 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionFlow: A Pipelined Action Acceleration for Vision Language Models on Edge
Dec 23, 2025Vision-Language-Action (VLA) models have emerged as a unified paradigm for robotic perception and control, enabling emergent generalization and long-horizon task execution. However, their deployment in dynamic, real-world environments is severely hin dered by high inference latency. While smooth robotic interaction requires control frequencies of 20 to 30 Hz, current VLA models typi cally operate at only 3-5 Hz on edge devices due to the memory bound nature of autoregressive decoding. Existing optimizations often require extensive retraining or compromise model accuracy. To bridge this gap, we introduce ActionFlow, a system-level inference framework tailored for resource-constrained edge plat forms. At the core of ActionFlow is a Cross-Request Pipelin ing strategy, a novel scheduler that redefines VLA inference as a macro-pipeline of micro-requests. The strategy intelligently batches memory-bound Decode phases with compute-bound Prefill phases across continuous time steps to maximize hardware utilization. Furthermore, to support this scheduling, we propose a Cross Request State Packed Forward operator and a Unified KV Ring Buffer, which fuse fragmented memory operations into efficient dense computations. Experimental results demonstrate that ActionFlow achieves a 2.55x improvement in FPS on the OpenVLA-7B model without retraining, enabling real-time dy namic manipulation on edge hardware. Our work is available at https://anonymous.4open.science/r/ActionFlow-1D47.
QiMeng-Xpiler: Transcompiling Tensor Programs for Deep Learning Systems with a Neural-Symbolic Approach
May 04, 2025Heterogeneous deep learning systems (DLS) such as GPUs and ASICs have been widely deployed in industrial data centers, which requires to develop multiple low-level tensor programs for different platforms. An attractive solution to relieve the programming burden is to transcompile the legacy code of one platform to others. However, current transcompilation techniques struggle with either tremendous manual efforts or functional incorrectness, rendering "Write Once, Run Anywhere" of tensor programs an open question. We propose a novel transcompiler, i.e., QiMeng-Xpiler, for automatically translating tensor programs across DLS via both large language models (LLMs) and symbolic program synthesis, i.e., neural-symbolic synthesis. The key insight is leveraging the powerful code generation ability of LLM to make costly search-based symbolic synthesis computationally tractable. Concretely, we propose multiple LLM-assisted compilation passes via pre-defined meta-prompts for program transformation. During each program transformation, efficient symbolic program synthesis is employed to repair incorrect code snippets with a limited scale. To attain high performance, we propose a hierarchical auto-tuning approach to systematically explore both the parameters and sequences of transformation passes. Experiments on 4 DLS with distinct programming interfaces, i.e., Intel DL Boost with VNNI, NVIDIA GPU with CUDA, AMD MI with HIP, and Cambricon MLU with BANG, demonstrate that QiMeng-Xpiler correctly translates different tensor programs at the accuracy of 95% on average, and the performance of translated programs achieves up to 2.0x over vendor-provided manually-optimized libraries. As a result, the programming productivity of DLS is improved by up to 96.0x via transcompiling legacy tensor programs.
