 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Low-Rank Method for Vision Language Model Hallucination Mitigation in Autonomous Driving
Nov 09, 2025
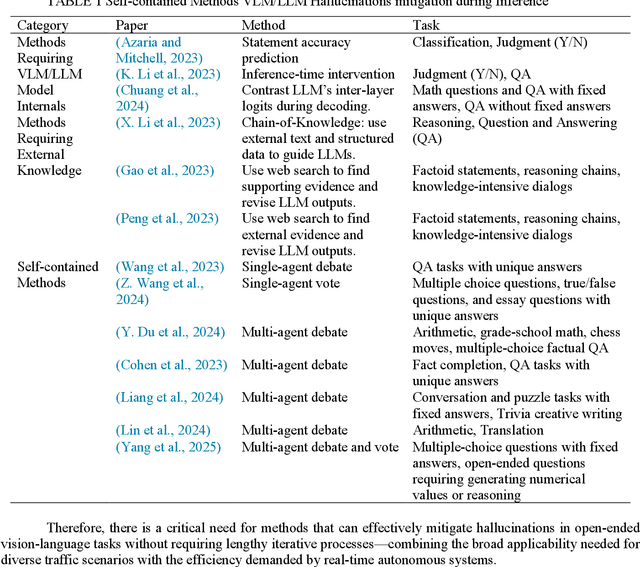

Vision Language Models (VLMs) are increasingly used in autonomous driving to help understand traffic scenes, but they sometimes produce hallucinations, which are false details not grounded in the visual input. Detecting and mitigating hallucinations is challenging when ground-truth references are unavailable and model internals are inaccessible. This paper proposes a novel self-contained low-rank approach to automatically rank multiple candidate captions generated by multiple VLMs based on their hallucination levels, using only the captions themselves without requiring external references or model access. By constructing a sentence-embedding matrix and decomposing it into a low-rank consensus component and a sparse residual, we use the residual magnitude to rank captions: selecting the one with the smallest residual as the most hallucination-free. Experiments on the NuScenes dataset demonstrate that our approach achieves 87% selection accuracy in identifying hallucination-free captions, representing a 19% improvement over the unfiltered baseline and a 6-10% improvement over multi-agent debate method. The sorting produced by sparse error magnitudes shows strong correlation with human judgments of hallucinations, validating our scoring mechanism. Additionally, our method, which can be easily parallelized, reduces inference time by 51-67% compared to debate approaches, making it practical for real-time autonomous driving applications.
PFedDST: Personalized Federated Learning with Decentralized Selection Training
Feb 11, 2025
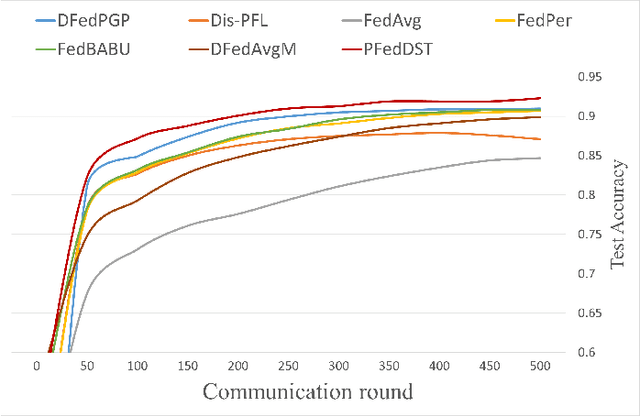
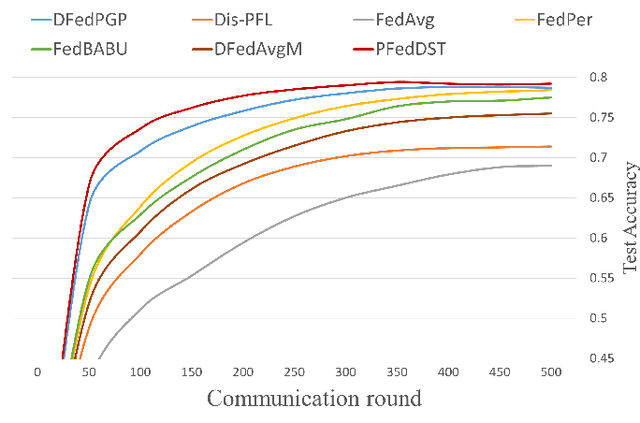
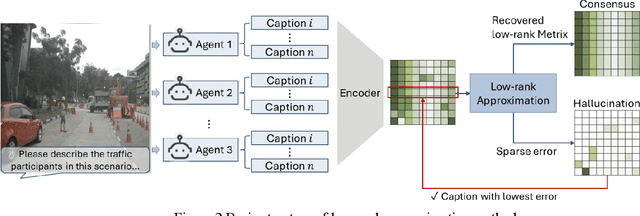
Distributed Learning (DL) enables the training of machine learning models across multiple devices, yet it faces challenges like non-IID data distributions and device capability disparities, which can impede training efficiency. Communication bottlenecks further complicate traditional Federated Learning (FL) setups. To mitigate these issues, we introduce the Personalized Federated Learning with Decentralized Selection Training (PFedDST) framework. PFedDST enhances model training by allowing devices to strategically evaluate and select peers based on a comprehensive communication score. This score integrates loss, task similarity, and selection frequency, ensuring optimal peer connections. This selection strategy is tailored to increase local personalization and promote beneficial peer collaborations to strengthen the stability and efficiency of the training process. Our experiments demonstrate that PFedDST not only enhances model accuracy but also accelerates convergence. This approach outperforms state-of-the-art methods in handling data heterogeneity, delivering both faster and more effective training in diverse and decentralized systems.
