 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote Sensing ChatGPT: Solving Remote Sensing Tasks with ChatGPT and Visual Models
Jan 17, 2024

Recently, the flourishing large language models(LLM), especially ChatGPT, have shown exceptional performance in language understanding, reasoning, and interaction, attracting users and researchers from multiple fields and domains. Although LLMs have shown great capacity to perform human-like task accomplishment in natural language and natural image, their potential in handling remote sensing interpretation tasks has not yet been fully explored. Moreover, the lack of automation in remote sensing task planning hinders the accessibility of remote sensing interpretation techniques, especially to non-remote sensing experts from multiple research fields. To this end, we present Remote Sensing ChatGPT, an LLM-powered agent that utilizes ChatGPT to connect various AI-based remote sensing models to solve complicated interpretation tasks. More specifically, given a user request and a remote sensing image, we utilized ChatGPT to understand user requests, perform task planning according to the tasks' functions, execute each subtask iteratively, and generate the final response according to the output of each subtask. Considering that LLM is trained with natural language and is not capable of directly perceiving visual concepts as contained in remote sensing images, we designed visual cues that inject visual information into ChatGPT. With Remote Sensing ChatGPT, users can simply send a remote sensing image with the corresponding request, and get the interpretation results as well as language feedback from Remote Sensing ChatGPT. Experiments and examples show that Remote Sensing ChatGPT can tackle a wide range of remote sensing tasks and can be extended to more tasks with more sophisticated models such as the remote sensing foundation model. The code and demo of Remote Sensing ChatGPT is publicly available at https://github.com/HaonanGuo/Remote-Sensing-ChatGPT .
Radar detection of wake vortex behind the aircraft: the detection range problem
Dec 27, 2023In this study, we showcased the detection of the wake vortex produced by a medium aircraft at distances exceeding 10 km using an X-band pulse-Doppler radar. We analyzed radar signals within the range profiles behind a Boeing 737 aircraft on February 7, 2021, within the airspace of the Runway Protection Zone (RPZ) at Tianhe Airport, Wuhan, China. The findings revealed that the wake vortex extended up to 6 km from the aircraft, which is 10 km from the radar, displaying distinct stages characterized by scattering patterns and Doppler signatures. Despite the wake vortex exhibiting a scattering power approximately 10 dB lower than that of the aircraft, its Doppler Signal-to-Clutter Ratio (DSCR) values were only 5 dB lower, indicating a notably strong scattering power within a single radar bin. Additionally, certain radar parameters proved inconsistent in the stable detection and tracking of wake vortex, aligning with our earlier concept of cognitive micro-Doppler radar.
An introduction to radar Automatic Target Recognition (ATR) technology in ground-based radar systems
Oct 23, 2023This paper presents a brief examination of Automatic Target Recognition (ATR) technology within ground-based radar systems. It offers a lucid comprehension of the ATR concept, delves into its historical milestones, and categorizes ATR methods according to different scattering regions. By incorporating ATR solutions into radar systems, this study demonstrates the expansion of radar detection ranges and the enhancement of tracking capabilities, leading to superior situational awareness. Drawing insights from the Russo-Ukrainian War, the paper highlights three pressing radar applications that urgently necessitate ATR technology: detecting stealth aircraft, countering small drones, and implementing anti-jamming measures. Anticipating the next wave of radar ATR research, the study predicts a surge in cognitive radar and machine learning (ML)-driven algorithms. These emerging methodologies aspire to confront challenges associated with system adaptation, real-time recognition, and environmental adaptability. Ultimately, ATR stands poised to revolutionize conventional radar systems, ushering in an era of 4D sensing capabilities.