Emergent Communication for Rules Reasoning
Nov 08, 2023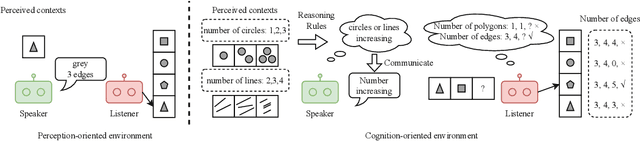

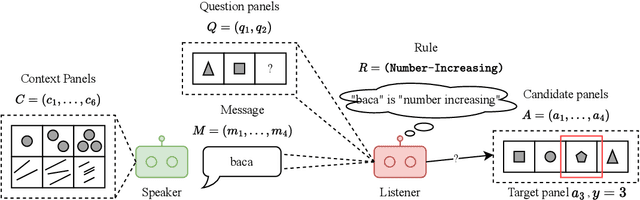

Research on emergent communication between deep-learning-based agents has received extensive attention due to its inspiration for linguistics and artificial intelligence. However, previous attempts have hovered around emerging communication under perception-oriented environmental settings, that forces agents to describe low-level perceptual features intra image or symbol contexts. In this work, inspired by the classic human reasoning test (namely Raven's Progressive Matrix), we propose the Reasoning Game, a cognition-oriented environment that encourages agents to reason and communicate high-level rules, rather than perceived low-level contexts. Moreover, we propose 1) an unbiased dataset (namely rule-RAVEN) as a benchmark to avoid overfitting, 2) and a two-stage curriculum agent training method as a baseline for more stable convergence in the Reasoning Game, where contexts and semantics are bilaterally drifting. Experimental results show that, in the Reasoning Game, a semantically stable and compositional language emerges to solve reasoning problems. The emerged language helps agents apply the extracted rules to the generalization of unseen context attributes, and to the transfer between different context attributes or even tasks.
A Survey of FPGA Based Deep Learning Accelerators: Challenges and Opportunities
Dec 25, 2018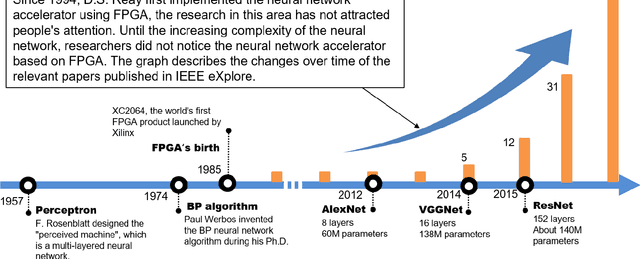
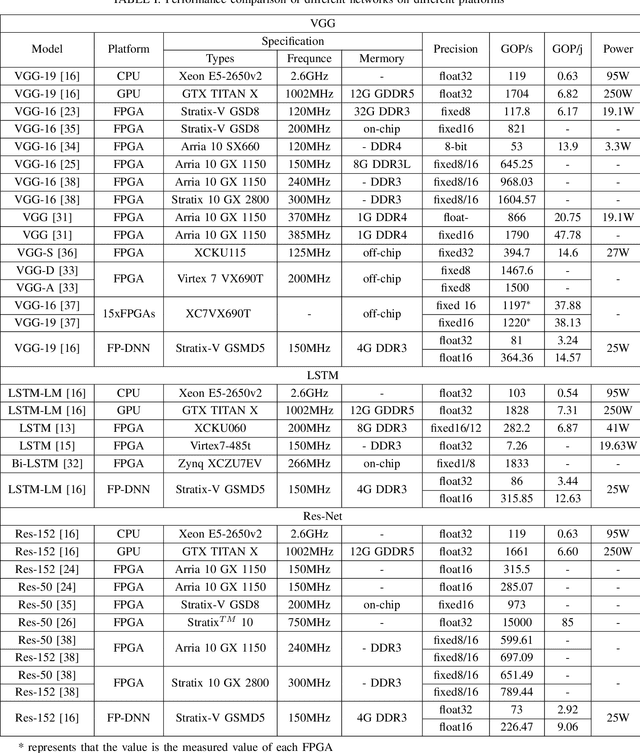
With the rapid development of in-depth learning, neural network and deep learning algorithms have been widely used in various fields, e.g., image, video and voice processing. However, the neural network model is getting larger and larger, which is expressed in the calculation of model parameters. Although a wealth of existing efforts on GPU platforms currently used by researchers for improving computing performance, dedicated hardware solutions are essential and emerging to provide advantages over pure software solutions. In this paper, we systematically investigate the neural network accelerator based on FPGA. Specifically, we respectively review the accelerators designed for specific problems, specific algorithms, algorithm features, and general templates. We also compared the design and implementation of the accelerator based on FPGA under different devices and network models and compared it with the versions of CPU and GPU. Finally, we present to discuss the advantages and disadvantages of accelerators on FPGA platforms and to further explore the opportunities for future research.
