 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improved End-to-End Multi-Target Tracking Method Based on Transformer Self-Attention
Nov 11, 2022


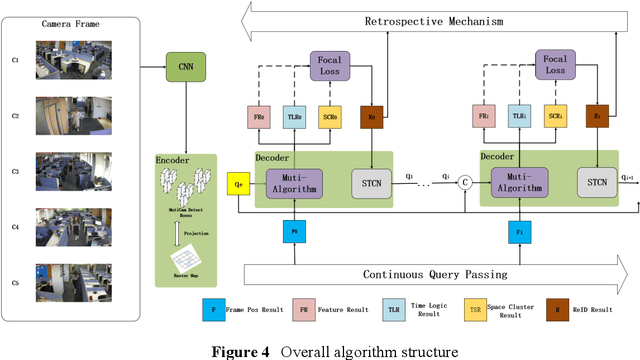
This study proposes an improved end-to-end multi-target tracking algorithm that adapts to multi-view multi-scale scenes based on the self-attentive mechanism of the transformer's encoder-decoder structure. A multi-dimensional feature extraction backbone network is combined with a self-built semantic raster map, which is stored in the encoder for correlation and generates target position encoding and multi-dimensional feature vectors. The decoder incorporates four methods: spatial clustering and semantic filtering of multi-view targets, dynamic matching of multi-dimensional features, space-time logic-based multi-target tracking, and space-time convergence network (STCN)-based parameter passing. Through the fusion of multiple decoding methods, muti-camera targets are tracked in three dimensions: temporal logic, spatial logic, and feature matching. For the MOT17 dataset, this study's method significantly outperforms the current state-of-the-art method MiniTrackV2 [49] by 2.2% to 0.836 on Multiple Object Tracking Accuracy(MOTA) metric. Furthermore, this study proposes a retrospective mechanism for the first time, and adopts a reverse-order processing method to optimise the historical mislabeled targets for improving the Identification F1-score(IDF1). For the self-built dataset OVIT-MOT01, the IDF1 improves from 0.948 to 0.967, and the Multi-camera Tracking Accuracy(MCTA) improves from 0.878 to 0.909, which significantly improves the continuous tracking accuracy and scene adaptation. This research method introduces a new attentional tracking paradigm which is able to achieve state-of-the-art performance on multi-target tracking (MOT17 and OVIT-MOT01) tasks.