 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Agents' Bias Amplification versus Suppression in Multi-Agent Systems
May 27, 2026Multi-agent systems are increasingly deployed to support various tasks where agents interact to achieve individual and collective objectives. Although these systems can enhance task performance and decision-making, fairness preservation through bias reduction remains challenging. This study examines how agent-level biases shift and impact system-wide fairness. We use prompts to expose individual agents to group-favoring bias, then assess downstream impacts at the system level. To quantify the impact, we propose Favor Bias Strength (FBS), a zero-centered metric that decomposes bias alteration between favored-group uplift and disfavored-group suppression. Using multiple agent designs, benchmarks, and up-to-date large language models, we show that agents endowed with bias can substantially affect system-wide fairness. Interestingly, when agents are exposed to bias uniformly, the system-wide bias elevates, even exceeding the additive sum of the individual agents' biases. The empirical evidence underscores the criticality of fairness in multi-agent systems, which warrants further analyses and empirical tests.
Text-to-Distribution Prediction with Quantile Tokens and Neighbor Context
Apr 22, 2026Many applications of LLM-based text regression require predicting a full conditional distribution rather than a single point value. We study distributional regression under empirical-quantile supervision, where each input is paired with multiple observed quantile outcomes, and the target distribution is represented by a dense grid of quantiles. We address two key limitations of current approaches: the lack of local grounding for distribution estimates, and the reliance on shared representations that create an indirect bottleneck between inputs and quantile outputs. In this paper, we introduce Quantile Token Regression, which, to our knowledge, is the first work to insert dedicated quantile tokens into the input sequence, enabling direct input-output pathways for each quantile through self-attention. We further augment these quantile tokens with retrieval, incorporating semantically similar neighbor instances and their empirical distributions to ground predictions with local evidence from similar instances. We also provide the first theoretical analysis of loss functions for quantile regression, clarifying which distributional objectives each optimizes. Experiments on the Inside Airbnb and StackSample benchmark datasets with LLMs ranging from 1.7B to 14B parameters show that quantile tokens with neighbors consistently outperform baselines (~4 points lower MAPE and 2x narrower prediction intervals), with especially large gains on smaller and more challenging datasets where quantile tokens produce substantially sharper and more accurate distributions.
Low-Rank Adaptation for Critic Learning in Off-Policy Reinforcement Learning
Apr 21, 2026Scaling critic capacity is a promising direction for enhancing off-policy reinforcement learning (RL). However, larger critics are prone to overfitting and unstable in replay-buffer-based bootstrap training. This paper leverages Low-Rank Adaptation (LoRA) as a structural-sparsity regularizer for off-policy critics. Our approach freezes randomly initialized base matrices and solely optimizes low-rank adapters, thereby constraining critic updates to a low-dimensional subspace. Built on top of SimbaV2, we further develop a LoRA formulation, compatible with SimbaV2, that preserves its hyperspherical normalization geometry under frozen-backbone training. We evaluate our method with SAC and FastTD3 on DeepMind Control locomotion and IsaacLab robotics benchmarks. LoRA consistently achieves lower critic loss during training and stronger policy performance. Extensive experiments demonstrate that adaptive low-rank updates provide a simple, scalable, and effective structural regularization for critic learning in off-policy RL.
Rhetorical Questions in LLM Representations: A Linear Probing Study
Apr 15, 2026Rhetorical questions are asked not to seek information but to persuade or signal stance. How large language models internally represent them remains unclear. We analyze rhetorical questions in LLM representations using linear probes on two social-media datasets with different discourse contexts, and find that rhetorical signals emerge early and are most stably captured by last-token representations. Rhetorical questions are linearly separable from information-seeking questions within datasets, and remain detectable under cross-dataset transfer, reaching AUROC around 0.7-0.8. However, we demonstrate that transferability does not simply imply a shared representation. Probes trained on different datasets produce different rankings when applied to the same target corpus, with overlap among the top-ranked instances often below 0.2. Qualitative analysis shows that these divergences correspond to distinct rhetorical phenomena: some probes capture discourse-level rhetorical stance embedded in extended argumentation, while others emphasize localized, syntax-driven interrogative acts. Together, these findings suggest that rhetorical questions in LLM representations are encoded by multiple linear directions emphasizing different cues, rather than a single shared direction.
