 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Network Alignment: An Efficient Algorithm and Explicit Probability Bounds
Jun 11, 2026This paper studies a variation of the classic network alignment problem, named diffusion-network alignment. The goal is to align the vertices of a rooted diffusion tree to the vertices of a network, where the diffusion tree could be from a communication trace or contact tracing, and the network could be an online or offline social network. Different from the classic network alignment where both networks are fully observed, this model captures the information asymmetry of two networks. To solve this problem, this paper presents an efficient algorithm based on tree correlation tests to extract alignment information from local neighborhoods. We analyze the performance of the algorithm in the sparse graph regime and show that with high probability, all matched pairs are correct. Furthermore, for each vertex on the diffusion tree, this paper establishes an explicit lower bound on the probability that the vertex is correctly matched. These lower bounds are depth-dependent and increase as vertices get closer to the root.
Efficient Federated RLHF via Zeroth-Order Policy Optimization
Apr 20, 2026This paper considers reinforcement learning from human feedback in a federated learning setting with resource-constrained agents, such as edge devices. We propose an efficient federated RLHF algorithm, named Partitioned, Sign-based Stochastic Zeroth-order Policy Optimization (Par-S$^2$ZPO). The algorithm is built on zeroth-order optimization with binary perturbation, resulting in low communication, computation, and memory complexity by design. Our theoretical analysis establishes an upper bound on the convergence rate of Par-S$^2$ZPO, revealing that it is as efficient as its centralized counterpart in terms of sample complexity but converges faster in terms of policy update iterations. Our experimental results show that it outperforms a FedAvg-based RLHF on four MuJoCo RL tasks.
Near-Optimal Regret-Queue Length Tradeoff in Online Learning for Two-Sided Markets
Oct 15, 2025We study a two-sided market, wherein, price-sensitive heterogeneous customers and servers arrive and join their respective queues. A compatible customer-server pair can then be matched by the platform, at which point, they leave the system. Our objective is to design pricing and matching algorithms that maximize the platform's profit, while maintaining reasonable queue lengths. As the demand and supply curves governing the price-dependent arrival rates may not be known in practice, we design a novel online-learning-based pricing policy and establish its near-optimality. In particular, we prove a tradeoff among three performance metrics: $\tilde{O}(T^{1-\gamma})$ regret, $\tilde{O}(T^{\gamma/2})$ average queue length, and $\tilde{O}(T^{\gamma})$ maximum queue length for $\gamma \in (0, 1/6]$, significantly improving over existing results [1]. Moreover, barring the permissible range of $\gamma$, we show that this trade-off between regret and average queue length is optimal up to logarithmic factors under a class of policies, matching the optimal one as in [2] which assumes the demand and supply curves to be known. Our proposed policy has two noteworthy features: a dynamic component that optimizes the tradeoff between low regret and small queue lengths; and a probabilistic component that resolves the tension between obtaining useful samples for fast learning and maintaining small queue lengths.
