 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2O: Early Stopping for Sparse Attention via Online Permutation
Feb 26, 2026Attention scales quadratically with sequence length, fundamentally limiting long-context inference. Existing block-granularity sparsification can reduce latency, but coarse blocks impose an intrinsic sparsity ceiling, making further improvements difficult even with carefully engineered designs. We present S2O, which performs early stopping for sparse attention via online permutation. Inspired by virtual-to-physical address mapping in memory systems, S2O revisits and factorizes FlashAttention execution, enabling inference to load non-contiguous tokens rather than a contiguous span in the original order. Motivated by fine-grained structures in attention heatmaps, we transform explicit permutation into an online, index-guided, discrete loading policy; with extremely lightweight preprocessing and index-remapping overhead, it concentrates importance on a small set of high-priority blocks. Building on this importance-guided online permutation for loading, S2O further introduces an early-stopping rule: computation proceeds from high to low importance; once the current block score falls below a threshold, S2O terminates early and skips the remaining low-contribution blocks, thereby increasing effective sparsity and reducing computation under a controlled error budget. As a result, S2O substantially raises the practical sparsity ceiling. On Llama-3.1-8B under a 128K context, S2O reduces single-operator MSE by 3.82$\times$ at matched sparsity, and reduces prefill compute density by 3.31$\times$ at matched MSE; meanwhile, it preserves end-to-end accuracy and achieves 7.51$\times$ attention and 3.81$\times$ end-to-end speedups.
Demystifying Workload Imbalances in Large Transformer Model Training over Variable-length Sequences
Dec 10, 2024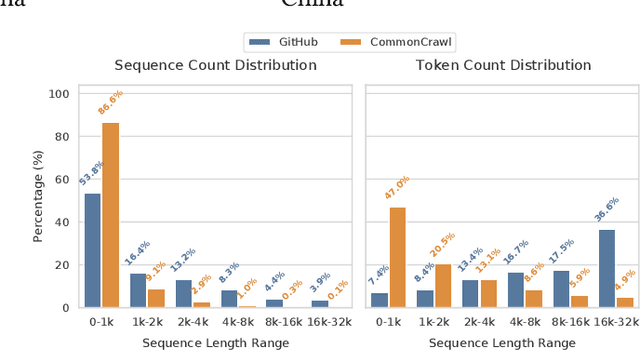
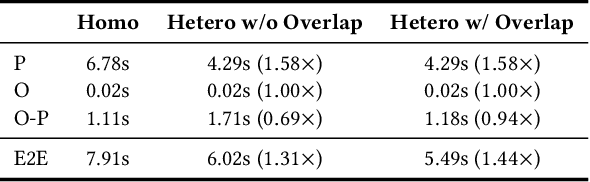
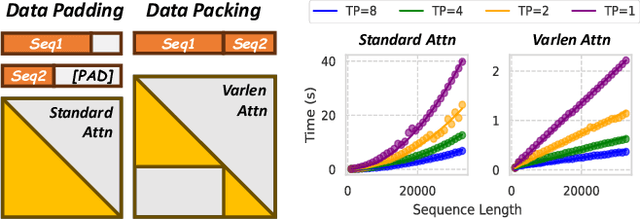

To optimize large Transformer model training, efficient parallel computing and advanced data management are essential. However, current methods often assume a stable and uniform training workload, neglecting imbalances in data sampling and packing that can impede performance. Specifically, data sampling imbalance arises from uneven sequence length distribution of the training data, while data packing imbalance stems from the discrepancy between the linear memory complexity and quadratic time complexity of the attention mechanism. To address these imbalance issues, we develop Hydraulis, which jointly optimizes the parallel strategies and data assignment. For one thing, we introduce large model training with dynamic heterogeneous parallel strategies in response to the sequence length variations within and across training iterations. For another, we devise a two-stage data assignment approach, which strikes a good balance in terms of the training workloads both within and across model replicas. Empirical results demonstrate that Hydraulis outperforms existing systems by 1.32-2.66 times.
