 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCG-SSD: Corner Guided Single Stage 3D Object Detection from LiDAR Point Cloud
Paper and Code
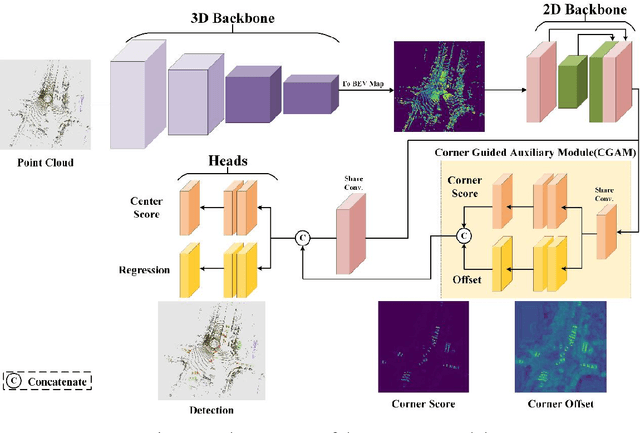
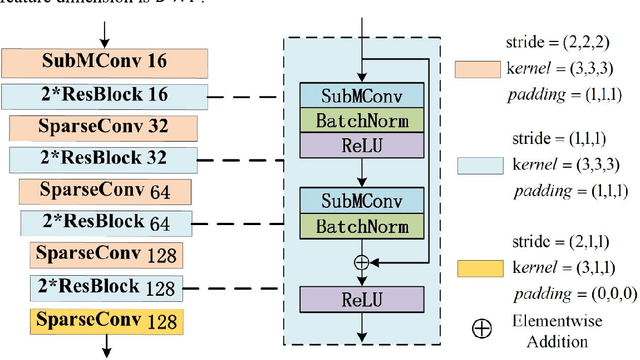
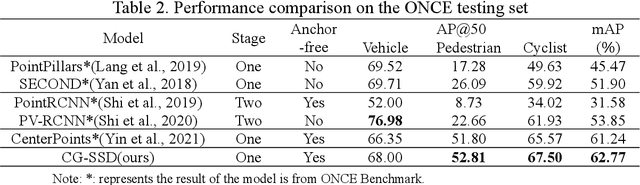
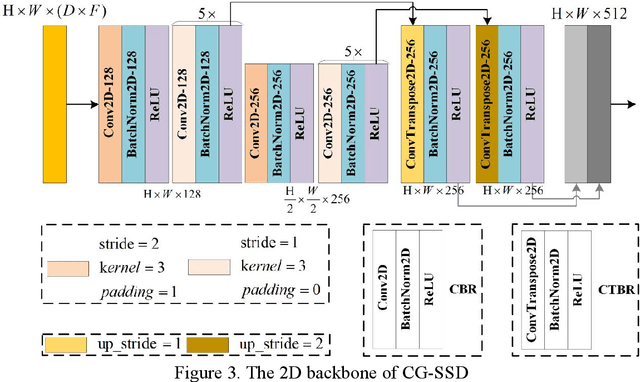
At present, the anchor-based or anchor-free models that use LiDAR point clouds for 3D object detection use the center assigner strategy to infer the 3D bounding boxes. However, in a real world scene, the LiDAR can only acquire a limited object surface point clouds, but the center point of the object does not exist. Obtaining the object by aggregating the incomplete surface point clouds will bring a loss of accuracy in direction and dimension estimation. To address this problem, we propose a corner-guided anchor-free single-stage 3D object detection model (CG-SSD ).Firstly, 3D sparse convolution backbone network composed of residual layers and sub-manifold sparse convolutional layers are used to construct bird's eye view (BEV) features for further deeper feature mining by a lite U-shaped network; Secondly, a novel corner-guided auxiliary module (CGAM) is proposed to incorporate corner supervision signals into the neural network. CGAM is explicitly designed and trained to detect partially visible and invisible corners to obtains a more accurate object feature representation, especially for small or partial occluded objects; Finally, the deep features from both the backbone networks and CGAM module are concatenated and fed into the head module to predict the classification and 3D bounding boxes of the objects in the scene. The experiments demonstrate CG-SSD achieves the state-of-art performance on the ONCE benchmark for supervised 3D object detection using single frame point cloud data, with 62.77%mAP. Additionally, the experiments on ONCE and Waymo Open Dataset show that CGAM can be extended to most anchor-based models which use the BEV feature to detect objects, as a plug-in and bring +1.17%-+14.27%AP improvement.