 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiMeng-Attention: SOTA Attention Operator is generated by SOTA Attention Algorithm
Jun 14, 2025The attention operator remains a critical performance bottleneck in large language models (LLMs), particularly for long-context scenarios. While FlashAttention is the most widely used and effective GPU-aware acceleration algorithm, it must require time-consuming and hardware-specific manual implementation, limiting adaptability across GPU architectures. Existing LLMs have shown a lot of promise in code generation tasks, but struggle to generate high-performance attention code. The key challenge is it cannot comprehend the complex data flow and computation process of the attention operator and utilize low-level primitive to exploit GPU performance. To address the above challenge, we propose an LLM-friendly Thinking Language (LLM-TL) to help LLMs decouple the generation of high-level optimization logic and low-level implementation on GPU, and enhance LLMs' understanding of attention operator. Along with a 2-stage reasoning workflow, TL-Code generation and translation, the LLMs can automatically generate FlashAttention implementation on diverse GPUs, establishing a self-optimizing paradigm for generating high-performance attention operators in attention-centric algorithms. Verified on A100, RTX8000, and T4 GPUs, the performance of our methods significantly outshines that of vanilla LLMs, achieving a speed-up of up to 35.16x. Besides, our method not only surpasses human-optimized libraries (cuDNN and official library) in most scenarios but also extends support to unsupported hardware and data types, reducing development time from months to minutes compared with human experts.
QiMeng-TensorOp: Automatically Generating High-Performance Tensor Operators with Hardware Primitives
May 08, 2025Computation-intensive tensor operators constitute over 90\% of the computations in Large Language Models (LLMs) and Deep Neural Networks.Automatically and efficiently generating high-performance tensor operators with hardware primitives is crucial for diverse and ever-evolving hardware architectures like RISC-V, ARM, and GPUs, as manually optimized implementation takes at least months and lacks portability.LLMs excel at generating high-level language codes, but they struggle to fully comprehend hardware characteristics and produce high-performance tensor operators. We introduce a tensor-operator auto-generation framework with a one-line user prompt (QiMeng-TensorOp), which enables LLMs to automatically exploit hardware characteristics to generate tensor operators with hardware primitives, and tune parameters for optimal performance across diverse hardware. Experimental results on various hardware platforms, SOTA LLMs, and typical tensor operators demonstrate that QiMeng-TensorOp effectively unleashes the computing capability of various hardware platforms, and automatically generates tensor operators of superior performance. Compared with vanilla LLMs, QiMeng-TensorOp achieves up to $1291 \times$ performance improvement. Even compared with human experts, QiMeng-TensorOp could reach $251 \%$ of OpenBLAS on RISC-V CPUs, and $124 \%$ of cuBLAS on NVIDIA GPUs. Additionally, QiMeng-TensorOp also significantly reduces development costs by $200 \times$ compared with human experts.
Attentional Graph Meta-Learning for Indoor Localization Using Extremely Sparse Fingerprints
Apr 07, 2025

Fingerprint-based indoor localization is often labor-intensive due to the need for dense grids and repeated measurements across time and space. Maintaining high localization accuracy with extremely sparse fingerprints remains a persistent challenge. Existing benchmark methods primarily rely on the measured fingerprints, while neglecting valuable spatial and environmental characteristics. In this paper, we propose a systematic integration of an Attentional Graph Neural Network (AGNN) model, capable of learning spatial adjacency relationships and aggregating information from neighboring fingerprints, and a meta-learning framework that utilizes datasets with similar environmental characteristics to enhance model training. To minimize the labor required for fingerprint collection, we introduce two novel data augmentation strategies: 1) unlabeled fingerprint augmentation using moving platforms, which enables the semi-supervised AGNN model to incorporate information from unlabeled fingerprints, and 2) synthetic labeled fingerprint augmentation through environmental digital twins, which enhances the meta-learning framework through a practical distribution alignment, which can minimize the feature discrepancy between synthetic and real-world fingerprints effectively. By integrating these novel modules, we propose the Attentional Graph Meta-Learning (AGML) model. This novel model combines the strengths of the AGNN model and the meta-learning framework to address the challenges posed by extremely sparse fingerprints. To validate our approach, we collected multiple datasets from both consumer-grade WiFi devices and professional equipment across diverse environments. Extensive experiments conducted on both synthetic and real-world datasets demonstrate that the AGML model-based localization method consistently outperforms all baseline methods using sparse fingerprints across all evaluated metrics.
