 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest Arm Identification with LLM Judges and Limited Human
Jan 29, 2026We study fixed-confidence best-arm identification (BAI) where a cheap but potentially biased proxy (e.g., LLM judge) is available for every sample, while an expensive ground-truth label can only be acquired selectively when using a human for auditing. Unlike classical multi-fidelity BAI, the proxy is biased (arm- and context-dependent) and ground truth is selectively observed. Consequently, standard multi-fidelity methods can mis-select the best arm, and uniform auditing, though accurate, wastes scarce resources and is inefficient. We prove that without bias correction and propensity adjustment, mis-selection probability may not vanish (even with unlimited proxy data). We then develop an estimator for the mean of each arm that combines proxy scores with inverse-propensity-weighted residuals and form anytime-valid confidence sequences for that estimator. Based on the estimator and confidence sequence, we propose an algorithm that adaptively selects and audits arms. The algorithm concentrates audits on unreliable contexts and close arms and we prove that a plug-in Neyman rule achieves near-oracle audit efficiency. Numerical experiments confirm the theoretical guarantees and demonstrate the superior empirical performance of the proposed algorithm.
Quadratic Interest Network for Multimodal Click-Through Rate Prediction
Apr 24, 2025Multimodal click-through rate (CTR) prediction is a key technique in industrial recommender systems. It leverages heterogeneous modalities such as text, images, and behavioral logs to capture high-order feature interactions between users and items, thereby enhancing the system's understanding of user interests and its ability to predict click behavior. The primary challenge in this field lies in effectively utilizing the rich semantic information from multiple modalities while satisfying the low-latency requirements of online inference in real-world applications. To foster progress in this area, the Multimodal CTR Prediction Challenge Track of the WWW 2025 EReL@MIR Workshop formulates the problem into two tasks: (1) Task 1 of Multimodal Item Embedding: this task aims to explore multimodal information extraction and item representation learning methods that enhance recommendation tasks; and (2) Task 2 of Multimodal CTR Prediction: this task aims to explore what multimodal recommendation model can effectively leverage multimodal embedding features and achieve better performance. In this paper, we propose a novel model for Task 2, named Quadratic Interest Network (QIN) for Multimodal CTR Prediction. Specifically, QIN employs adaptive sparse target attention to extract multimodal user behavior features, and leverages Quadratic Neural Networks to capture high-order feature interactions. As a result, QIN achieved an AUC of 0.9798 on the leaderboard and ranked second in the competition. The model code, training logs, hyperparameter configurations, and checkpoints are available at https://github.com/salmon1802/QIN.
DCNv3: Towards Next Generation Deep Cross Network for CTR Prediction
Jul 19, 2024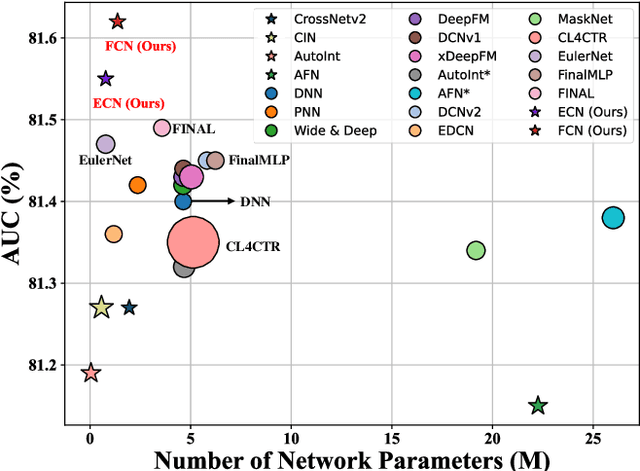

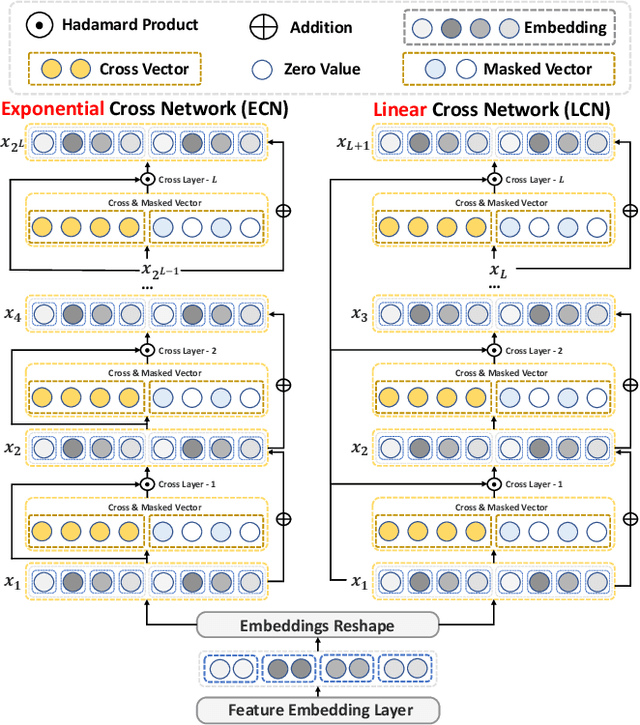

Deep & Cross Network and its derivative models have become an important paradigm in click-through rate (CTR) prediction due to their effective balance between computational cost and performance. However, these models face four major limitations: (1) while most models claim to capture high-order feature interactions, they often do so implicitly and non-interpretably through deep neural networks (DNN), which limits the trustworthiness of the model's predictions; (2) the performance of existing explicit feature interaction methods is often weaker than that of implicit DNN, undermining their necessity; (3) many models fail to adaptively filter noise while enhancing the order of feature interactions; (4) the fusion methods of most models cannot provide suitable supervision signals for their different interaction methods. To address the identified limitations, this paper proposes the next generation Deep Cross Network (DCNv3) and Shallow & Deep Cross Network (SDCNv3). These models ensure interpretability in feature interaction modeling while exponentially increasing the order of feature interactions to achieve genuine Deep Crossing rather than just Deep & Cross. Additionally, we employ a Self-Mask operation to filter noise and reduce the number of parameters in the cross network by half. In the fusion layer, we use a simple yet effective loss weight calculation method called Tri-BCE to provide appropriate supervision signals. Comprehensive experiments on six datasets demonstrate the effectiveness, efficiency, and interpretability of DCNv3 and SDCNv3. The code, running logs, and detailed hyperparameter configurations are available at: https://anonymous.4open.science/r/DCNv3-E352.