Towards Zero Memory Footprint Spiking Neural Network Training
Aug 16, 2023


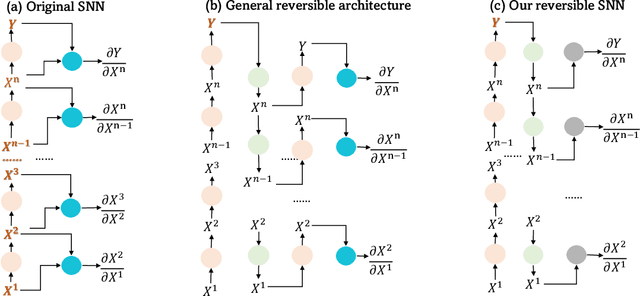
Biologically-inspired Spiking Neural Networks (SNNs), processing information using discrete-time events known as spikes rather than continuous values, have garnered significant attention due to their hardware-friendly and energy-efficient characteristics. However, the training of SNNs necessitates a considerably large memory footprint, given the additional storage requirements for spikes or events, leading to a complex structure and dynamic setup. In this paper, to address memory constraint in SNN training, we introduce an innovative framework, characterized by a remarkably low memory footprint. We \textbf{(i)} design a reversible SNN node that retains a high level of accuracy. Our design is able to achieve a $\mathbf{58.65\times}$ reduction in memory usage compared to the current SNN node. We \textbf{(ii)} propose a unique algorithm to streamline the backpropagation process of our reversible SNN node. This significantly trims the backward Floating Point Operations Per Second (FLOPs), thereby accelerating the training process in comparison to current reversible layer backpropagation method. By using our algorithm, the training time is able to be curtailed by $\mathbf{23.8\%}$ relative to existing reversible layer architectures.
FAIVConf: Face enhancement for AI-based Video Conference with Low Bit-rate
Jul 08, 2022
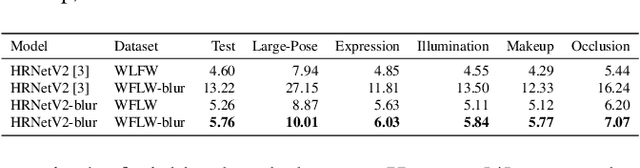
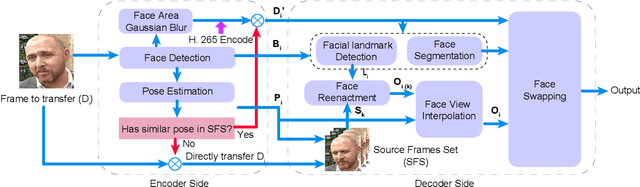
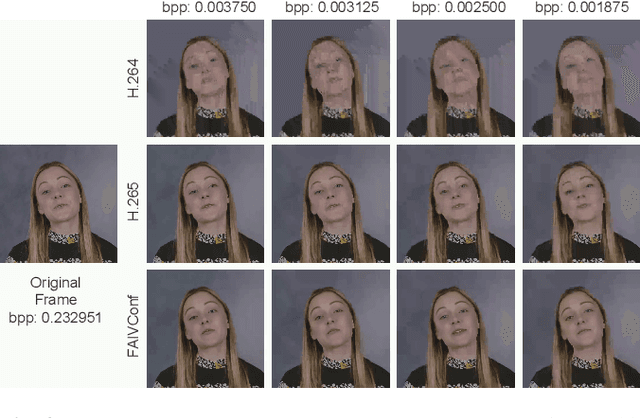
Recently, high-quality video conferencing with fewer transmission bits has become a very hot and challenging problem. We propose FAIVConf, a specially designed video compression framework for video conferencing, based on the effective neural human face generation techniques. FAIVConf brings together several designs to improve the system robustness in real video conference scenarios: face-swapping to avoid artifacts in background animation; facial blurring to decrease transmission bit-rate and maintain the quality of extracted facial landmarks; and dynamic source update for face view interpolation to accommodate a large range of head poses. Our method achieves a significant bit-rate reduction in the video conference and gives much better visual quality under the same bit-rate compared with H.264 and H.265 coding schemes.