Formation Wing-Beat Modulation : A Tool for Quantifying Bird Flocks Using Radar Micro-Doppler Signals
Sep 27, 2023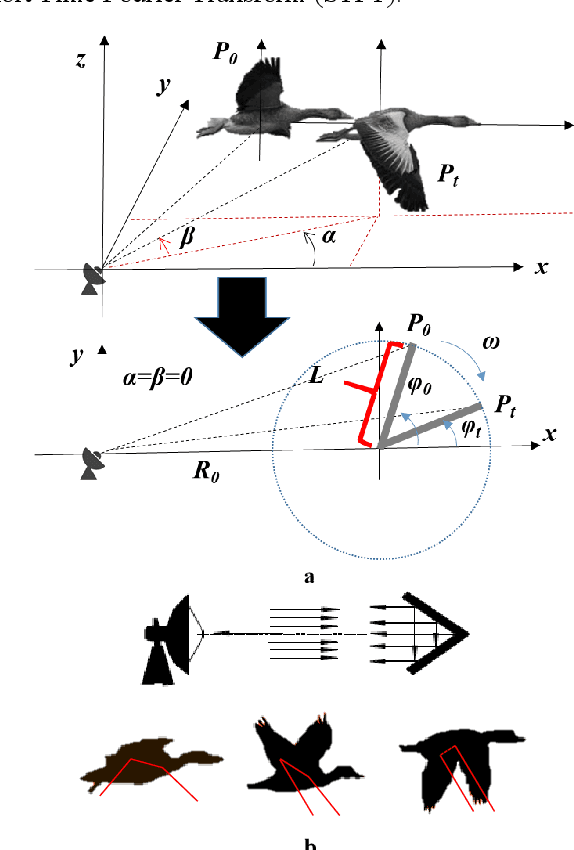
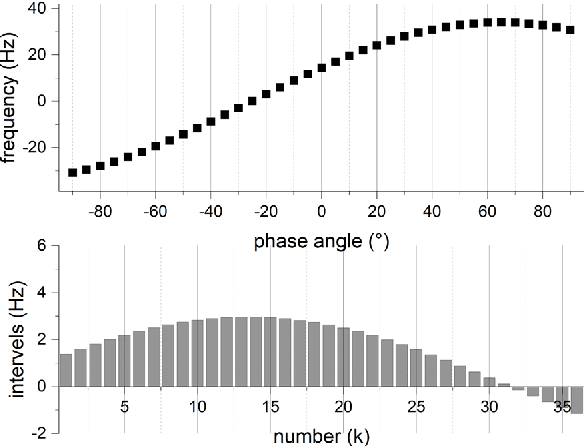
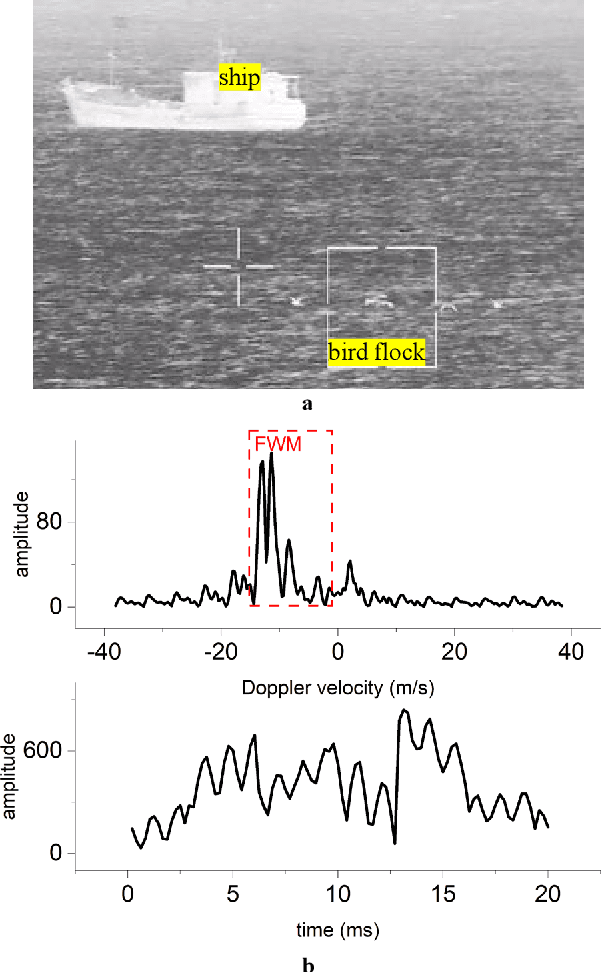
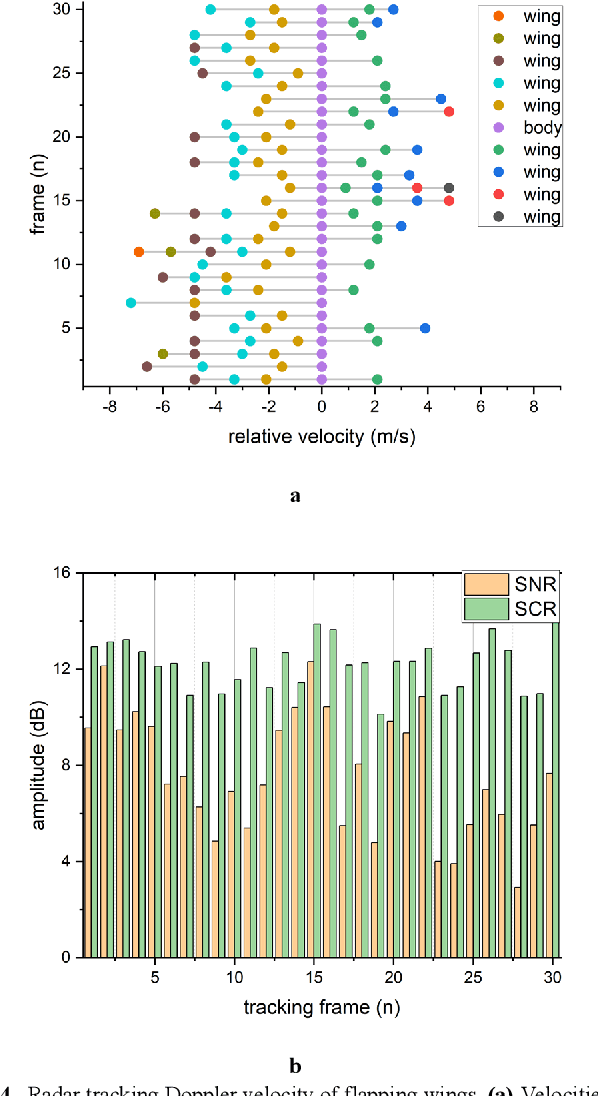
Radar echoes from bird flocks contain modulation signals, which we find are produced by the flapping gaits of birds in the flock, resulting in a group of spectral peaks with similar amplitudes spaced at a specific interval. We call this the formation wing-beat modulation (FWM) effect. FWM signals are micro-Doppler modulated by flapping wings and are related to the bird number, wing-beat frequency, and flight phasing strategy. Our X-band radar data show that FWM signals exist in radar signals of a seagull flock, providing tools for quantifying the bird number and estimating the mean wingbeat rate of birds. This new finding could aid in research on the quantification of bird migration numbers and estimation of bird flight behavior in radar ornithology and aero-ecology.
Introduction to Drone Detection Radar with Emphasis on Automatic Target Recognition (ATR) technology
Jul 19, 2023This paper discusses the challenges of detecting and categorizing small drones with radar automatic target recognition (ATR) technology. The authors suggest integrating ATR capabilities into drone detection radar systems to improve performance and manage emerging threats. The study focuses primarily on drones in Group 1 and 2. The paper highlights the need to consider kinetic features and signal signatures, such as micro-Doppler, in ATR techniques to efficiently recognize small drones. The authors also present a comprehensive drone detection radar system design that balances detection and tracking requirements, incorporating parameter adjustment based on scattering region theory. They offer an example of a performance improvement achieved using feedback and situational awareness mechanisms with the integrated ATR capabilities. Furthermore, the paper examines challenges related to one-way attack drones and explores the potential of cognitive radar as a solution. The integration of ATR capabilities transforms a 3D radar system into a 4D radar system, resulting in improved drone detection performance. These advancements are useful in military, civilian, and commercial applications, and ongoing research and development efforts are essential to keep radar systems effective and ready to detect, track, and respond to emerging threats.
