 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTVHunter: Smart Contracts Vulnerability Detection Based on Multi-Teacher Knowledge Translation
Feb 24, 2025Smart contracts, closely intertwined with cryptocurrency transactions, have sparked widespread concerns about considerable financial losses of security issues. To counteract this, a variety of tools have been developed to identify vulnerability in smart contract. However, they fail to overcome two challenges at the same time when faced with smart contract bytecode: (i) strong interference caused by enormous non-relevant instructions; (ii) missing semantics of bytecode due to incomplete data and control flow dependencies. In this paper, we propose a multi-teacher based bytecode vulnerability detection method, namely Multi-Teacher Vulnerability Hunter (MTVHunter), which delivers effective denoising and missing semantic to bytecode under multi-teacher guidance. Specifically, we first propose an instruction denoising teacher to eliminate noise interference by abstract vulnerability pattern and further reflect in contract embeddings. Secondly, we design a novel semantic complementary teacher with neuron distillation, which effectively extracts necessary semantic from source code to replenish the bytecode. Particularly, the proposed neuron distillation accelerate this semantic filling by turning the knowledge transition into a regression task. We conduct experiments on 229,178 real-world smart contracts that concerns four types of common vulnerabilities. Extensive experiments show MTVHunter achieves significantly performance gains over state-of-the-art approaches.
SEFormer: Structure Embedding Transformer for 3D Object Detection
Sep 05, 2022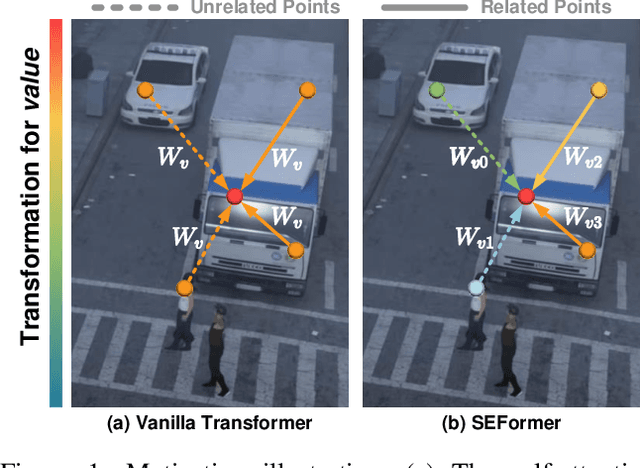
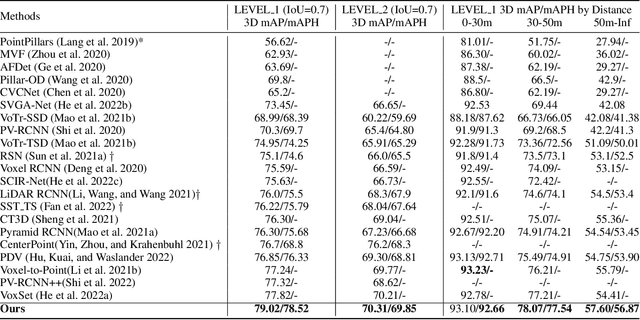
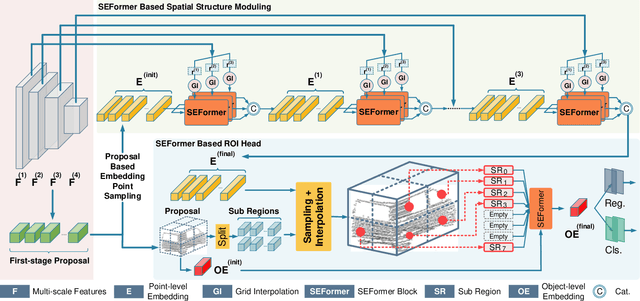
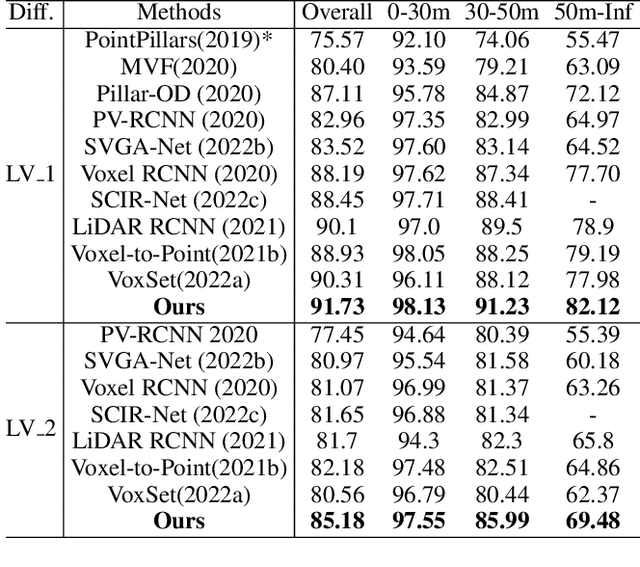
Effectively preserving and encoding structure features from objects in irregular and sparse LiDAR points is a key challenge to 3D object detection on point cloud. Recently, Transformer has demonstrated promising performance on many 2D and even 3D vision tasks. Compared with the fixed and rigid convolution kernels, the self-attention mechanism in Transformer can adaptively exclude the unrelated or noisy points and thus suitable for preserving the local spatial structure in irregular LiDAR point cloud. However, Transformer only performs a simple sum on the point features, based on the self-attention mechanism, and all the points share the same transformation for value. Such isotropic operation lacks the ability to capture the