A Secure and Efficient Federated Learning Framework for NLP
Jan 28, 2022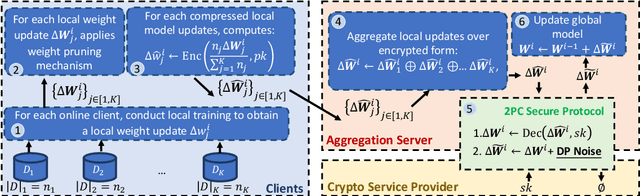
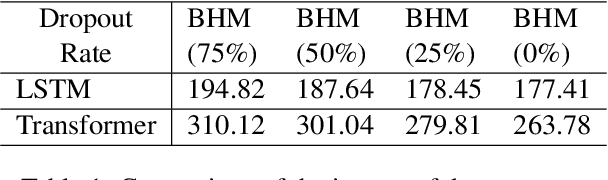
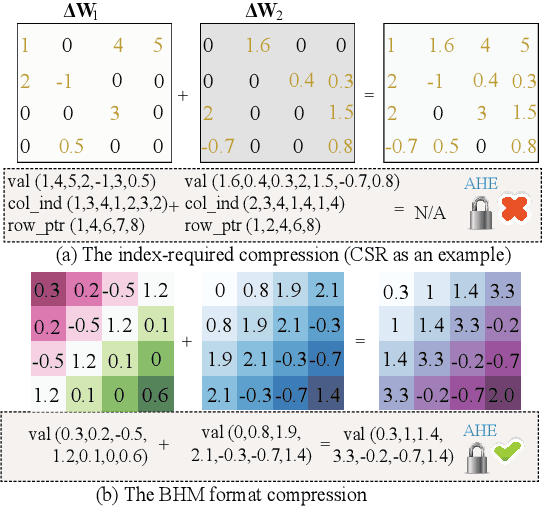
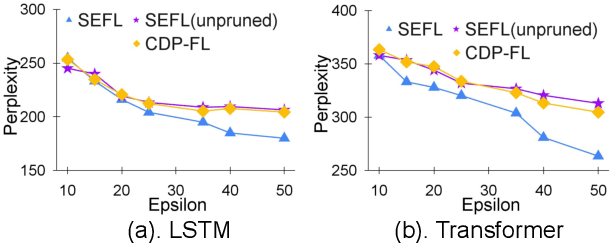
In this work, we consider the problem of designing secure and efficient federated learning (FL) frameworks. Existing solutions either involve a trusted aggregator or require heavyweight cryptographic primitives, which degrades performance significantly. Moreover, many existing secure FL designs work only under the restrictive assumption that none of the clients can be dropped out from the training protocol. To tackle these problems, we propose SEFL, a secure and efficient FL framework that (1) eliminates the need for the trusted entities; (2) achieves similar and even better model accuracy compared with existing FL designs; (3) is resilient to client dropouts. Through extensive experimental studies on natural language processing (NLP) tasks, we demonstrate that the SEFL achieves comparable accuracy compared to existing FL solutions, and the proposed pruning technique can improve runtime performance up to 13.7x.
CAP-RAM: A Charge-Domain In-Memory Computing 6T-SRAM for Accurate and Precision-Programmable CNN Inference
Jul 06, 2021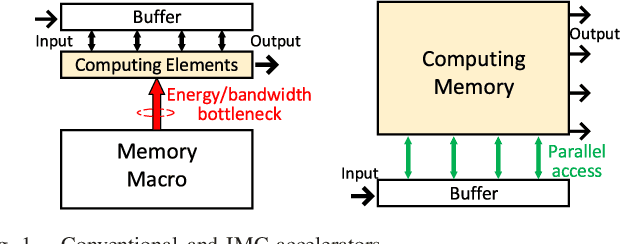
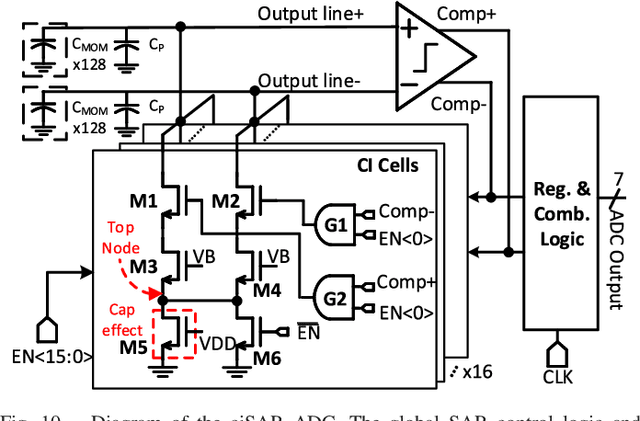
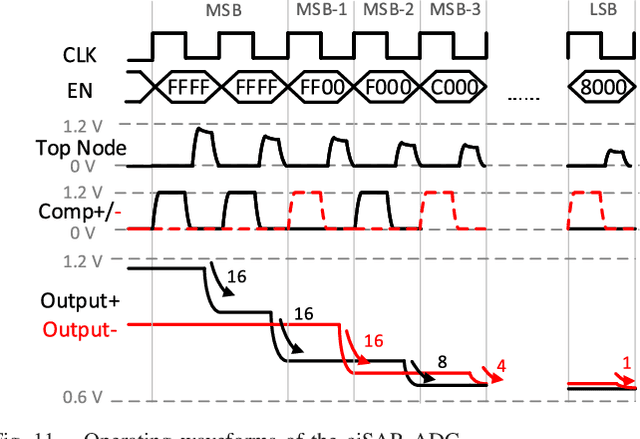
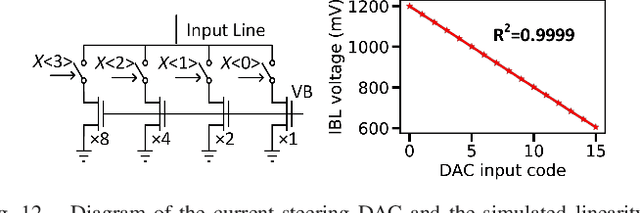
A compact, accurate, and bitwidth-programmable in-memory computing (IMC) static random-access memory (SRAM) macro, named CAP-RAM, is presented for energy-efficient convolutional neural network (CNN) inference. It leverages a novel charge-domain multiply-and-accumulate (MAC) mechanism and circuitry to achieve superior linearity under process variations compared to conventional IMC designs. The adopted semi-parallel architecture efficiently stores filters from multiple CNN layers by sharing eight standard 6T SRAM cells with one charge-domain MAC circuit. Moreover, up to six levels of bit-width of weights with two encoding schemes and eight levels of input activations are supported. A 7-bit charge-injection SAR (ciSAR) analog-to-digital converter (ADC) getting rid of sample and hold (S&H) and input/reference buffers further improves the overall energy efficiency and throughput. A 65-nm prototype validates the excellent linearity and computing accuracy of CAP-RAM. A single 512x128 macro stores a complete pruned and quantized CNN model to achieve 98.8% inference accuracy on the MNIST data set and 89.0% on the CIFAR-10 data set, with a 573.4-giga operations per second (GOPS) peak throughput and a 49.4-tera operations per second (TOPS)/W energy efficiency.