Joint Optimal Transport and Embedding for Network Alignment
Feb 26, 2025
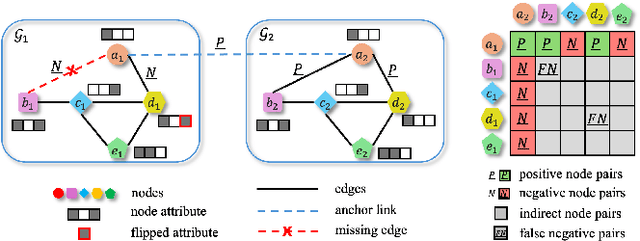
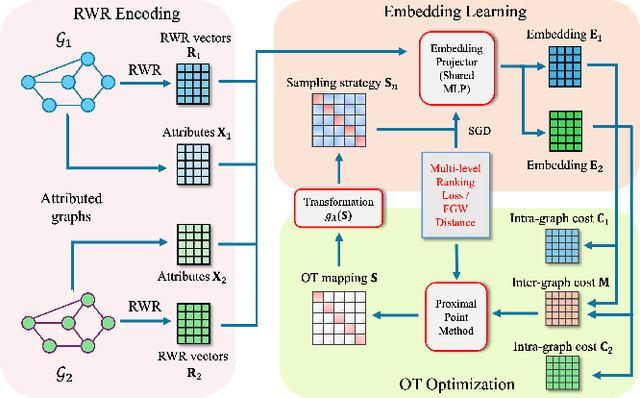
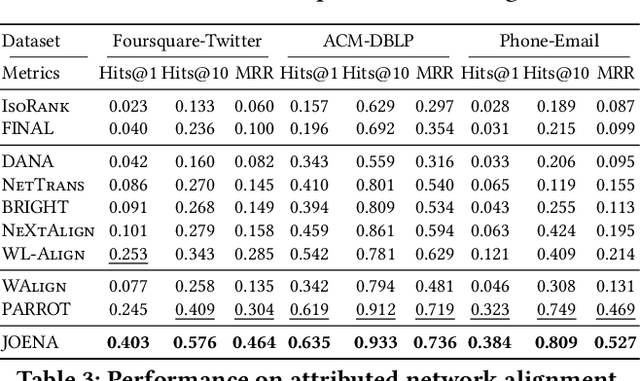
Network alignment, which aims to find node correspondence across different networks, is the cornerstone of various downstream multi-network and Web mining tasks. Most of the embedding-based methods indirectly model cross-network node relationships by contrasting positive and negative node pairs sampled from hand-crafted strategies, which are vulnerable to graph noises and lead to potential misalignment of nodes. Another line of work based on the optimal transport (OT) theory directly models cross-network node relationships and generates noise-reduced alignments. However, OT methods heavily rely on fixed, pre-defined cost functions that prohibit end-to-end training and are hard to generalize. In this paper, we aim to unify the embedding and OT-based methods in a mutually beneficial manner and propose a joint optimal transport and embedding framework for network alignment named JOENA. For one thing (OT for embedding), through a simple yet effective transformation, the noise-reduced OT mapping serves as an adaptive sampling strategy directly modeling all cross-network node pairs for robust embedding learning.For another (embedding for OT), on top of the learned embeddings, the OT cost can be gradually trained in an end-to-end fashion, which further enhances the alignment quality. With a unified objective, the mutual benefits of both methods can be achieved by an alternating optimization schema with guaranteed convergence. Extensive experiments on real-world networks validate the effectiveness and scalability of JOENA, achieving up to 16% improvement in MRR and 20x speedup compared with the state-of-the-art alignment methods.
Achieving O(1/N) Optimality Gap in Restless Bandits through Diffusion Approximation
Oct 19, 2024
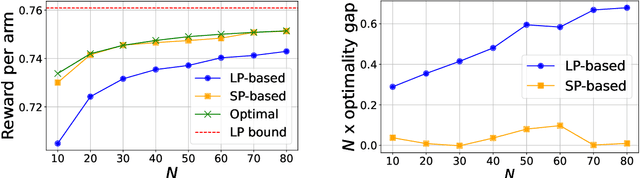
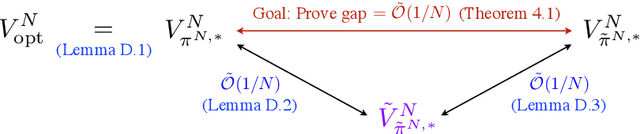
We study the finite horizon Restless Multi-Armed Bandit (RMAB) problem with $N$ homogeneous arms, focusing on the challenges posed by degenerate RMABs, which are prevalent in practical applications. While previous work has shown that Linear Programming (LP)-based policies achieve exponentially fast convergence relative to the LP upper bound in non-degenerate models, applying these LP-based policies to degenerate RMABs results in slower convergence rates of $O(1/\sqrt{N})$. We construct a diffusion system that incorporates both the mean and variance of the stochastic processes, in contrast to the fluid system from the LP, which only accounts for the mean, thereby providing a more accurate representation of RMAB dynamics. Consequently, our novel diffusion-resolving policy achieves an optimality gap of $O(1/N)$ relative to the true optimal value, rather than the LP upper bound, revealing that the fluid approximation and the LP upper bound are too loose in degenerate settings. These insights pave the way for constructing policies that surpass the $O(1/\sqrt{N})$ optimality gap for any RMAB, whether degenerate or not.