Emergent Communication for Rules Reasoning
Nov 08, 2023

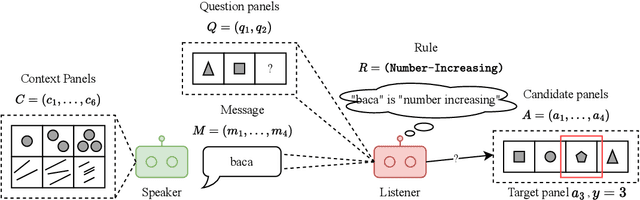

Research on emergent communication between deep-learning-based agents has received extensive attention due to its inspiration for linguistics and artificial intelligence. However, previous attempts have hovered around emerging communication under perception-oriented environmental settings, that forces agents to describe low-level perceptual features intra image or symbol contexts. In this work, inspired by the classic human reasoning test (namely Raven's Progressive Matrix), we propose the Reasoning Game, a cognition-oriented environment that encourages agents to reason and communicate high-level rules, rather than perceived low-level contexts. Moreover, we propose 1) an unbiased dataset (namely rule-RAVEN) as a benchmark to avoid overfitting, 2) and a two-stage curriculum agent training method as a baseline for more stable convergence in the Reasoning Game, where contexts and semantics are bilaterally drifting. Experimental results show that, in the Reasoning Game, a semantically stable and compositional language emerges to solve reasoning problems. The emerged language helps agents apply the extracted rules to the generalization of unseen context attributes, and to the transfer between different context attributes or even tasks.
Context Shift Reduction for Offline Meta-Reinforcement Learning
Nov 07, 2023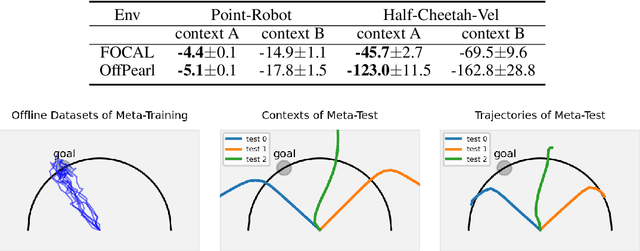

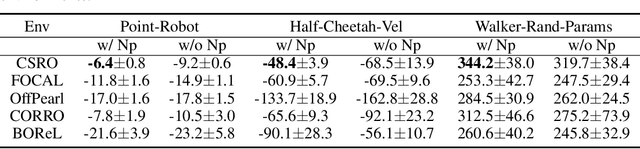
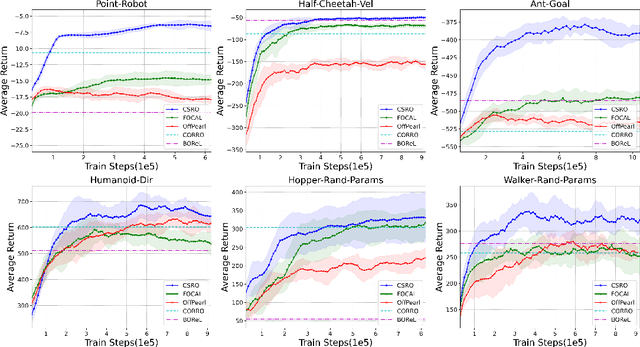
Offline meta-reinforcement learning (OMRL) utilizes pre-collected offline datasets to enhance the agent's generalization ability on unseen tasks. However, the context shift problem arises due to the distribution discrepancy between the contexts used for training (from the behavior policy) and testing (from the exploration policy). The context shift problem leads to incorrect task inference and further deteriorates the generalization ability of the meta-policy. Existing OMRL methods either overlook this problem or attempt to mitigate it with additional information. In this paper, we propose a novel approach called Context Shift Reduction for OMRL (CSRO) to address the context shift problem with only offline datasets. The key insight of CSRO is to minimize the influence of policy in context during both the meta-training and meta-test phases. During meta-training, we design a max-min mutual information representation learning mechanism to diminish the impact of the behavior policy on task representation. In the meta-test phase, we introduce the non-prior context collection strategy to reduce the effect of the exploration policy. Experimental results demonstrate that CSRO significantly reduces the context shift and improves the generalization ability, surpassing previous methods across various challenging domains.