MTVHunter: Smart Contracts Vulnerability Detection Based on Multi-Teacher Knowledge Translation
Feb 24, 2025Smart contracts, closely intertwined with cryptocurrency transactions, have sparked widespread concerns about considerable financial losses of security issues. To counteract this, a variety of tools have been developed to identify vulnerability in smart contract. However, they fail to overcome two challenges at the same time when faced with smart contract bytecode: (i) strong interference caused by enormous non-relevant instructions; (ii) missing semantics of bytecode due to incomplete data and control flow dependencies. In this paper, we propose a multi-teacher based bytecode vulnerability detection method, namely Multi-Teacher Vulnerability Hunter (MTVHunter), which delivers effective denoising and missing semantic to bytecode under multi-teacher guidance. Specifically, we first propose an instruction denoising teacher to eliminate noise interference by abstract vulnerability pattern and further reflect in contract embeddings. Secondly, we design a novel semantic complementary teacher with neuron distillation, which effectively extracts necessary semantic from source code to replenish the bytecode. Particularly, the proposed neuron distillation accelerate this semantic filling by turning the knowledge transition into a regression task. We conduct experiments on 229,178 real-world smart contracts that concerns four types of common vulnerabilities. Extensive experiments show MTVHunter achieves significantly performance gains over state-of-the-art approaches.
A Robust and Efficient Visual-Inertial Initialization with Probabilistic Normal Epipolar Constraint
Oct 25, 2024



Accurate and robust initialization is essential for Visual-Inertial Odometry (VIO), as poor initialization can severely degrade pose accuracy. During initialization, it is crucial to estimate parameters such as accelerometer bias, gyroscope bias, initial velocity, and gravity, etc. The IMU sensor requires precise estimation of gyroscope bias because gyroscope bias affects rotation, velocity and position. Most existing VIO initialization methods adopt Structure from Motion (SfM) to solve for gyroscope bias. However, SfM is not stable and efficient enough in fast motion or degenerate scenes. To overcome these limitations, we extended the rotation-translation-decoupling framework by adding new uncertainty parameters and optimization modules. First, we adopt a gyroscope bias optimizer that incorporates probabilistic normal epipolar constraints. Second, we fuse IMU and visual measurements to solve for velocity, gravity, and scale efficiently. Finally, we design an additional refinement module that effectively diminishes gravity and scale errors. Extensive initialization tests on the EuRoC dataset show that our method reduces the gyroscope bias and rotation estimation error by an average of 16% and 4% respectively. It also significantly reduces the gravity error, with an average reduction of 29%.
Snail-Radar: A large-scale diverse dataset for the evaluation of 4D-radar-based SLAM systems
Jul 16, 2024



4D radars are increasingly favored for odometry and mapping of autonomous systems due to their robustness in harsh weather and dynamic environments. Existing datasets, however, often cover limited areas and are typically captured using a single platform. To address this gap, we present a diverse large-scale dataset specifically designed for 4D radar-based localization and mapping. This dataset was gathered using three different platforms: a handheld device, an e-bike, and an SUV, under a variety of environmental conditions, including clear days, nighttime, and heavy rain. The data collection occurred from September 2023 to February 2024, encompassing diverse settings such as roads in a vegetated campus and tunnels on highways. Each route was traversed multiple times to facilitate place recognition evaluations. The sensor suite included a 3D lidar, 4D radars, stereo cameras, consumer-grade IMUs, and a GNSS/INS system. Sensor data packets were synchronized to GNSS time using a two-step process: a convex hull algorithm was applied to smooth host time jitter, and then odometry and correlation algorithms were used to correct constant time offsets. Extrinsic calibration between sensors was achieved through manual measurements and subsequent nonlinear optimization. The reference motion for the platforms was generated by registering lidar scans to a terrestrial laser scanner (TLS) point cloud map using a lidar inertial odometry (LIO) method in localization mode. Additionally, a data reversion technique was introduced to enable backward LIO processing. We believe this dataset will boost research in radar-based point cloud registration, odometry, mapping, and place recognition.
