 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Class Subspace: Teacher-Guided Training for Reliable Out-of-Distribution Detection in Single-Domain Models
Mar 11, 2026Out-of-distribution (OOD) detection methods perform well on multi-domain benchmarks, yet many practical systems are trained on single-domain data. We show that this regime induces a geometric failure mode, Domain-Sensitivity Collapse (DSC): supervised training compresses features into a low-rank class subspace and suppresses directions that carry domain-shift signal. We provide theory showing that, under DSC, distance- and logit-based OOD scores lose sensitivity to domain shift. We then introduce Teacher-Guided Training (TGT), which distills class-suppressed residual structure from a frozen multi-domain teacher (DINOv2) into the student during training. The teacher and auxiliary head are discarded after training, adding no inference overhead. Across eight single-domain benchmarks, TGT yields large far-OOD FPR@95 reductions for distance-based scorers: MDS improves by 11.61 pp, ViM by 10.78 pp, and kNN by 12.87 pp (ResNet-50 average), while maintaining or slightly improving in-domain OOD and classification accuracy.
Generalized Regularized Evidential Deep Learning Models: Theory and Comprehensive Evaluation
Dec 27, 2025Evidential deep learning (EDL) models, based on Subjective Logic, introduce a principled and computationally efficient way to make deterministic neural networks uncertainty-aware. The resulting evidential models can quantify fine-grained uncertainty using learned evidence. However, the Subjective-Logic framework constrains evidence to be non-negative, requiring specific activation functions whose geometric properties can induce activation-dependent learning-freeze behavior: a regime where gradients become extremely small for samples mapped into low-evidence regions. We theoretically characterize this behavior and analyze how different evidential activations influence learning dynamics. Building on this analysis, we design a general family of activation functions and corresponding evidential regularizers that provide an alternative pathway for consistent evidence updates across activation regimes. Extensive experiments on four benchmark classification problems (MNIST, CIFAR-10, CIFAR-100, and Tiny-ImageNet), two few-shot classification problems, and blind face restoration problem empirically validate the developed theory and demonstrate the effectiveness of the proposed generalized regularized evidential models.
FuXi-Air: Urban Air Quality Forecasting Based on Emission-Meteorology-Pollutant multimodal Machine Learning
Jun 09, 2025Air pollution has emerged as a major public health challenge in megacities. Numerical simulations and single-site machine learning approaches have been widely applied in air quality forecasting tasks. However, these methods face multiple limitations, including high computational costs, low operational efficiency, and limited integration with observational data. With the rapid advancement of artificial intelligence, there is an urgent need to develop a low-cost, efficient air quality forecasting model for smart urban management. An air quality forecasting model, named FuXi-Air, has been constructed in this study based on multimodal data fusion to support high-precision air quality forecasting and operated in typical megacities. The model integrates meteorological forecasts, emission inventories, and pollutant monitoring data under the guidance of air pollution mechanism. By combining an autoregressive prediction framework with a frame interpolation strategy, the model successfully completes 72-hour forecasts for six major air pollutants at an hourly resolution across multiple monitoring sites within 25-30 seconds. In terms of both computational efficiency and forecasting accuracy, it outperforms the mainstream numerical air quality models in operational forecasting work. Ablation experiments concerning key influencing factors show that although meteorological data contribute more to model accuracy than emission inventories do, the integration of multimodal data significantly improves forecasting precision and ensures that reliable predictions are obtained under differing pollution mechanisms across megacities. This study provides both a technical reference and a practical example for applying multimodal data-driven models to air quality forecasting and offers new insights into building hybrid forecasting systems to support air pollution risk warning in smart city management.