* This work has been accepted by IEEE Journal of Solid-State Circuits (JSSC 2021)
FORMS: Fine-grained Polarized ReRAM-based In-situ Computation for Mixed-signal DNN Accelerator
Jun 16, 2021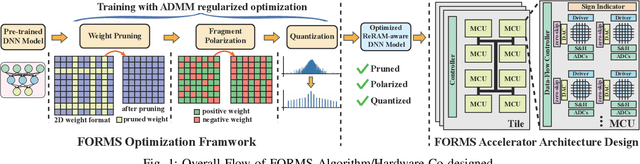
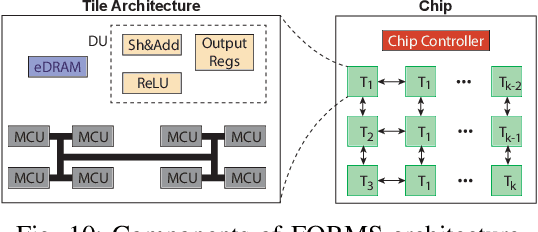
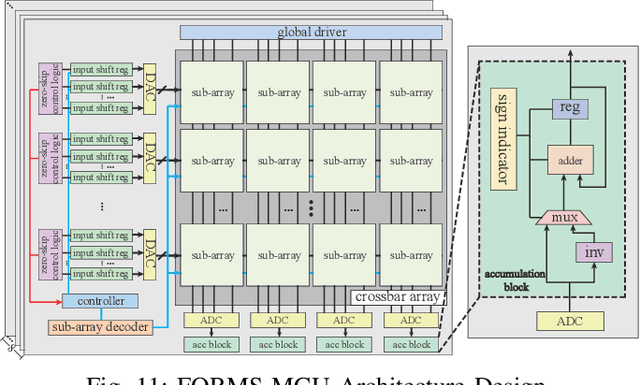

Recent works demonstrated the promise of using resistive random access memory (ReRAM) as an emerging technology to perform inherently parallel analog domain in-situ matrix-vector multiplication -- the intensive and key computation in DNNs. With weights stored in the ReRAM crossbar cells as conductance, when the input vector is applied to word lines, the matrix-vector multiplication results can be generated as the current in bit lines. A key problem is that the weight can be either positive or negative, but the in-situ computation assumes all cells on each crossbar column with the same sign. The current architectures either use two ReRAM crossbars for positive and negative weights, or add an offset to weights so that all values become positive. Neither solution is ideal: they either double the cost of crossbars, or incur extra offset circuity. To better solve this problem, this paper proposes FORMS, a fine-grained ReRAM-based DNN accelerator with polarized weights. Instead of trying to represent the positive/negative weights, our key design principle is to enforce exactly what is assumed in the in-situ computation -- ensuring that all weights in the same column of a crossbar have the same sign. It naturally avoids the cost of an additional crossbar. Such weights can be nicely generated using alternating direction method of multipliers (ADMM) regularized optimization, which can exactly enforce certain patterns in DNN weights. To achieve high accuracy, we propose to use fine-grained sub-array columns, which provide a unique opportunity for input zero-skipping, significantly avoiding unnecessary computations. It also makes the hardware much easier to implement. Putting all together, with the same optimized models, FORMS achieves significant throughput improvement and speed up in frame per second over ISAAC with similar area cost.
