 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Model Explanations with Transferable Neural Pathways
Sep 18, 2023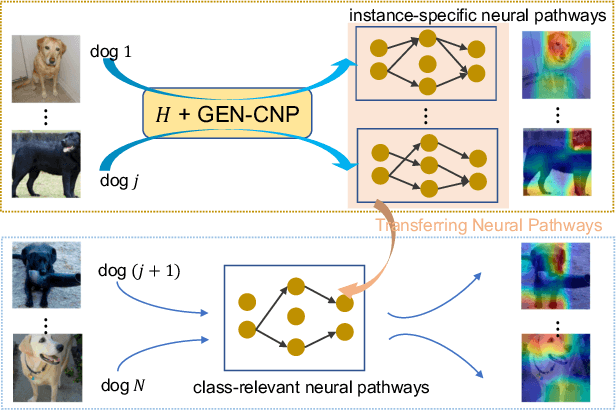
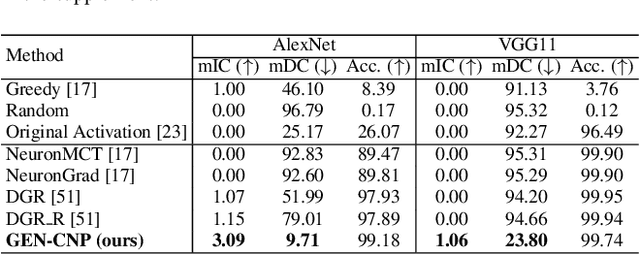
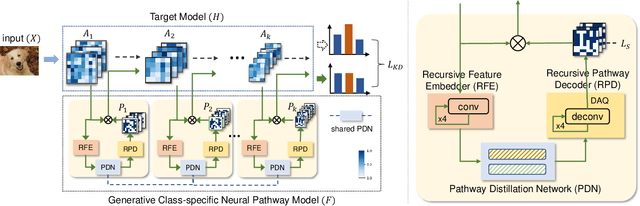

Neural pathways as model explanations consist of a sparse set of neurons that provide the same level of prediction performance as the whole model. Existing methods primarily focus on accuracy and sparsity but the generated pathways may offer limited interpretability thus fall short in explaining the model behavior. In this paper, we suggest two interpretability criteria of neural pathways: (i) same-class neural pathways should primarily consist of class-relevant neurons; (ii) each instance's neural pathway sparsity should be optimally determined. To this end, we propose a Generative Class-relevant Neural Pathway (GEN-CNP) model that learns to predict the neural pathways from the target model's feature maps. We propose to learn class-relevant information from features of deep and shallow layers such that same-class neural pathways exhibit high similarity. We further impose a faithfulness criterion for GEN-CNP to generate pathways with instance-specific sparsity. We propose to transfer the class-relevant neural pathways to explain samples of the same class and show experimentally and qualitatively their faithfulness and interpretability.
Catch Missing Details: Image Reconstruction with Frequency Augmented Variational Autoencoder
May 04, 2023The popular VQ-VAE models reconstruct images through learning a discrete codebook but suffer from a significant issue in the rapid quality degradation of image reconstruction as the compression rate rises. One major reason is that a higher compression rate induces more loss of visual signals on the higher frequency spectrum which reflect the details on pixel space. In this paper, a Frequency Complement Module (FCM) architecture is proposed to capture the missing frequency information for enhancing reconstruction quality. The FCM can be easily incorporated into the VQ-VAE structure, and we refer to the new model as Frequency Augmented VAE (FA-VAE). In addition, a Dynamic Spectrum Loss (DSL) is introduced to guide the FCMs to balance between various frequencies dynamically for optimal reconstruction. FA-VAE is further extended to the text-to-image synthesis task, and a Cross-attention Autoregressive Transformer (CAT) is proposed to obtain more precise semantic attributes in texts. Extensive reconstruction experiments with different compression rates are conducted on several benchmark datasets, and the results demonstrate that the proposed FA-VAE is able to restore more faithfully the details compared to SOTA methods. CAT also shows improved generation quality with better image-text semantic alignment.
Gradient Frequency Modulation for Visually Explaining Video Understanding Models
Nov 30, 2021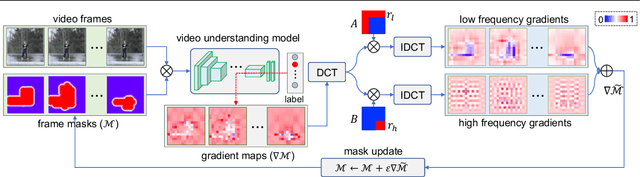



In many applications, it is essential to understand why a machine learning model makes the decisions it does, but this is inhibited by the black-box nature of state-of-the-art neural networks. Because of this, increasing attention has been paid to explainability in deep learning, including in the area of video understanding. Due to the temporal dimension of video data, the main challenge of explaining a video action recognition model is to produce spatiotemporally consistent visual explanations, which has been ignored in the existing literature. In this paper, we propose Frequency-based Extremal Perturbation (F-EP) to explain a video understanding model's decisions. Because the explanations given by perturbation methods are noisy and non-smooth both spatially and temporally, we propose to modulate the frequencies of gradient maps from the neural network model with a Discrete Cosine Transform (DCT). We show in a range of experiments that F-EP provides more spatiotemporally consistent explanations that more faithfully represent the model's decisions compared to the existing state-of-the-art methods.