DLAU: A Scalable Deep Learning Accelerator Unit on FPGA
May 23, 2016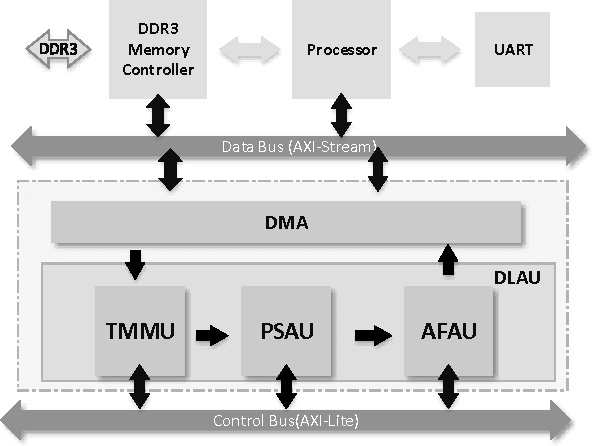
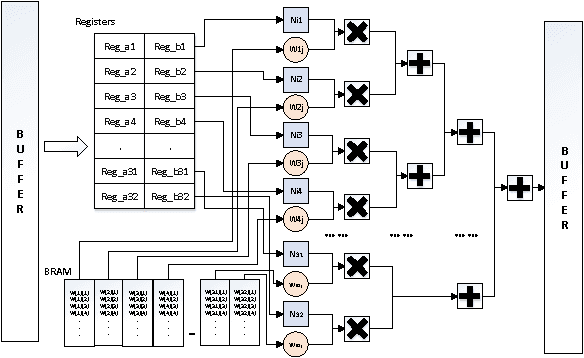
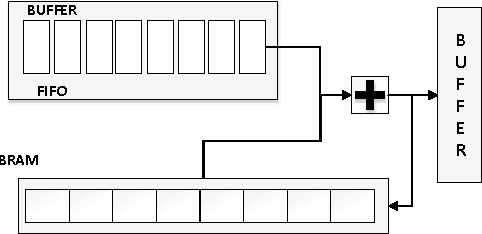
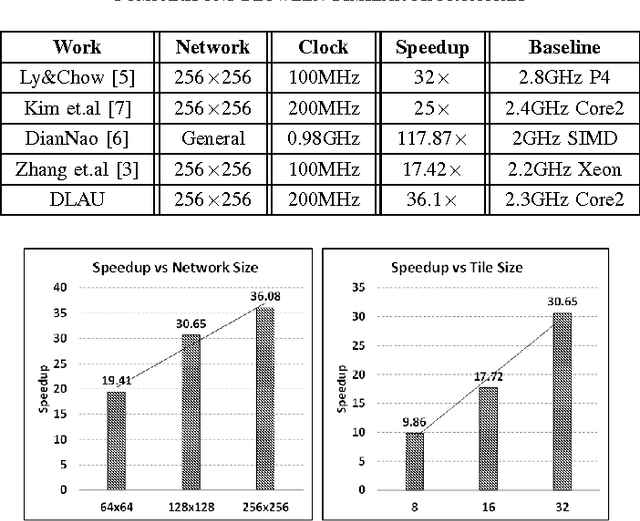
As the emerging field of machine learning, deep learning shows excellent ability in solving complex learning problems. However, the size of the networks becomes increasingly large scale due to the demands of the practical applications, which poses significant challenge to construct a high performance implementations of deep learning neural networks. In order to improve the performance as well to maintain the low power cost, in this paper we design DLAU, which is a scalable accelerator architecture for large-scale deep learning networks using FPGA as the hardware prototype. The DLAU accelerator employs three pipelined processing units to improve the throughput and utilizes tile techniques to explore locality for deep learning applications. Experimental results on the state-of-the-art Xilinx FPGA board demonstrate that the DLAU accelerator is able to achieve up to 36.1x speedup comparing to the Intel Core2 processors, with the power consumption at 234mW.