Efficient Micro-Structured Weight Unification and Pruning for Neural Network Compression
Jun 16, 2021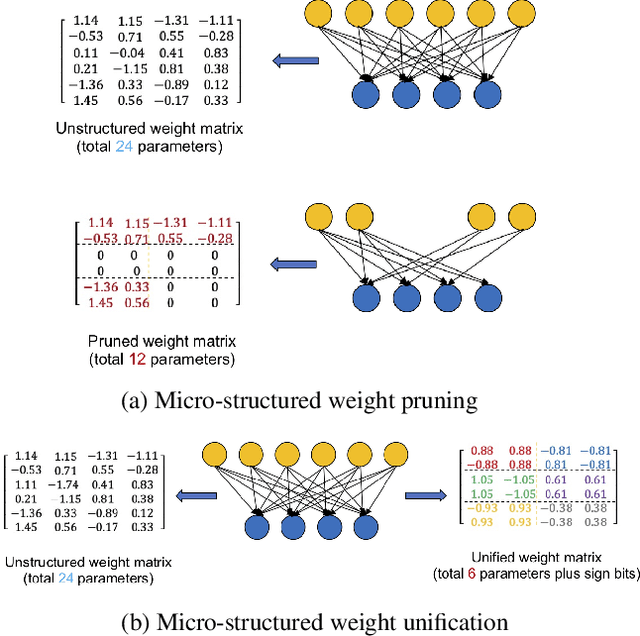

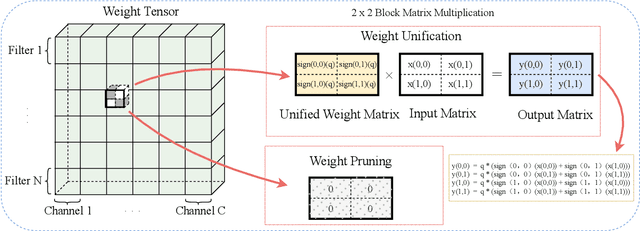
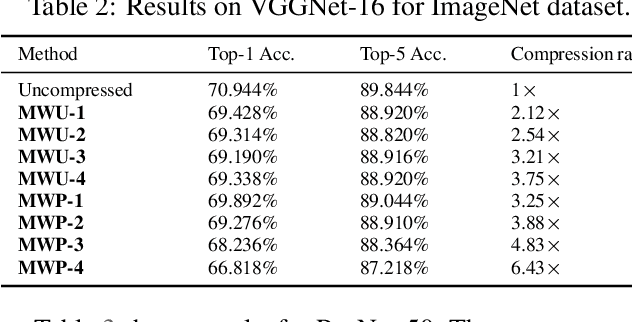
Compressing Deep Neural Network (DNN) models to alleviate the storage and computation requirements is essential for practical applications, especially for resource limited devices. Although capable of reducing a reasonable amount of model parameters, previous unstructured or structured weight pruning methods can hardly truly accelerate inference, either due to the poor hardware compatibility of the unstructured sparsity or due to the low sparse rate of the structurally pruned network. Aiming at reducing both storage and computation, as well as preserving the original task performance, we propose a generalized weight unification framework at a hardware compatible micro-structured level to achieve high amount of compression and acceleration. Weight coefficients of a selected micro-structured block are unified to reduce the storage and computation of the block without changing the neuron connections, which turns to a micro-structured pruning special case when all unified coefficients are set to zero, where neuron connections (hence storage and computation) are completely removed. In addition, we developed an effective training framework based on the alternating direction method of multipliers (ADMM), which converts our complex constrained optimization into separately solvable subproblems. Through iteratively optimizing the subproblems, the desired micro-structure can be ensured with high compression ratio and low performance degradation. We extensively evaluated our method using a variety of benchmark models and datasets for different applications. Experimental results demonstrate state-of-the-art performance.