Zeroth-Order Policy Gradient for Reinforcement Learning from Human Feedback without Reward Inference
Sep 25, 2024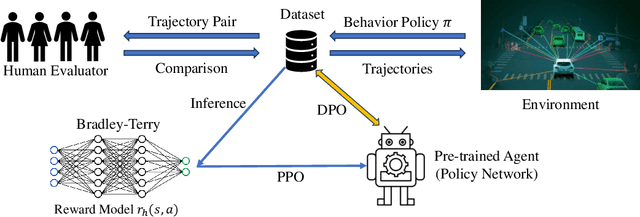
Reward inference (learning a reward model from human preferences) is a critical intermediate step in Reinforcement Learning from Human Feedback (RLHF) for fine-tuning Large Language Models (LLMs) such as ChatGPT. In practice, reward inference faces several fundamental challenges, including double problem misspecification, reward model evaluation without ground truth, distribution shift, and overfitting in joint reward model and policy training. An alternative approach that avoids these pitfalls is direct policy optimization without reward inference, such as Direct Preference Optimization (DPO), which provides a much simpler pipeline and has shown empirical success in LLMs. However, DPO utilizes the closed-form expression between the optimal policy and the reward function, which only works under the bandit setting or deterministic MDPs. This paper develops two RLHF algorithms without reward inference, which work for general RL problems beyond bandits and deterministic MDPs, and general preference models beyond the Bradely-Terry model. The key idea is to estimate the local value function difference from human preferences and then approximate the policy gradient with a zeroth-order gradient approximator. For both algorithms, we establish rates of convergence in terms of the number of policy gradient iterations, as well as the number of trajectory samples and human preference queries per iteration. Our results show there exist provably efficient methods to solve general RLHF problems without reward inference.
Policy Gradient Methods for Risk-Sensitive Distributional Reinforcement Learning with Provable Convergence
May 23, 2024



Risk-sensitive reinforcement learning (RL) is crucial for maintaining reliable performance in many high-stakes applications. While most RL methods aim to learn a point estimate of the random cumulative cost, distributional RL (DRL) seeks to estimate the entire distribution of it. The distribution provides all necessary information about the cost and leads to a unified framework for handling various risk measures in a risk-sensitive setting. However, developing policy gradient methods for risk-sensitive DRL is inherently more complex as it pertains to finding the gradient of a probability measure. This paper introduces a policy gradient method for risk-sensitive DRL with general coherent risk measures, where we provide an analytical form of the probability measure's gradient. We further prove the local convergence of the proposed algorithm under mild smoothness assumptions. For practical use, we also design a categorical distributional policy gradient algorithm (CDPG) based on categorical distributional policy evaluation and trajectory-based gradient estimation. Through experiments on a stochastic cliff-walking environment, we illustrate the benefits of considering a risk-sensitive setting in DRL.
Learning-Based Pricing and Matching for Two-Sided Queues
Mar 17, 2024



We consider a dynamic system with multiple types of customers and servers. Each type of waiting customer or server joins a separate queue, forming a bipartite graph with customer-side queues and server-side queues. The platform can match the servers and customers if their types are compatible. The matched pairs then leave the system. The platform will charge a customer a price according to their type when they arrive and will pay a server a price according to their type. The arrival rate of each queue is determined by the price according to some unknown demand or supply functions. Our goal is to design pricing and matching algorithms to maximize the profit of the platform with unknown demand