 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Frequency Modulation for Visually Explaining Video Understanding Models
Paper and Code
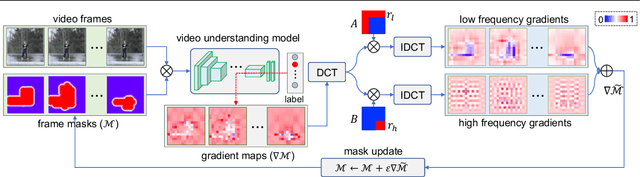



In many applications, it is essential to understand why a machine learning model makes the decisions it does, but this is inhibited by the black-box nature of state-of-the-art neural networks. Because of this, increasing attention has been paid to explainability in deep learning, including in the area of video understanding. Due to the temporal dimension of video data, the main challenge of explaining a video action recognition model is to produce spatiotemporally consistent visual explanations, which has been ignored in the existing literature. In this paper, we propose Frequency-based Extremal Perturbation (F-EP) to explain a video understanding model's decisions. Because the explanations given by perturbation methods are noisy and non-smooth both spatially and temporally, we propose to modulate the frequencies of gradient maps from the neural network model with a Discrete Cosine Transform (DCT). We show in a range of experiments that F-EP provides more spatiotemporally consistent explanations that more faithfully represent the model's decisions compared to the existing state-of-the-art methods.