Stealthy Multi-Task Adversarial Attacks
Nov 26, 2024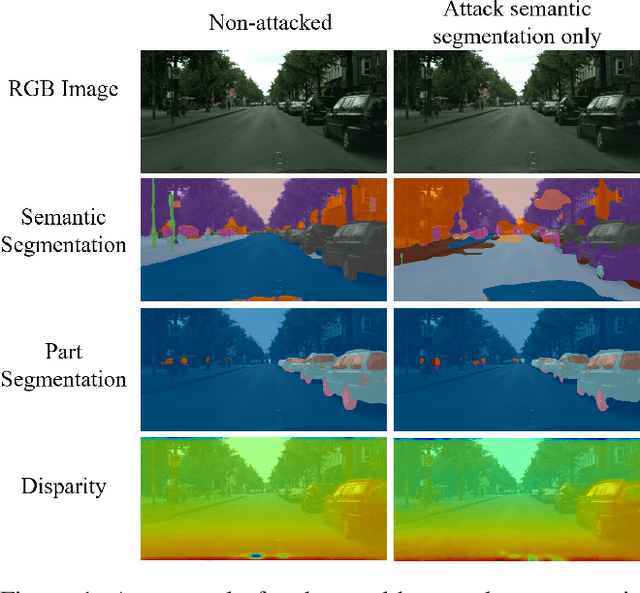
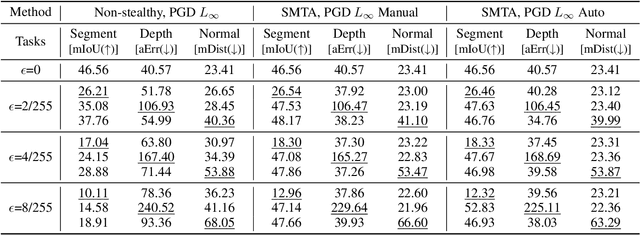
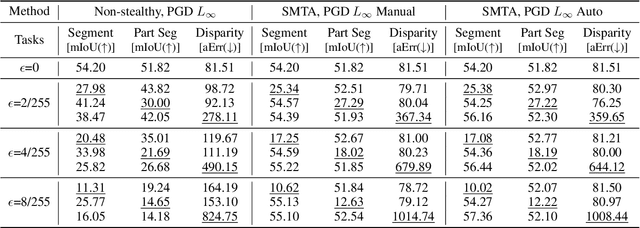
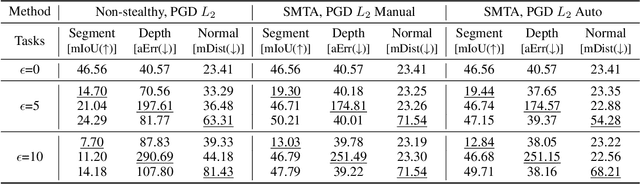
Deep Neural Networks exhibit inherent vulnerabilities to adversarial attacks, which can significantly compromise their outputs and reliability. While existing research primarily focuses on attacking single-task scenarios or indiscriminately targeting all tasks in multi-task environments, we investigate selectively targeting one task while preserving performance in others within a multi-task framework. This approach is motivated by varying security priorities among tasks in real-world applications, such as autonomous driving, where misinterpreting critical objects (e.g., signs, traffic lights) poses a greater security risk than minor depth miscalculations. Consequently, attackers may hope to target security-sensitive tasks while avoiding non-critical tasks from being compromised, thus evading being detected before compromising crucial functions. In this paper, we propose a method for the stealthy multi-task attack framework that utilizes multiple algorithms to inject imperceptible noise into the input. This novel method demonstrates remarkable efficacy in compromising the target task while simultaneously maintaining or even enhancing performance across non-targeted tasks - a criterion hitherto unexplored in the field. Additionally, we introduce an automated approach for searching the weighting factors in the loss function, further enhancing attack efficiency. Experimental results validate our framework's ability to successfully attack the target task while preserving the performance of non-targeted tasks. The automated loss function weight searching method demonstrates comparable efficacy to manual tuning, establishing a state-of-the-art multi-task attack framework.