and supply functions, while keeping queue lengths of both customers and servers below a predetermined threshold. This system can be used to model two-sided markets such as ride-sharing markets with passengers and drivers. The difficulties of the problem include simultaneous learning and decision making, and the tradeoff between maximizing profit and minimizing queue length. We use a longest-queue-first matching algorithm and propose a learning-based pricing algorithm, which combines gradient-free stochastic projected gradient ascent with bisection search. We prove that our proposed algorithm yields a sublinear regret $\tilde{O}(T^{5/6})$ and queue-length bound $\tilde{O}(T^{2/3})$, where $T$ is the time horizon. We further establish a tradeoff between the regret bound and the queue-length bound: $\tilde{O}(T^{1-\gamma/4})$ versus $\tilde{O}(T^{\gamma})$ for $\gamma \in (0, 2/3].$
Cost Aware Best Arm Identification
Feb 26, 2024

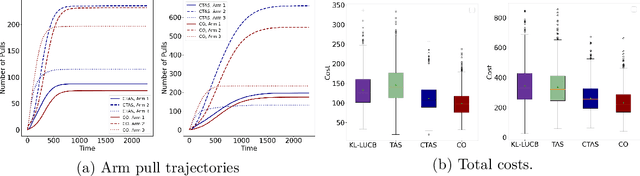
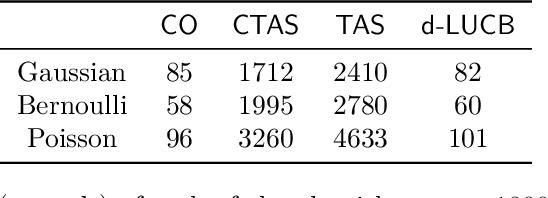
In this paper, we study a best arm identification problem with dual objects. In addition to the classic reward, each arm is associated with a cost distribution and the goal is to identify the largest reward arm using the minimum expected cost. We call it \emph{Cost Aware Best Arm Identification} (CABAI), which captures the separation of testing and implementation phases in product development pipelines and models the objective shift between phases, i.e., cost for testing and reward for implementation. We first derive an theoretic lower bound for CABAI and propose an algorithm called $\mathsf{CTAS}$ to match it asymptotically. To reduce the computation of $\mathsf{CTAS}$, we further propose a low-complexity algorithm called CO, based on a square-root rule, which proves optimal in simplified two-armed models and generalizes surprisingly well in numerical experiments. Our results show (i) ignoring the heterogeneous action cost results in sub-optimality in practice, and (ii) low-complexity algorithms deliver near-optimal performance over a wide range of problems.
Safe Reinforcement Learning with Instantaneous Constraints: The Role of Aggressive Exploration
Dec 22, 2023

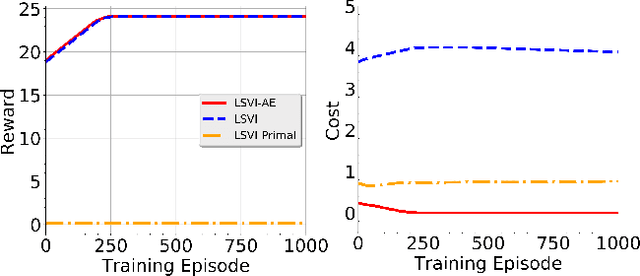
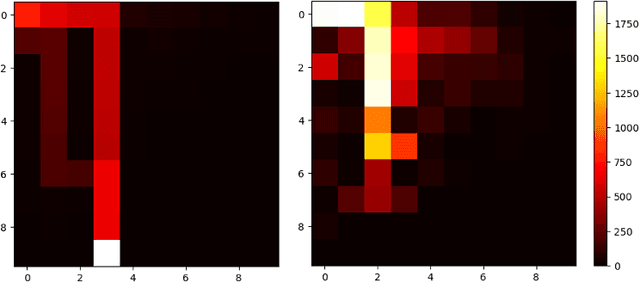
This paper studies safe Reinforcement Learning (safe RL) with linear function approximation and under hard instantaneous constraints where unsafe actions must be avoided at each step. Existing studies have considered safe RL with hard instantaneous constraints, but their approaches rely on several key assumptions: $(i)$ the RL agent knows a safe action set for {\it every} state or knows a {\it safe graph} in which all the state-action-state triples are safe, and $(ii)$ the constraint/cost functions are {\it linear}. In this paper, we consider safe RL with instantaneous hard constraints without assumption $(i)$ and generalize $(ii)$ to Reproducing Kernel Hilbert Space (RKHS). Our proposed algorithm, LSVI-AE, achieves $\tilde{\cO}(\sqrt{d^3H^4K})$ regret and $\tilde{\cO}(H \sqrt{dK})$ hard constraint violation when the cost function is linear and $\cO(H\gamma_K \sqrt{K})$ hard constraint violation when the cost function belongs to RKHS. Here $K$ is the learning horizon, $H$ is the length of each episode, and $\gamma_K$ is the information gain w.r.t the kernel used to approximate cost functions. Our results achieve the optimal dependency on the learning horizon $K$, matching the lower bound we provide in this paper and demonstrating the efficiency of LSVI-AE. Notably, the design of our approach encourages aggressive policy exploration, providing a unique perspective on safe RL with general cost functions and no prior knowledge of safe actions, which may be of independent interest.