An Improved End-to-End Multi-Target Tracking Method Based on Transformer Self-Attention
Nov 11, 2022


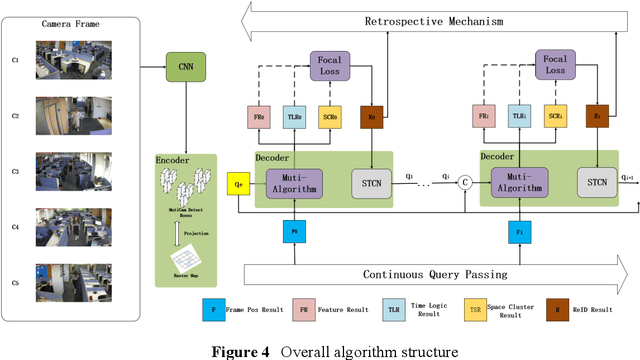
This study proposes an improved end-to-end multi-target tracking algorithm that adapts to multi-view multi-scale scenes based on the self-attentive mechanism of the transformer's encoder-decoder structure. A multi-dimensional feature extraction backbone network is combined with a self-built semantic raster map, which is stored in the encoder for correlation and generates target position encoding and multi-dimensional feature vectors. The decoder incorporates four methods: spatial clustering and semantic filtering of multi-view targets, dynamic matching of multi-dimensional features, space-time logic-based multi-target tracking, and space-time convergence network (STCN)-based parameter passing. Through the fusion of multiple decoding methods, muti-camera targets are tracked in three dimensions: temporal logic, spatial logic, and feature matching. For the MOT17 dataset, this study's method significantly outperforms the current state-of-the-art method MiniTrackV2 [49] by 2.2% to 0.836 on Multiple Object Tracking Accuracy(MOTA) metric. Furthermore, this study proposes a retrospective mechanism for the first time, and adopts a reverse-order processing method to optimise the historical mislabeled targets for improving the Identification F1-score(IDF1). For the self-built dataset OVIT-MOT01, the IDF1 improves from 0.948 to 0.967, and the Multi-camera Tracking Accuracy(MCTA) improves from 0.878 to 0.909, which significantly improves the continuous tracking accuracy and scene adaptation. This research method introduces a new attentional tracking paradigm which is able to achieve state-of-the-art performance on multi-target tracking (MOT17 and OVIT-MOT01) tasks.
CG-SSD: Corner Guided Single Stage 3D Object Detection from LiDAR Point Cloud
Mar 05, 2022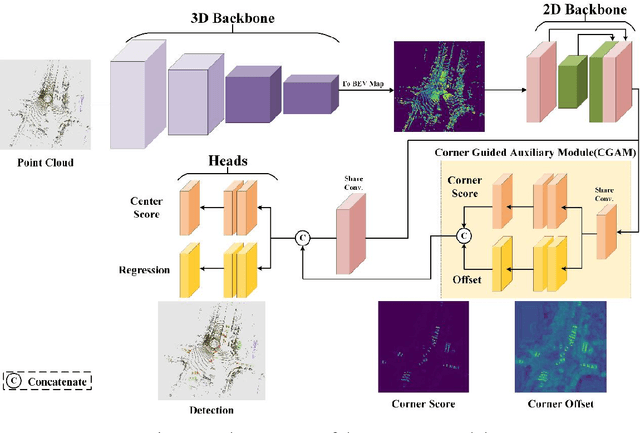
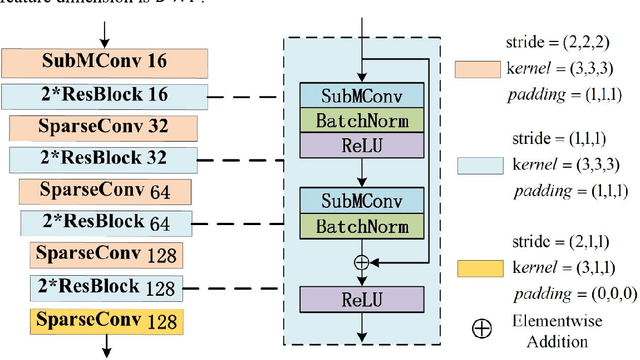
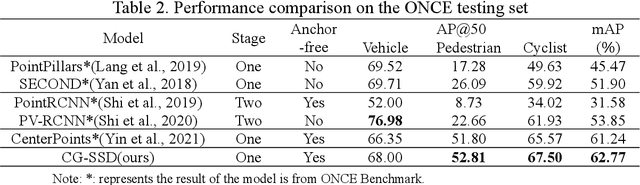
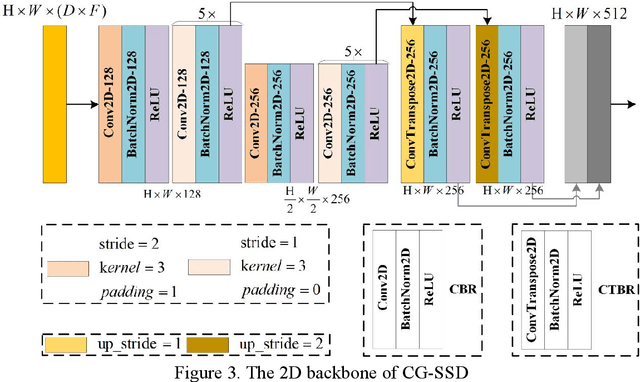
At present, the anchor-based or anchor-free models that use LiDAR point clouds for 3D object detection use the center assigner strategy to infer the 3D bounding boxes. However, in a real world scene, the LiDAR can only acquire a limited object surface point clouds, but the center point of the object does not exist. Obtaining the object by aggregating the incomplete surface point clouds will bring a loss of accuracy in direction and dimension