LICM: Effective and Efficient Long Interest Chain Modeling for News Recommendation
Aug 01, 2024



Accurately recommending personalized candidate news articles to users has always been the core challenge of news recommendation system. News recommendations often require modeling of user interests to match candidate news. Recent efforts have primarily focused on extract local subgraph information, the lack of a comprehensive global news graph extraction has hindered the ability to utilize global news information collaboratively among similar users. To overcome these limitations, we propose an effective and efficient Long Interest Chain Modeling for News Recommendation(LICM), which combines neighbor interest with long-chain interest distilled from a global news click graph based on the collaborative of similar users to enhance news recommendation. For a global news graph based on the click history of all users, long chain interest generated from it can better utilize the high-dimensional information within it, enhancing the effectiveness of collaborative recommendations. We therefore design a comprehensive selection mechanism and interest encoder to obtain long-chain interest from the global graph. Finally, we use a gated network to integrate long-chain information with neighbor information to achieve the final user representation. Experiment results on real-world datasets validate the effectiveness and efficiency of our model to improve the performance of news recommendation.
EVD4UAV: An Altitude-Sensitive Benchmark to Evade Vehicle Detection in UAV
Mar 08, 2024



Vehicle detection in Unmanned Aerial Vehicle (UAV) captured images has wide applications in aerial photography and remote sensing. There are many public benchmark datasets proposed for the vehicle detection and tracking in UAV images. Recent studies show that adding an adversarial patch on objects can fool the well-trained deep neural networks based object detectors, posing security concerns to the downstream tasks. However, the current public UAV datasets might ignore the diverse altitudes, vehicle attributes, fine-grained instance-level annotation in mostly side view with blurred vehicle roof, so none of them is good to study the adversarial patch based vehicle detection attack problem. In this paper, we propose a new dataset named EVD4UAV as an altitude-sensitive benchmark to evade vehicle detection in UAV with 6,284 images and 90,886 fine-grained annotated vehicles. The EVD4UAV dataset has diverse altitudes (50m, 70m, 90m), vehicle attributes (color, type), fine-grained annotation (horizontal and rotated bounding boxes, instance-level mask) in top view with clear vehicle roof. One white-box and two black-box patch based attack methods are implemented to attack three classic deep neural networks based object detectors on EVD4UAV. The experimental results show that these representative attack methods could not achieve the robust altitude-insensitive attack performance.
DEFN: Dual-Encoder Fourier Group Harmonics Network for Three-Dimensional Macular Hole Reconstruction with Stochastic Retinal Defect Augmentation and Dynamic Weight Composition
Nov 01, 2023The spatial and quantitative parameters of macular holes are vital for diagnosis, surgical choices, and post-op monitoring. Macular hole diagnosis and treatment rely heavily on spatial and quantitative data, yet the scarcity of such data has impeded the progress of deep learning techniques for effective segmentation and real-time 3D reconstruction. To address this challenge, we assembled the world's largest macular hole dataset, Retinal OCTfor Macular Hole Enhancement (ROME-3914), and a Comprehensive Archive for Retinal Segmentation (CARS-30k), both expertly annotated. In addition, we developed an innovative 3D segmentation network, the Dual-Encoder FuGH Network (DEFN), which integrates three innovative modules: Fourier Group Harmonics (FuGH), Simplified 3D Spatial Attention (S3DSA) and Harmonic Squeeze-and-Excitation Module (HSE). These three modules synergistically filter noise, reduce computational complexity, emphasize detailed features, and enhance the network's representation ability. We also proposed a novel data augmentation method, Stochastic Retinal Defect Injection (SRDI), and a network optimization strategy DynamicWeightCompose (DWC), to further improve the performance of DEFN. Compared with 13 baselines, our DEFN shows the best performance. We also offer precise 3D retinal reconstruction and quantitative metrics, bringing revolutionary diagnostic and therapeutic decision-making tools for ophthalmologists, and is expected to completely reshape the diagnosis and treatment patterns of difficult-to-treat macular degeneration. The source code is publicly available at: https://github.com/IIPL-HangzhouDianUniversity/DEFN-Pytorch.