PLANETALIGN: A Comprehensive Python Library for Benchmarking Network Alignment
May 27, 2025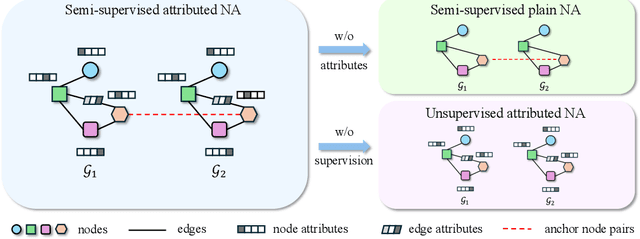
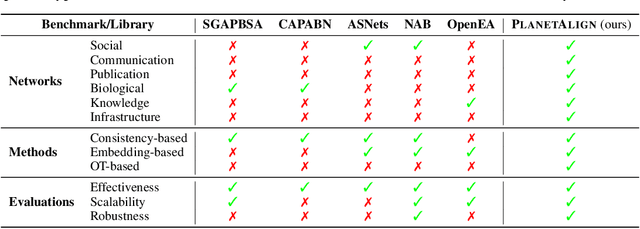
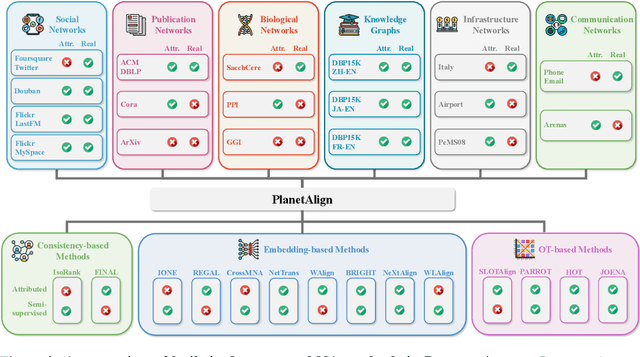
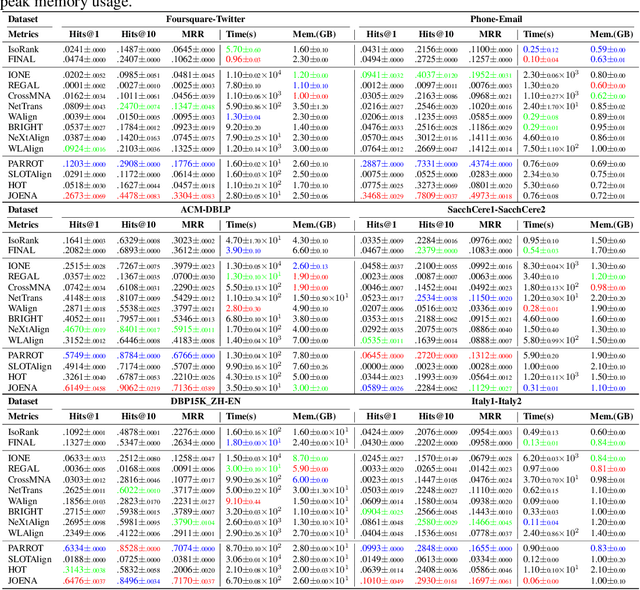
Network alignment (NA) aims to identify node correspondence across different networks and serves as a critical cornerstone behind various downstream multi-network learning tasks. Despite growing research in NA, there lacks a comprehensive library that facilitates the systematic development and benchmarking of NA methods. In this work, we introduce PLANETALIGN, a comprehensive Python library for network alignment that features a rich collection of built-in datasets, methods, and evaluation pipelines with easy-to-use APIs. Specifically, PLANETALIGN integrates 18 datasets and 14 NA methods with extensible APIs for easy use and development of NA methods. Our standardized evaluation pipeline encompasses a wide range of metrics, enabling a systematic assessment of the effectiveness, scalability, and robustness of NA methods. Through extensive comparative studies, we reveal practical insights into the strengths and limitations of existing NA methods. We hope that PLANETALIGN can foster a deeper understanding of the NA problem and facilitate the development and benchmarking of more effective, scalable, and robust methods in the future. The source code of PLANETALIGN is available at https://github.com/yq-leo/PlanetAlign.