estimation. To address this problem, we propose a corner-guided anchor-free single-stage 3D object detection model (CG-SSD ).Firstly, 3D sparse convolution backbone network composed of residual layers and sub-manifold sparse convolutional layers are used to construct bird's eye view (BEV) features for further deeper feature mining by a lite U-shaped network; Secondly, a novel corner-guided auxiliary module (CGAM) is proposed to incorporate corner supervision signals into the neural network. CGAM is explicitly designed and trained to detect partially visible and invisible corners to obtains a more accurate object feature representation, especially for small or partial occluded objects; Finally, the deep features from both the backbone networks and CGAM module are concatenated and fed into the head module to predict the classification and 3D bounding boxes of the objects in the scene. The experiments demonstrate CG-SSD achieves the state-of-art performance on the ONCE benchmark for supervised 3D object detection using single frame point cloud data, with 62.77%mAP. Additionally, the experiments on ONCE and Waymo Open Dataset show that CGAM can be extended to most anchor-based models which use the BEV feature to detect objects, as a plug-in and bring +1.17%-+14.27%AP improvement.
Aerial Scene Parsing: From Tile-level Scene Classification to Pixel-wise Semantic Labeling
Jan 09, 2022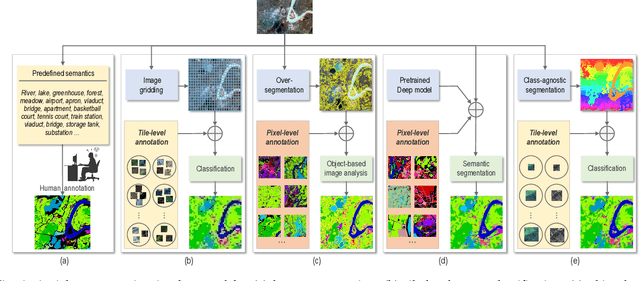

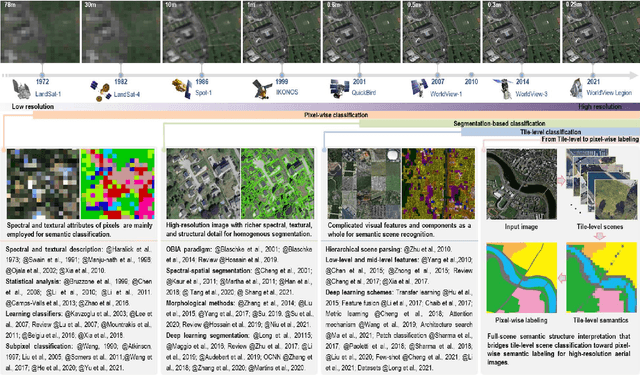

Given an aerial image, aerial scene parsing (ASP) targets to interpret the semantic structure of the image content, e.g., by assigning a semantic label to every pixel of the image. With the popularization of data-driven methods, the past decades have witnessed promising progress on ASP by approaching the problem with the schemes of tile-level scene classification or segmentation-based image analysis, when using high-resolution aerial images. However, the former scheme often produces results with tile-wise boundaries, while the latter one needs to handle the complex modeling process from pixels to semantics, which often requires large-scale and well-annotated image samples with pixel-wise semantic labels. In this paper, we address these issues in ASP, with perspectives from tile-level scene classification to pixel-wise semantic labeling. Specifically, we first revisit aerial image interpretation by a literature review. We then present a large-scale scene classification dataset that contains one million aerial images termed Million-AID. With