Contrastive Modules with Temporal Attention for Multi-Task Reinforcement Learning
Nov 02, 2023
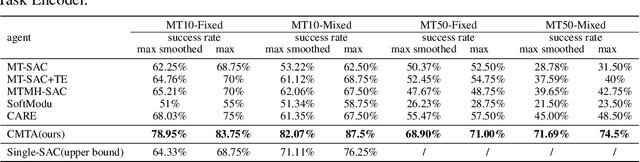
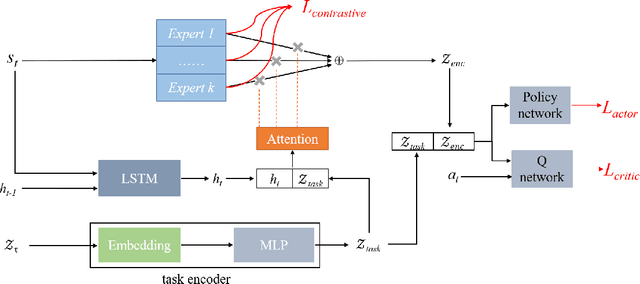
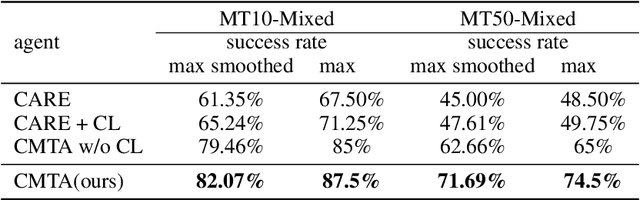
In the field of multi-task reinforcement learning, the modular principle, which involves specializing functionalities into different modules and combining them appropriately, has been widely adopted as a promising approach to prevent the negative transfer problem that performance degradation due to conflicts between tasks. However, most of the existing multi-task RL methods only combine shared modules at the task level, ignoring that there may be conflicts within the task. In addition, these methods do not take into account that without constraints, some modules may learn similar functions, resulting in restricting the model's expressiveness and generalization capability of modular methods. In this paper, we propose the Contrastive Modules with Temporal Attention(CMTA) method to address these limitations. CMTA constrains the modules to be different from each other by contrastive learning and combining shared modules at a finer granularity than the task level with temporal attention, alleviating the negative transfer within the task and improving the generalization ability and the performance for multi-task RL. We conducted the experiment on Meta-World, a multi-task RL benchmark containing various robotics manipulation tasks. Experimental results show that CMTA outperforms learning each task individually for the first time and achieves substantial performance improvements over the baselines.
Efficient Symbolic Policy Learning with Differentiable Symbolic Expression
Nov 02, 2023



Deep reinforcement learning (DRL) has led to a wide range of advances in sequential decision-making tasks. However, the complexity of neural network policies makes it difficult to understand and deploy with limited computational resources. Currently, employing compact symbolic expressions as symbolic policies is a promising strategy to obtain simple and interpretable policies. Previous symbolic policy methods usually involve complex training processes and pre-trained neural network policies, which are inefficient and limit the application of symbolic policies. In this paper, we propose an efficient gradient-based learning method named Efficient Symbolic Policy Learning (ESPL) that learns the symbolic policy from scratch in an end-to-end way. We introduce a symbolic network as the search space and employ a path selector to find the compact symbolic policy. By doing so we represent the policy with a differentiable symbolic expression and train it in an off-policy manner which further improves the efficiency. In addition, in contrast with previous symbolic policies which only work in single-task RL because of complexity, we expand ESPL on meta-RL to generate symbolic policies for unseen tasks. Experimentally, we show that our approach generates symbolic policies with higher performance and greatly improves data efficiency for single-task RL. In meta-RL, we demonstrate that compared with neural network policies the proposed symbolic policy achieves higher performance and efficiency and shows the potential to be interpretable.