ProDisc-VAD: An Efficient System for Weakly-Supervised Anomaly Detection in Video Surveillance Applications
May 04, 2025Weakly-supervised video anomaly detection (WS-VAD) using Multiple Instance Learning (MIL) suffers from label ambiguity, hindering discriminative feature learning. We propose ProDisc-VAD, an efficient framework tackling this via two synergistic components. The Prototype Interaction Layer (PIL) provides controlled normality modeling using a small set of learnable prototypes, establishing a robust baseline without being overwhelmed by dominant normal data. The Pseudo-Instance Discriminative Enhancement (PIDE) loss boosts separability by applying targeted contrastive learning exclusively to the most reliable extreme-scoring instances (highest/lowest scores). ProDisc-VAD achieves strong AUCs (97.98% ShanghaiTech, 87.12% UCF-Crime) using only 0.4M parameters, over 800x fewer than recent ViT-based methods like VadCLIP, demonstrating exceptional efficiency alongside state-of-the-art performance. Code is available at https://github.com/modadundun/ProDisc-VAD.
Can We Ignore Labels In Out of Distribution Detection?
Apr 20, 2025



Out-of-distribution (OOD) detection methods have recently become more prominent, serving as a core element in safety-critical autonomous systems. One major purpose of OOD detection is to reject invalid inputs that could lead to unpredictable errors and compromise safety. Due to the cost of labeled data, recent works have investigated the feasibility of self-supervised learning (SSL) OOD detection, unlabeled OOD detection, and zero shot OOD detection. In this work, we identify a set of conditions for a theoretical guarantee of failure in unlabeled OOD detection algorithms from an information-theoretic perspective. These conditions are present in all OOD tasks dealing with real-world data: I) we provide theoretical proof of unlabeled OOD detection failure when there exists zero mutual information between the learning objective and the in-distribution labels, a.k.a. 'label blindness', II) we define a new OOD task - Adjacent OOD detection - that tests for label blindness and accounts for a previously ignored safety gap in all OOD detection benchmarks, and III) we perform experiments demonstrating that existing unlabeled OOD methods fail under conditions suggested by our label blindness theory and analyze the implications for future research in unlabeled OOD methods.
Joint Optimal Transport and Embedding for Network Alignment
Feb 26, 2025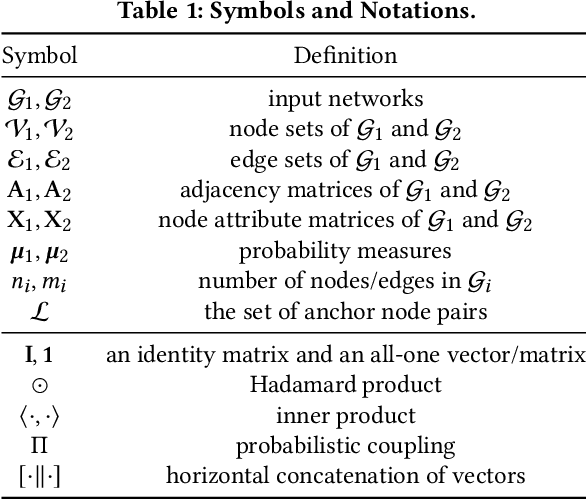
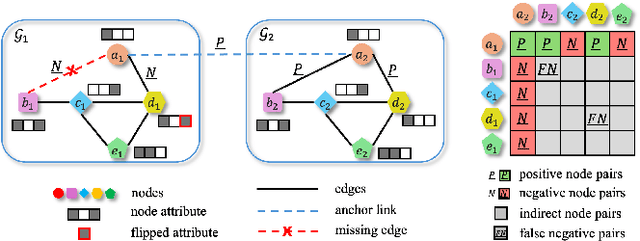
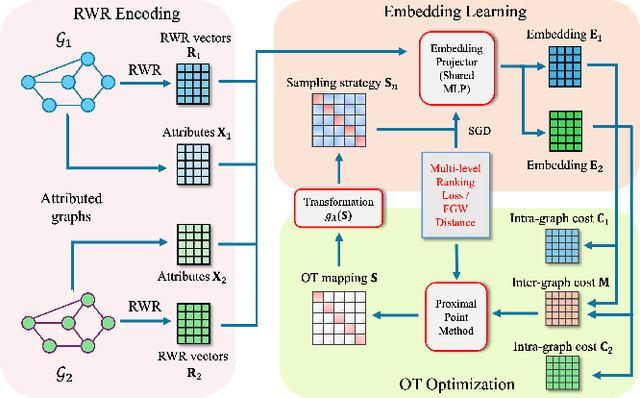
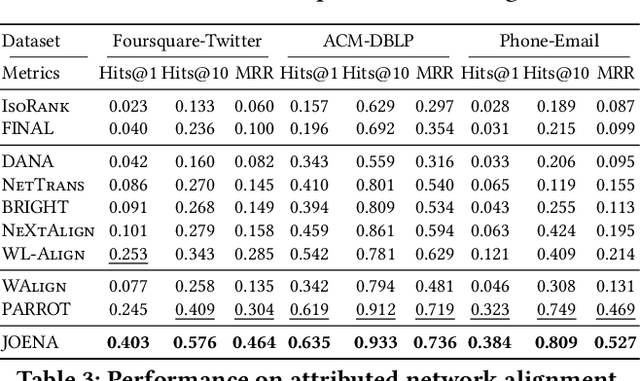