direction-distance-oriented local structure which is important for 3D object detection. In this work, we propose a Structure-Embedding transFormer (SEFormer), which can not only preserve local structure as traditional Transformer but also have the ability to encode the local structure. Compared to the self-attention mechanism in traditional Transformer, SEFormer learns different feature transformations for value points based on the relative directions and distances to the query point. Then we propose a SEFormer based network for high-performance 3D object detection. Extensive experiments show that the proposed architecture can achieve SOTA results on Waymo Open Dataset, the largest 3D detection benchmark for autonomous driving. Specifically, SEFormer achieves 79.02% mAP, which is 1.2% higher than existing works. We will release the codes.
ADMP: An Adversarial Double Masks Based Pruning Framework For Unsupervised Cross-Domain Compression
Jun 07, 2020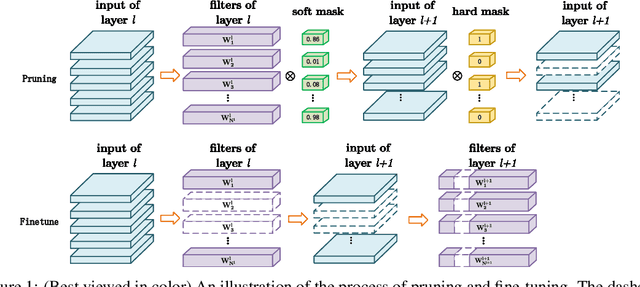
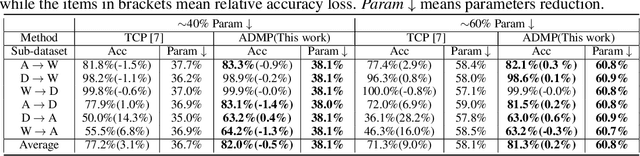
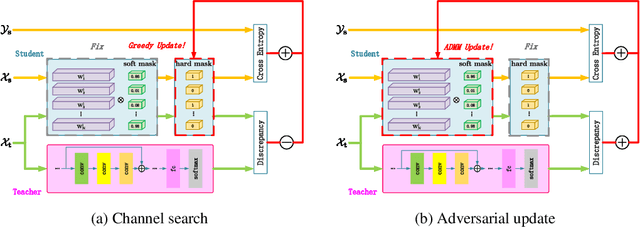
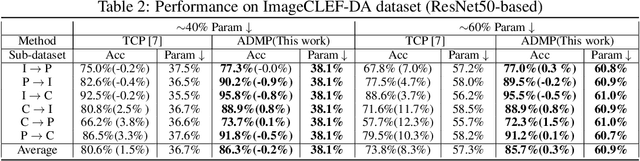
Despite the recent progress of network pruning, directly applying it to the Internet of Things (IoT) applications still faces two challenges, i.e. the distribution divergence between end and cloud data and the missing of data label on end devices. One straightforward solution is to combine the unsupervised domain adaptation (UDA) technique and pruning. For example, the model is first pruned on the cloud and then transferred from cloud to end by UDA. However, such a naive combination faces high performance degradation. Hence this work proposes an Adversarial Double Masks based Pruning (ADMP) for such cross-domain compression. In ADMP, we construct a Knowledge Distillation framework not only to produce pseudo labels but also to provide a measurement of domain divergence as the output difference between the full-size teacher and the pruned student. Unlike existing mask-based pruning works, two adversarial masks, i.e. soft and hard masks, are adopted in ADMP. So ADMP can prune the model effectively while still allowing the model to extract strong domain-invariant features and robust classification boundaries. During training, the Alternating Direction Multiplier Method is used to overcome the binary constraint of {0,1}-masks. On Office31 and ImageCLEF-DA datasets, the proposed ADMP can prune 60% channels with only 0.2% and 0.3% average accuracy loss respectively. Compared with the state of art, we can achieve about 1.63x parameters reduction and 4.1% and 5.1% accuracy improvement.