Formation Wing-Beat Modulation : A Tool for Quantifying Bird Flocks Using Radar Micro-Doppler Signals
Sep 27, 2023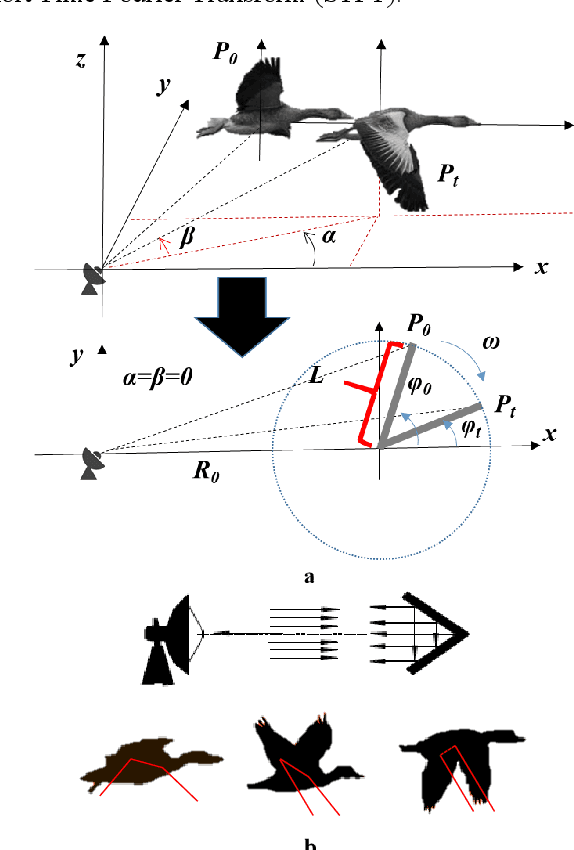
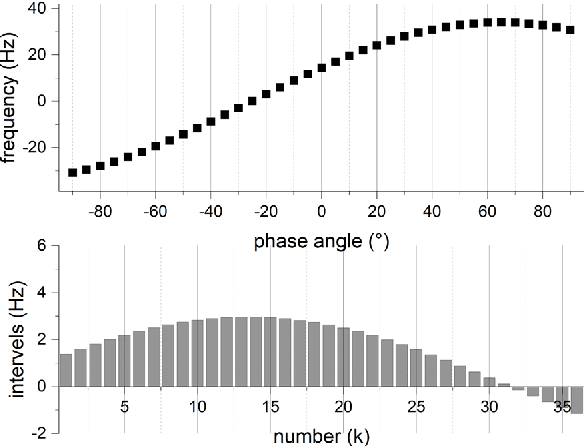
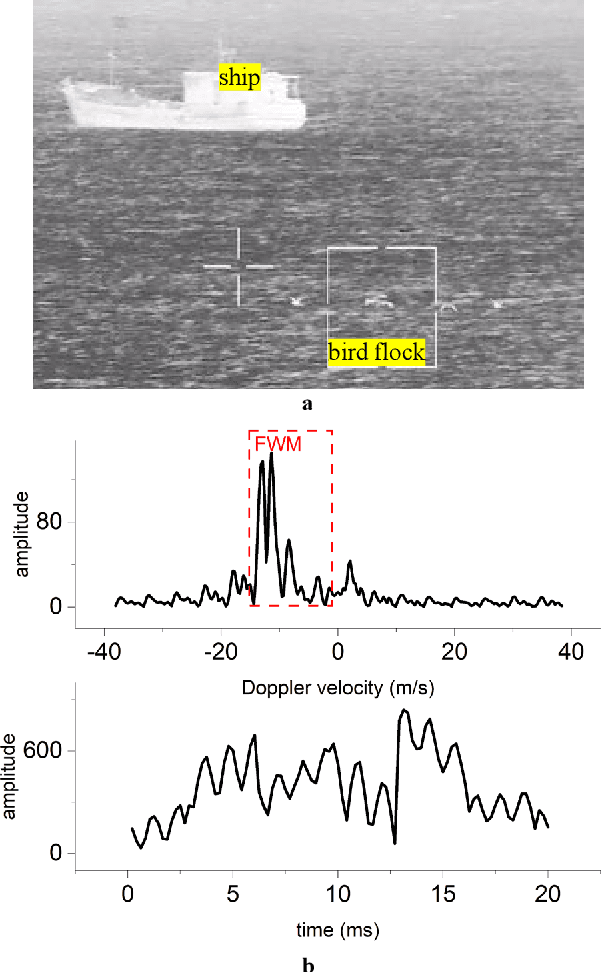
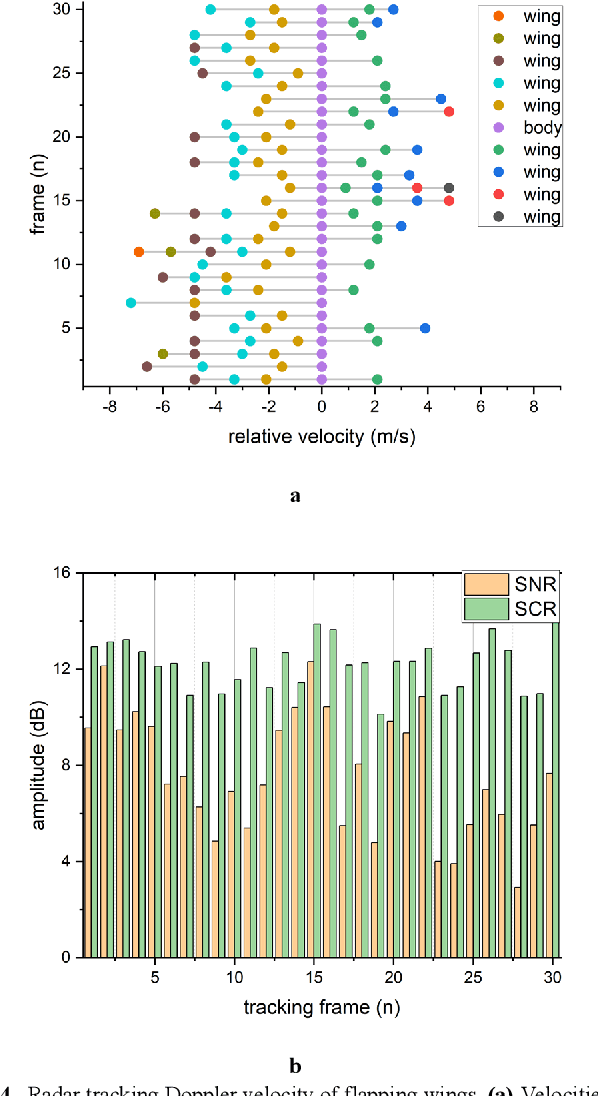
Radar echoes from bird flocks contain modulation signals, which we find are produced by the flapping gaits of birds in the flock, resulting in a group of spectral peaks with similar amplitudes spaced at a specific interval. We call this the formation wing-beat modulation (FWM) effect. FWM signals are micro-Doppler modulated by flapping wings and are related to the bird number, wing-beat frequency, and flight phasing strategy. Our X-band radar data show that FWM signals exist in radar signals of a seagull flock, providing tools for quantifying the bird number and estimating the mean wingbeat rate of birds. This new finding could aid in research on the quantification of bird migration numbers and estimation of bird flight behavior in radar ornithology and aero-ecology.
Self-driven Grounding: Large Language Model Agents with Automatical Language-aligned Skill Learning
Sep 04, 2023



Large language models (LLMs) show their powerful automatic reasoning and planning capability with a wealth of semantic knowledge about the human world. However, the grounding problem still hinders the applications of LLMs in the real-world environment. Existing studies try to fine-tune the LLM or utilize pre-defined behavior APIs to bridge the LLMs and the environment, which not only costs huge human efforts to customize for every single task but also weakens the generality strengths of LLMs. To autonomously ground the LLM onto the environment, we proposed the Self-Driven Grounding (SDG) framework to automatically and progressively ground the LLM with self-driven skill learning. SDG first employs the LLM to propose the hypothesis of sub-goals to achieve tasks and then verify the feasibility of