Network alignment, which aims to find node correspondence across different networks, is the cornerstone of various downstream multi-network and Web mining tasks. Most of the embedding-based methods indirectly model cross-network node relationships by contrasting positive and negative node pairs sampled from hand-crafted strategies, which are vulnerable to graph noises and lead to potential misalignment of nodes. Another line of work based on the optimal transport (OT) theory directly models cross-network node relationships and generates noise-reduced alignments. However, OT methods heavily rely on fixed, pre-defined cost functions that prohibit end-to-end training and are hard to generalize. In this paper, we aim to unify the embedding and OT-based methods in a mutually beneficial manner and propose a joint optimal transport and embedding framework for network alignment named JOENA. For one thing (OT for embedding), through a simple yet effective transformation, the noise-reduced OT mapping serves as an adaptive sampling strategy directly modeling all cross-network node pairs for robust embedding learning.For another (embedding for OT), on top of the learned embeddings, the OT cost can be gradually trained in an end-to-end fashion, which further enhances the alignment quality. With a unified objective, the mutual benefits of both methods can be achieved by an alternating optimization schema with guaranteed convergence. Extensive experiments on real-world networks validate the effectiveness and scalability of JOENA, achieving up to 16% improvement in MRR and 20x speedup compared with the state-of-the-art alignment methods.
Reinforced Compressive Neural Architecture Search for Versatile Adversarial Robustness
Jun 10, 2024



Prior neural architecture search (NAS) for adversarial robustness works have discovered that a lightweight and adversarially robust neural network architecture could exist in a non-robust large teacher network, generally disclosed by heuristic rules through statistical analysis and neural architecture search, generally disclosed by heuristic rules from neural architecture search. However, heuristic methods cannot uniformly handle different adversarial attacks and "teacher" network capacity. To solve this challenge, we propose a Reinforced Compressive Neural Architecture Search (RC-NAS) for Versatile Adversarial Robustness. Specifically, we define task settings that compose datasets, adversarial attacks, and teacher network information. Given diverse tasks, we conduct a novel dual-level training paradigm that consists of a meta-training and a fine-tuning phase to effectively expose the RL agent to diverse attack scenarios (in meta-training), and making it adapt quickly to locate a sub-network (in fine-tuning) for any previously unseen scenarios. Experiments show that our framework could achieve adaptive compression towards different initial teacher networks, datasets, and adversarial attacks, resulting in more lightweight and adversarially robust architectures.