ESMFL: Efficient and Secure Models for Federated Learning
Sep 03, 2020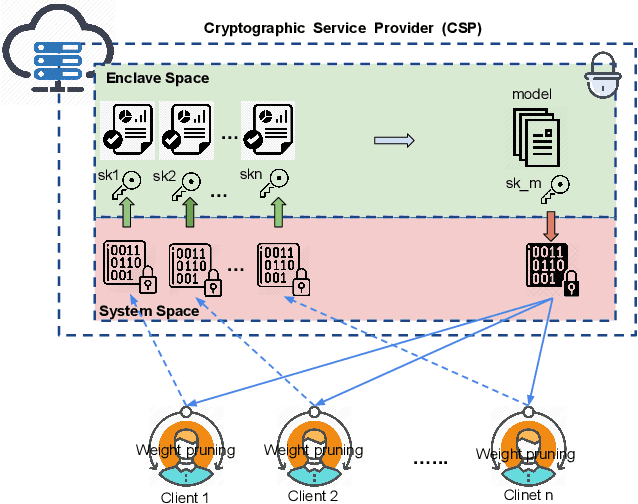
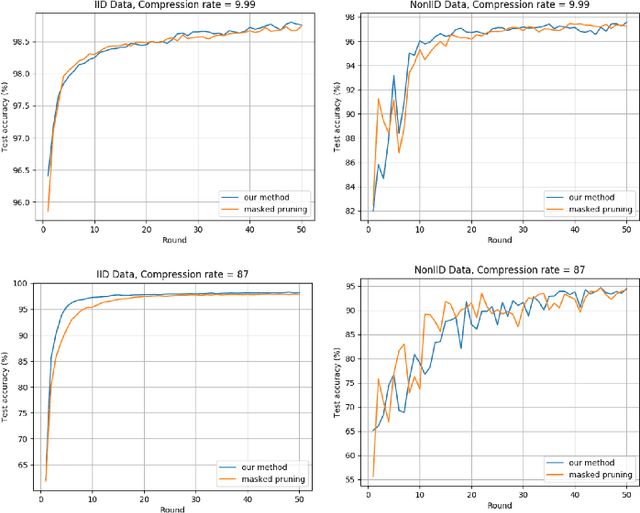
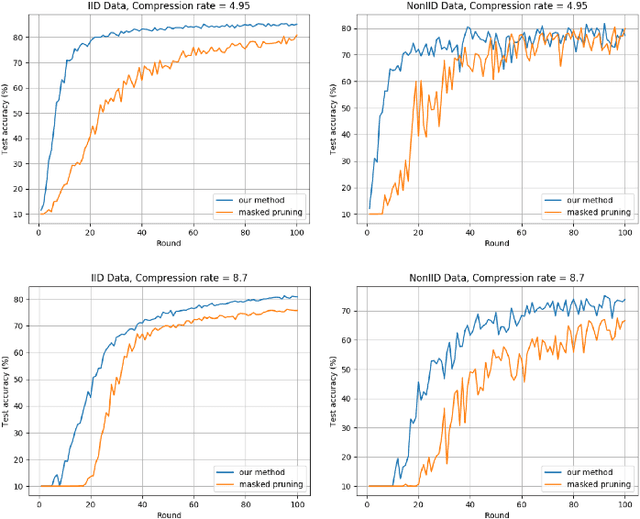
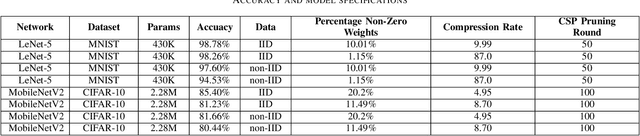
Deep Neural Networks are widely applied to various domains. The successful deployment of these applications is everywhere and it depends on the availability of big data. However, massive data collection required for deep neural network reveals the potential privacy issues and also consumes large mounts of communication bandwidth. To address this problem, we propose a privacy-preserving method for the federated learning distributed system, operated on Intel Software Guard Extensions, a set of instructions that increases the security of application code and data. Meanwhile, the encrypted models make the transmission overhead larger. Hence, we reduce the commutation cost by sparsification and achieve reasonable accuracy with different model architectures. Experimental results under our privacy-preserving framework show that, for LeNet-5, we obtain 98.78% accuracy on IID data and 97.60% accuracy on Non-IID data with 34.85% communication saving, and 1.8X total elapsed time acceleration. For MobileNetV2, we obtain 85.40% accuracy on IID data and 81.66% accuracy on Non-IID data with 15.85% communication saving, and 1.2X total elapsed time acceleration.
