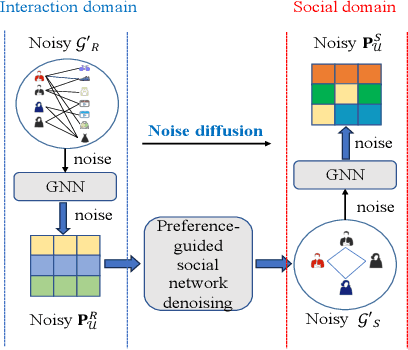
Social recommendation leverages social network to complement user-item interaction data for recommendation task, aiming to mitigate the data sparsity issue in recommender systems. However, existing social recommendation methods encounter the following challenge: both social network and interaction data contain substaintial noise, and the propagation of such noise through Graph Neural Networks (GNNs) not only fails to enhance recommendation performance but may also interfere with the model's normal training. Despite the importance of denoising for social network and interaction data, only a limited number of studies have considered the denoising for social network and all of them overlook that for interaction data, hindering the denoising effect and recommendation performance. Based on this, we propose a novel model called Dual-domain Collaborative Denoising for Social Recommendation ($\textbf{DCDSR}$). DCDSR comprises two primary modules: the structure-level collaborative denoising module and the embedding-space collaborative denoising module. In the structure-level collaborative denoising module, information from interaction domain is first employed to guide social network denoising. Subsequently, the denoised social network is used to supervise the denoising for interaction data. The embedding-space collaborative denoising module devotes to resisting the noise cross-domain diffusion problem through contrastive learning with dual-domain embedding collaborative perturbation. Additionally, a novel contrastive learning strategy, named Anchor-InfoNCE, is introduced to better harness the denoising capability of contrastive learning. Evaluating our model on three real-world datasets verifies that DCDSR has a considerable denoising effect, thus outperforms the state-of-the-art social recommendation methods.
TF4CTR: Twin Focus Framework for CTR Prediction via Adaptive Sample Differentiation
May 06, 2024
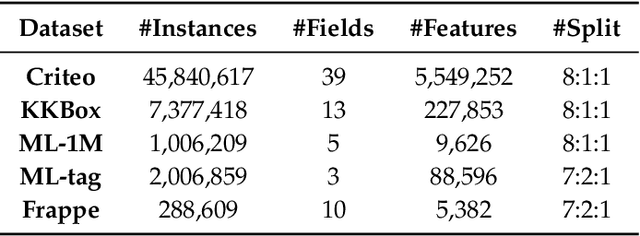

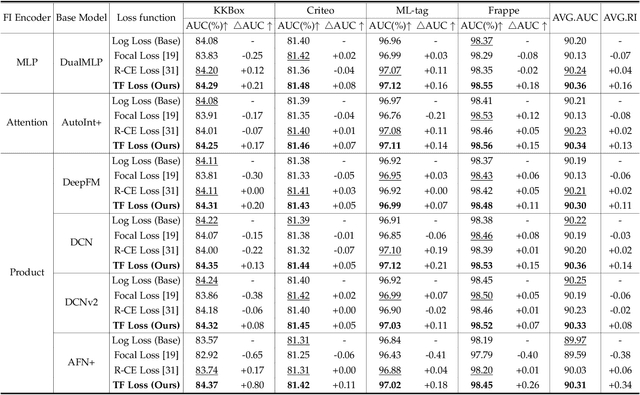
Effective feature interaction modeling is critical for enhancing the accuracy of click-through rate (CTR) prediction in industrial recommender systems. Most of the current deep CTR models resort to building complex network architectures to better capture intricate feature interactions or user behaviors. However, we identify two limitations in these models: (1) the samples given to the model are undifferentiated, which may lead the model to learn a larger number of easy samples in a single-minded manner while ignoring a smaller number of hard samples, thus reducing the model's generalization ability; (2) differentiated feature interaction encoders are designed to capture different interactions information but receive consistent supervision signals, thereby limiting the effectiveness of the encoder. To bridge the identified gaps, this paper introduces a novel CTR prediction framework by integrating the plug-and-play Twin Focus (TF) Loss, Sample Selection Embedding Module (SSEM), and Dynamic Fusion Module (DFM), named the Twin Focus Framework for CTR (TF4CTR). Specifically, the framework employs the SSEM at the bottom of the model to differentiate between samples, thereby assigning a more suitable encoder for each sample. Meanwhile, the TF Loss provides tailored supervision signals to both simple and complex encoders. Moreover, the DFM dynamically fuses the feature interaction information captured by the encoders, resulting in more accurate predictions. Experiments on five real-world datasets confirm the effectiveness and compatibility of the framework, demonstrating its capacity to enhance various representative baselines in a model-agnostic manner. To facilitate reproducible research, our open-sourced code and detailed running logs will be made available at: https://github.com/salmon1802/TF4CTR.