Latent Space Energy-based Model for Fine-grained Open Set Recognition
Sep 19, 2023Fine-grained open-set recognition (FineOSR) aims to recognize images belonging to classes with subtle appearance differences while rejecting images of unknown classes. A recent trend in OSR shows the benefit of generative models to discriminative unknown detection. As a type of generative model, energy-based models (EBM) are the potential for hybrid modeling of generative and discriminative tasks. However, most existing EBMs suffer from density estimation in high-dimensional space, which is critical to recognizing images from fine-grained classes. In this paper, we explore the low-dimensional latent space with energy-based prior distribution for OSR in a fine-grained visual world. Specifically, based on the latent space EBM, we propose an attribute-aware information bottleneck (AIB), a residual attribute feature aggregation (RAFA) module, and an uncertainty-based virtual outlier synthesis (UVOS) module to improve the expressivity, granularity, and density of the samples in fine-grained classes, respectively. Our method is flexible to take advantage of recent vision transformers for powerful visual classification and generation. The method is validated on both fine-grained and general visual classification datasets while preserving the capability of generating photo-realistic fake images with high resolution.
On Model Explanations with Transferable Neural Pathways
Sep 18, 2023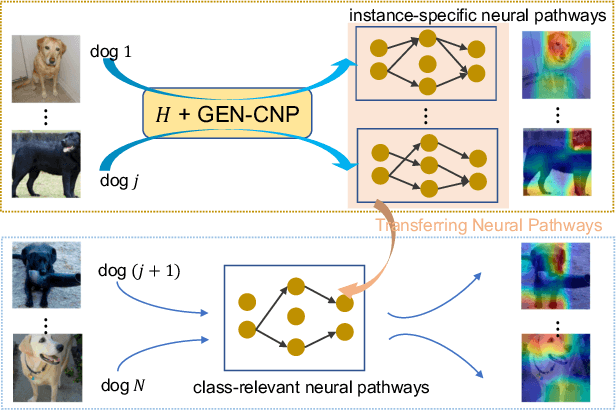
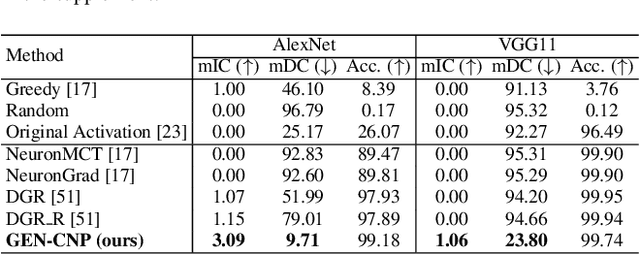
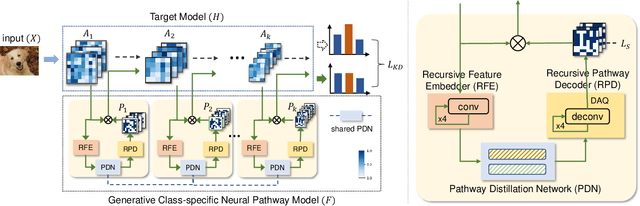

Neural pathways as model explanations consist of a sparse set of neurons that provide the same level of prediction performance as the whole model. Existing methods primarily focus on accuracy and sparsity but the generated pathways may offer limited interpretability thus fall short in explaining the model behavior. In this paper, we suggest two interpretability criteria of neural pathways: (i) same-class neural pathways should primarily consist of class-relevant neurons; (ii) each instance's neural pathway sparsity should be optimally determined. To this end, we propose a Generative Class-relevant Neural Pathway (GEN-CNP) model that learns to predict the neural pathways from the target model's feature maps. We propose to learn class-relevant information from features of deep and shallow layers such that same-class neural pathways exhibit high similarity. We further impose a faithfulness criterion for GEN-CNP to generate pathways with instance-specific sparsity. We propose to transfer the class-relevant neural pathways to explain samples of the same class and show experimentally and qualitatively their faithfulness and interpretability.