An Image Enhancing Pattern-based Sparsity for Real-time Inference on Mobile Devices
Feb 22, 2020
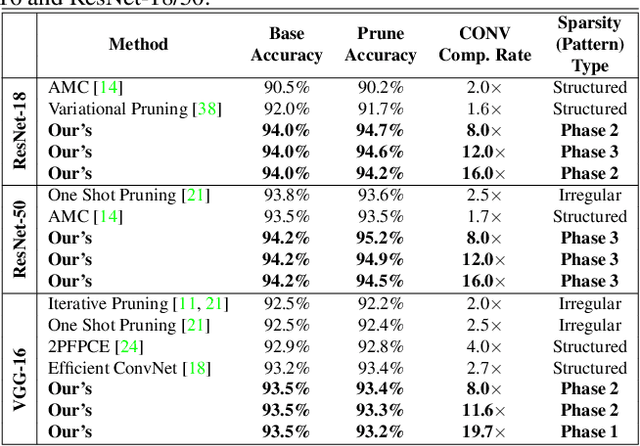
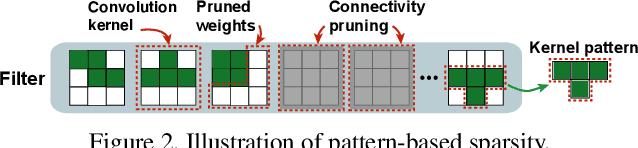
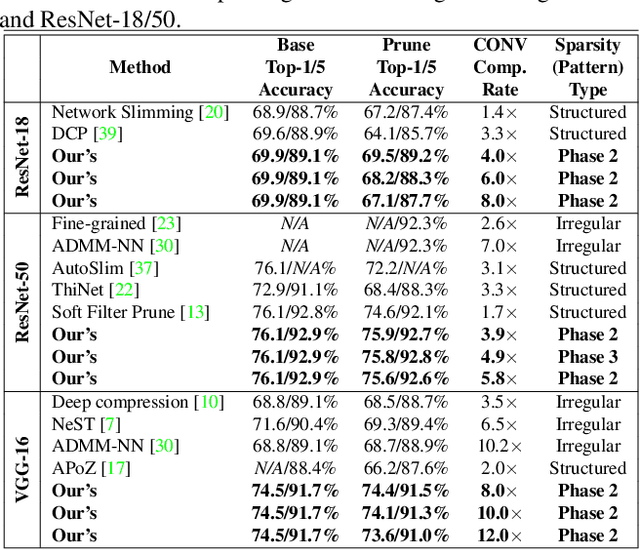
Weight pruning has been widely acknowledged as a straightforward and effective method to eliminate redundancy in Deep Neural Networks (DNN), thereby achieving acceleration on various platforms. However, most of the pruning techniques are essentially trade-offs between model accuracy and regularity which lead to impaired inference accuracy and limited on-device acceleration performance. To solve the problem, we introduce a new sparsity dimension, namely pattern-based sparsity that comprises pattern and connectivity sparsity, and becoming both highly accurate and hardware friendly. With carefully designed patterns, the proposed pruning unprecedentedly and consistently achieves accuracy enhancement and better feature extraction ability on different DNN structures and datasets, and our pattern-aware pruning framework also achieves pattern library extraction, pattern selection, pattern and connectivity pruning and weight training simultaneously. Our approach on the new pattern-based sparsity naturally fits into compiler optimization for highly efficient DNN execution on mobile platforms. To the best of our knowledge, it is the first time that mobile devices achieve real-time inference for the large-scale DNN models thanks to the unique spatial property of pattern-based sparsity and the help of the code generation capability of compilers.