Progressive DNN Compression: A Key to Achieve Ultra-High Weight Pruning and Quantization Rates using ADMM
Mar 30, 2019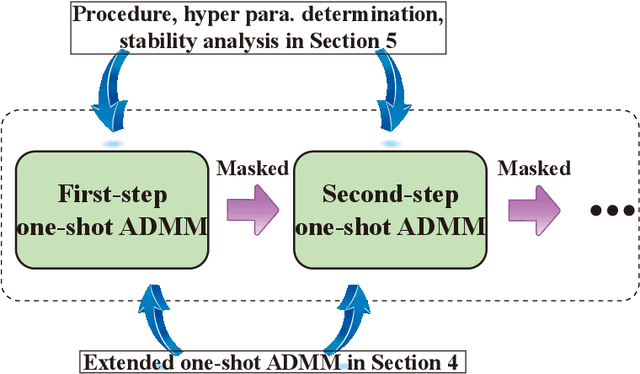
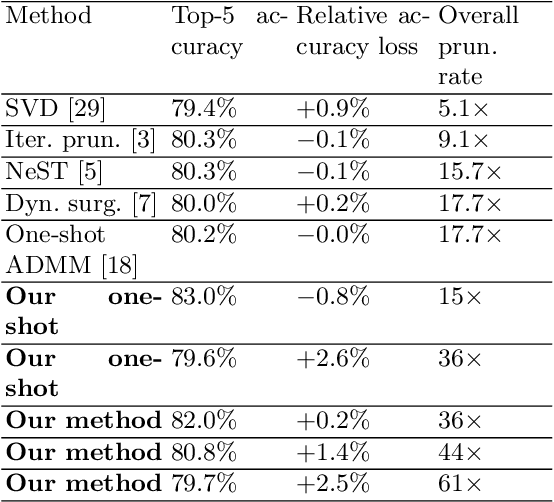

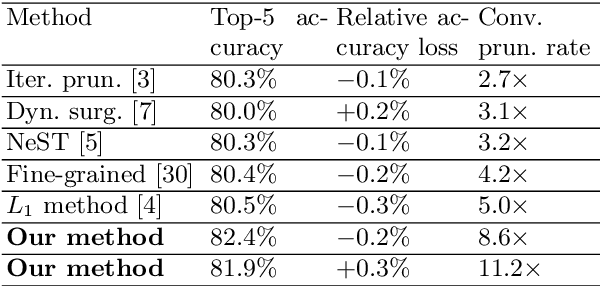
Weight pruning and weight quantization are two important categories of DNN model compression. Prior work on these techniques are mainly based on heuristics. A recent work developed a systematic frame-work of DNN weight pruning using the advanced optimization technique ADMM (Alternating Direction Methods of Multipliers), achieving one of state-of-art in weight pruning results. In this work, we first extend such one-shot ADMM-based framework to guarantee solution feasibility and provide fast convergence rate, and generalize to weight quantization as well. We have further developed a multi-step, progressive DNN weight pruning and quantization framework, with dual benefits of (i) achieving further weight pruning/quantization thanks to the special property of ADMM regularization, and (ii) reducing the search space within each step. Extensive experimental results demonstrate the superior performance compared with prior work. Some highlights: (i) we achieve 246x,36x, and 8x weight pruning on LeNet-5, AlexNet, and ResNet-50 models, respectively, with (almost) zero accuracy loss; (ii) even a significant 61x weight pruning in AlexNet (ImageNet) results in only minor degradation in actual accuracy compared with prior work; (iii) we are among the first to derive notable weight pruning results for ResNet and MobileNet models; (iv) we derive the first lossless, fully binarized (for all layers) LeNet-5 for MNIST and VGG-16 for CIFAR-10; and (v) we derive the first fully binarized (for all layers) ResNet for ImageNet with reasonable accuracy loss.