Tightly-Coupled VLP/INS Integrated Navigation by Inclination Estimation and Blockage Handling
Apr 28, 2024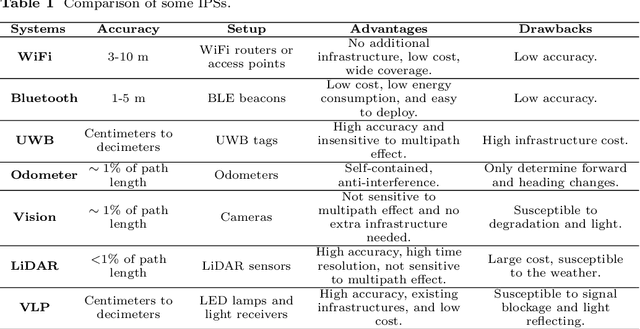
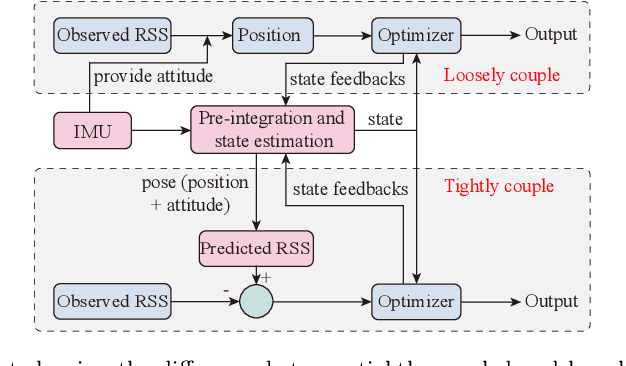


Visible Light Positioning (VLP) has emerged as a promising technology capable of delivering indoor localization with high accuracy. In VLP systems that use Photodiodes (PDs) as light receivers, the Received Signal Strength (RSS) is affected by the incidence angle of light, making the inclination of PDs a critical parameter in the positioning model. Currently, most studies assume the inclination to be constant, limiting the applications and positioning accuracy. Additionally, light blockages may severely interfere with the RSS measurements but the literature has not explored blockage detection in real-world experiments. To address these problems, we propose a tightly coupled VLP/INS (Inertial Navigation System) integrated navigation system that uses graph optimization to account for varying PD inclinations and VLP blockages. We also discussed the possibility of simultaneously estimating the robot's pose and the locations of some unknown LEDs. Simulations and two groups of real-world experiments demonstrate the efficiency of our approach, achieving an average positioning accuracy of 10 cm during movement and inclination accuracy within 1 degree despite inclination changes and blockages.