the hypothesis via interacting with the underlying environment. Once verified, SDG can then learn generalized skills with the guidance of these successfully grounded subgoals. These skills can be further utilized to accomplish more complex tasks which fail to pass the verification phase. Verified in the famous instruction following task set-BabyAI, SDG achieves comparable performance in the most challenging tasks compared with imitation learning methods that cost millions of demonstrations, proving the effectiveness of learned skills and showing the feasibility and efficiency of our framework.
Online Prototype Alignment for Few-shot Policy Transfer
Jun 12, 2023Domain adaptation in reinforcement learning (RL) mainly deals with the changes of observation when transferring the policy to a new environment. Many traditional approaches of domain adaptation in RL manage to learn a mapping function between the source and target domain in explicit or implicit ways. However, they typically require access to abundant data from the target domain. Besides, they often rely on visual clues to learn the mapping function and may fail when the source domain looks quite different from the target domain. To address these problems, we propose a novel framework Online Prototype Alignment (OPA) to learn the mapping function based on the functional similarity of elements and is able to achieve the few-shot policy transfer within only several episodes. The key insight of OPA is to introduce an exploration mechanism that can interact with the unseen elements of the target domain in an efficient and purposeful manner, and then connect them with the seen elements in the source domain according to their functionalities (instead of visual clues). Experimental results show that when the target domain looks visually different from the source domain, OPA can achieve better transfer performance even with much fewer samples from the target domain, outperforming prior methods.