the presented dataset, we also report benchmarking experiments using classical convolutional neural networks (CNNs). Finally, we perform ASP by unifying the tile-level scene classification and object-based image analysis to achieve pixel-wise semantic labeling. Intensive experiments show that Million-AID is a challenging yet useful dataset, which can serve as a benchmark for evaluating newly developed algorithms. When transferring knowledge from Million-AID, fine-tuning CNN models pretrained on Million-AID perform consistently better than those pretrained ImageNet for aerial scene classification. Moreover, our designed hierarchical multi-task learning method achieves the state-of-the-art pixel-wise classification on the challenging GID, bridging the tile-level scene classification toward pixel-wise semantic labeling for aerial image interpretation.
Spatio-temporal-spectral-angular observation model that integrates observations from UAV and mobile mapping vehicle for better urban mapping
Sep 05, 2021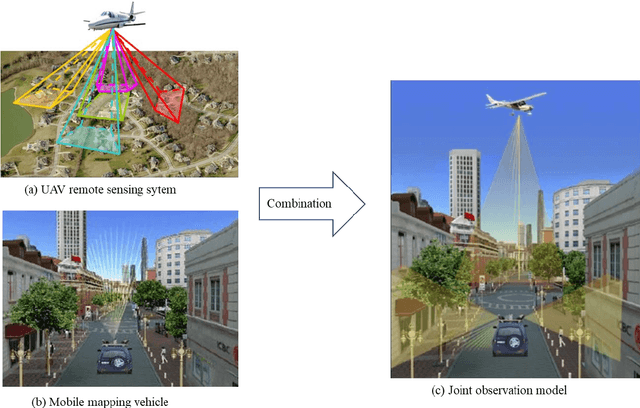
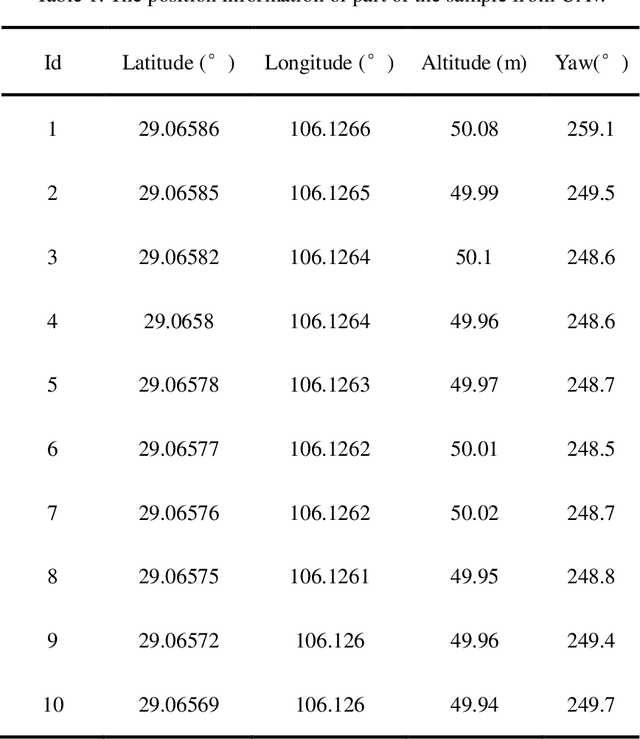

In a complex urban scene, observation from a single sensor unavoidably leads to voids in observations, failing to describe urban objects in a comprehensive manner. In this paper, we propose a spatio-temporal-spectral-angular observation model to integrate observations from UAV and mobile mapping vehicle platform, realizing a joint, coordinated observation operation from both air and ground. We develop a multi-source remote sensing data acquisition system to effectively acquire multi-angle data of complex urban scenes. Multi-source data fusion solves the missing data problem caused by occlusion and achieves accurate, rapid, and complete collection of holographic spatial and temporal information in complex urban scenes. We carried out an experiment on Baisha Town, Chongqing, China and obtained multi-sensor, multi-angle data from UAV and mobile mapping vehicle. We first extracted the point cloud from UAV and then integrated the UAV and mobile mapping vehicle point cloud. The integrated results combined both the characteristic of UAV and mobile mapping vehicle point cloud, confirming the practicability of the proposed joint data acquisition platform and the effectiveness of spatio-temporal-spectral-angular observation model. Compared with the observation from UAV or mobile mapping vehicle alone, the integrated system provides an effective data acquisition solution towards comprehensive urban monitoring.