Exploring the Intersection of Complex Aesthetics and Generative AI for Promoting Cultural Creativity in Rural China after the Post-Pandemic Era
Sep 05, 2023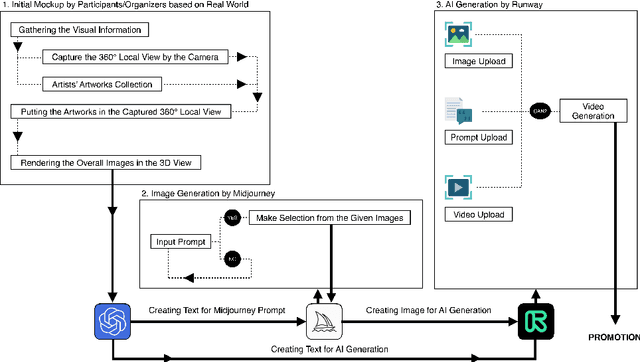
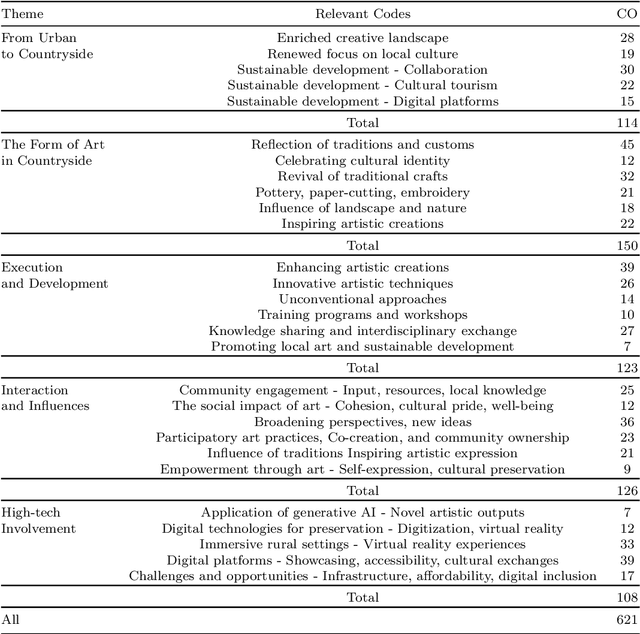
This paper explores using generative AI and aesthetics to promote cultural creativity in rural China amidst COVID-19's impact. Through literature reviews, case studies, surveys, and text analysis, it examines art and technology applications in rural contexts and identifies key challenges. The study finds artworks often fail to resonate locally, while reliance on external artists limits sustainability. Hence, nurturing grassroots "artist villagers" through AI is proposed. Our approach involves training machine learning on subjective aesthetics to generate culturally relevant content. Interactive AI media can also boost tourism while preserving heritage. This pioneering research puts forth original perspectives on the intersection of AI and aesthetics to invigorate rural culture. It advocates holistic integration of technology and emphasizes AI's potential as a creative enabler versus replacement. Ultimately, it lays the groundwork for further exploration of leveraging AI innovations to empower rural communities. This timely study contributes to growing interest in emerging technologies to address critical issues facing rural China.
3D-SeqMOS: A Novel Sequential 3D Moving Object Segmentation in Autonomous Driving
Jul 18, 2023
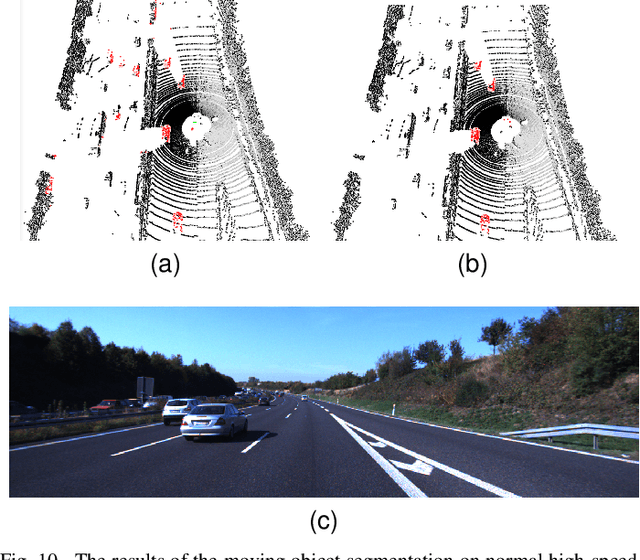
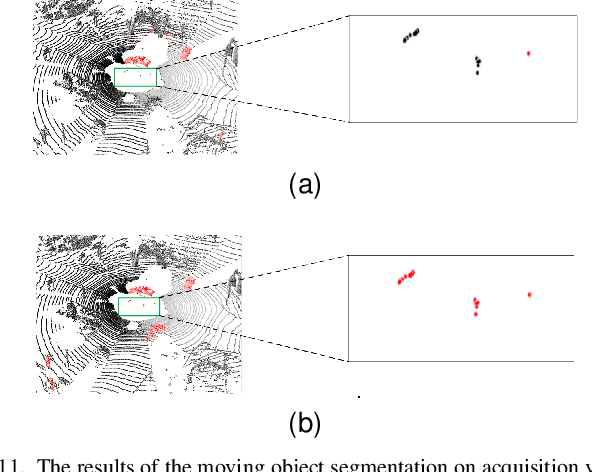
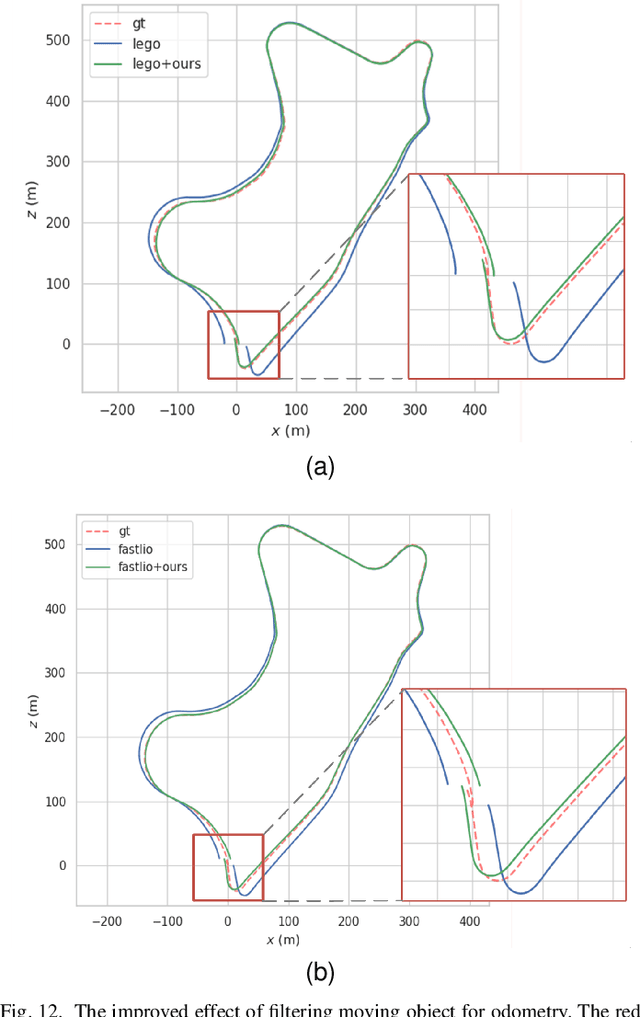