CETN: Contrast-enhanced Through Network for CTR Prediction
Dec 15, 2023Click-through rate (CTR) Prediction is a crucial task in personalized information retrievals, such as industrial recommender systems, online advertising, and web search. Most existing CTR Prediction models utilize explicit feature interactions to overcome the performance bottleneck of implicit feature interactions. Hence, deep CTR models based on parallel structures (e.g., DCN, FinalMLP, xDeepFM) have been proposed to obtain joint information from different semantic spaces. However, these parallel subcomponents lack effective supervisory signals, making it challenging to efficiently capture valuable multi-views feature interaction information in different semantic spaces. To address this issue, we propose a simple yet effective novel CTR model: Contrast-enhanced Through Network for CTR (CETN), so as to ensure the diversity and homogeneity of feature interaction information. Specifically, CETN employs product-based feature interactions and the augmentation (perturbation) concept from contrastive learning to segment different semantic spaces, each with distinct activation functions. This improves diversity in the feature interaction information captured by the model. Additionally, we introduce self-supervised signals and through connection within each semantic space to ensure the homogeneity of the captured feature interaction information. The experiments and research conducted on four real datasets demonstrate that our model consistently outperforms twenty baseline models in terms of AUC and Logloss.
CartoMark: a benchmark dataset for map pattern recognition and 1 map content retrieval with machine intelligence
Dec 14, 2023



Maps are fundamental medium to visualize and represent the real word in a simple and 16 philosophical way. The emergence of the 3rd wave information has made a proportion of maps are available to be generated ubiquitously, which would significantly enrich the dimensions and perspectives to understand the characteristics of the real world. However, a majority of map dataset have never been discovered, acquired and effectively used, and the map data used in many applications might not be completely fitted for the authentic demands of these applications. This challenge is emerged due to the lack of numerous well-labelled benchmark datasets for implementing the deep learning approaches into identifying complicated map content. Thus, we develop a large-scale benchmark dataset that includes well-labelled dataset for map text annotation recognition, map scene classification, map super-resolution reconstruction, and map style transferring. Furthermore, these well-labelled datasets would facilitate the state-of-the-art machine intelligence technologies to conduct map feature detection, map pattern recognition and map content retrieval. We hope our efforts would be useful for AI-enhanced cartographical applications.
FedECA: A Federated External Control Arm Method for Causal Inference with Time-To-Event Data in Distributed Settings
Nov 28, 2023External control arms (ECA) can inform the early clinical development of experimental drugs and provide efficacy evidence for regulatory approval in non-randomized settings. However, the main challenge of implementing ECA lies in accessing real-world data or historical clinical trials. Indeed, data sharing is often not feasible due to privacy considerations related to data leaving the original collection centers, along with pharmaceutical companies' competitive motives. In this paper, we leverage a privacy-enhancing technology called federated learning (FL) to remove some of the barriers to data sharing. We introduce a federated learning inverse probability of treatment weighted (IPTW) method for time-to-event outcomes called FedECA which eases the implementation of ECA by limiting patients' data exposure. We show with extensive experiments that FedECA outperforms its closest competitor, matching-adjusted indirect comparison (MAIC), in terms of statistical power and ability to balance the treatment and control groups. To encourage the use of such methods, we publicly release our code which relies on Substra, an open-source FL software with proven experience in privacy-sensitive contexts.