Signal Acquisition of Luojia-1A Low Earth Orbit Navigation Augmentation System with Software Defined Receiver
May 31, 2021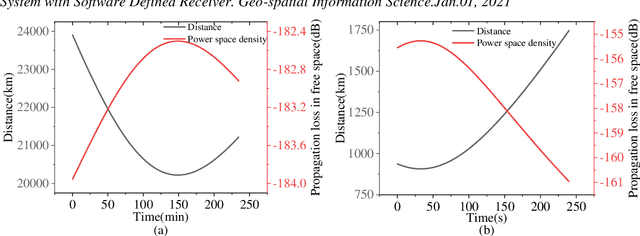
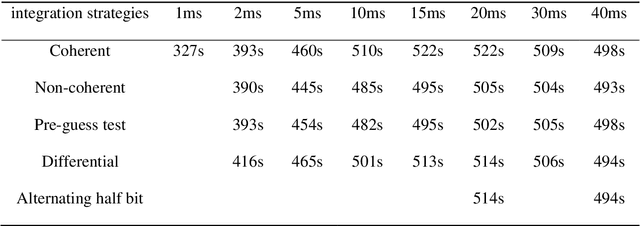
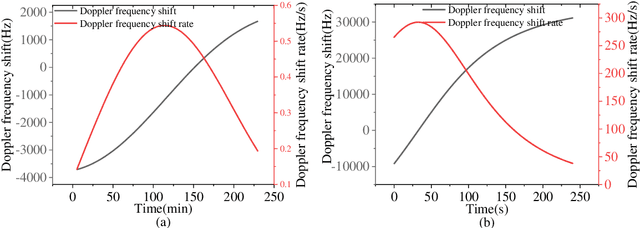
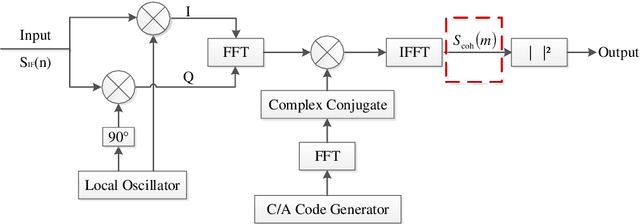
Low earth orbit (LEO) satellite navigation signal can be used as an opportunity signal in case of a Global navigation satellite system (GNSS) outage, or as an enhancement means of traditional GNSS positioning algorithms. No matter which service mode is used, signal acquisition is the prerequisite of providing enhanced LEO navigation service. Compared with the medium orbit satellite, the transit time of the LEO satellite is shorter. Thus, it is of great significance to expand the successful acquisition time range of the LEO signal. Previous studies on LEO signal acquisition are based on simulation data. However, signal acquisition research based on real data is very important. In this work, the signal characteristics of LEO satellite: power space density in free space and the Doppler shift of LEO satellite are individually studied. The unified symbol definitions of several integration algorithms based on the parallel search signal acquisition algorithm are given. To verify these algorithms for LEO signal acquisition, a software-defined receiver (SDR) is developed. The performance of those integration algorithms on expanding the successful acquisition time range is verified by the real data collected from the Luojia-1A satellite. The experimental results show that the integration strategy can expand the successful acquisition time range, and it will not expand indefinitely with the integration duration.