For the SLAM system in robotics and autonomous driving, the accuracy of front-end odometry and back-end loop-closure detection determine the whole intelligent system performance. But the LiDAR-SLAM could be disturbed by current scene moving objects, resulting in drift errors and even loop-closure failure. Thus, the ability to detect and segment moving objects is essential for high-precision positioning and building a consistent map. In this paper, we address the problem of moving object segmentation from 3D LiDAR scans to improve the odometry and loop-closure accuracy of SLAM. We propose a novel 3D Sequential Moving-Object-Segmentation (3D-SeqMOS) method that can accurately segment the scene into moving and static objects, such as moving and static cars. Different from the existing projected-image method, we process the raw 3D point cloud and build a 3D convolution neural network for MOS task. In addition, to make full use of the spatio-temporal information of point cloud, we propose a point cloud residual mechanism using the spatial features of current scan and the temporal features of previous residual scans. Besides, we build a complete SLAM framework to verify the effectiveness and accuracy of 3D-SeqMOS. Experiments on SemanticKITTI dataset show that our proposed 3D-SeqMOS method can effectively detect moving objects and improve the accuracy of LiDAR odometry and loop-closure detection. The test results show our 3D-SeqMOS outperforms the state-of-the-art method by 12.4%. We extend the proposed method to the SemanticKITTI: Moving Object Segmentation competition and achieve the 2nd in the leaderboard, showing its effectiveness.