Defense against Adversarial Cloud Attack on Remote Sensing Salient Object Detection
Jul 05, 2023Detecting the salient objects in a remote sensing image has wide applications for the interdisciplinary research. Many existing deep learning methods have been proposed for Salient Object Detection (SOD) in remote sensing images and get remarkable results. However, the recent adversarial attack examples, generated by changing a few pixel values on the original remote sensing image, could result in a collapse for the well-trained deep learning based SOD model. Different with existing methods adding perturbation to original images, we propose to jointly tune adversarial exposure and additive perturbation for attack and constrain image close to cloudy image as Adversarial Cloud. Cloud is natural and common in remote sensing images, however, camouflaging cloud based adversarial attack and defense for remote sensing images are not well studied before. Furthermore, we design DefenseNet as a learn-able pre-processing to the adversarial cloudy images so as to preserve the performance of the deep learning based remote sensing SOD model, without tuning the already deployed deep SOD model. By considering both regular and generalized adversarial examples, the proposed DefenseNet can defend the proposed Adversarial Cloud in white-box setting and other attack methods in black-box setting. Experimental results on a synthesized benchmark from the public remote sensing SOD dataset (EORSSD) show the promising defense against adversarial cloud attacks.
Deep Transfer Learning for Intelligent Vehicle Perception: a Survey
Jun 26, 2023



Deep learning-based intelligent vehicle perception has been developing prominently in recent years to provide a reliable source for motion planning and decision making in autonomous driving. A large number of powerful deep learning-based methods can achieve excellent performance in solving various perception problems of autonomous driving. However, these deep learning methods still have several limitations, for example, the assumption that lab-training (source domain) and real-testing (target domain) data follow the same feature distribution may not be practical in the real world. There is often a dramatic domain gap between them in many real-world cases. As a solution to this challenge, deep transfer learning can handle situations excellently by transferring the knowledge from one domain to another. Deep transfer learning aims to improve task performance in a new domain by leveraging the knowledge of similar tasks learned in another domain before. Nevertheless, there are currently no survey papers on the topic of deep transfer learning for intelligent vehicle perception. To the best of our knowledge, this paper represents the first comprehensive survey on the topic of the deep transfer learning for intelligent vehicle perception. This paper discusses the domain gaps related to the differences of sensor, data, and model for the intelligent vehicle perception. The recent applications, challenges, future researches in intelligent vehicle perception are also explored.
RXFOOD: Plug-in RGB-X Fusion for Object of Interest Detection
Jun 22, 2023The emergence of different sensors (Near-Infrared, Depth, etc.) is a remedy for the limited application scenarios of traditional RGB camera. The RGB-X tasks, which rely on RGB input and another type of data input to resolve specific problems, have become a popular research topic in multimedia. A crucial part in two-branch RGB-X deep neural networks is how to fuse information across modalities. Given the tremendous information inside RGB-X networks, previous works typically apply naive fusion (e.g., average or max fusion) or only focus on the feature fusion at the same scale(s). While in this paper, we propose a novel method called RXFOOD for the fusion of features across different scales within the same modality branch and from different modality branches simultaneously in a unified attention mechanism. An Energy Exchange Module is designed for the interaction of each feature map's energy matrix, who reflects the inter-relationship of different positions and different channels inside a feature map. The RXFOOD method can be easily incorporated to any dual-branch encoder-decoder network as a plug-in module, and help the original backbone network better focus on important positions and channels for object of interest detection. Experimental results on RGB-NIR salient object detection, RGB-D salient object detection, and RGBFrequency image manipulation detection demonstrate the clear effectiveness of the proposed RXFOOD.
Loss Attitude Aware Energy Management for Signal Detection
Jan 18, 2023
This work considers a Bayesian signal processing problem where increasing the power of the probing signal may cause risks or undesired consequences. We employ a market based approach to solve energy management problems for signal detection while balancing multiple objectives. In particular, the optimal amount of resource consumption is determined so as to maximize a profit-loss based expected utility function. Next, we study the human behavior of resource consumption while taking individuals' behavioral disparity into account. Unlike rational decision makers who consume the amount of resource to maximize the expected utility function, human decision makers act to maximize their subjective utilities. We employ prospect theory to model humans' loss aversion towards a risky event. The amount of resource consumption that maximizes the humans' subjective utility is derived to characterize the actual behavior of humans. It is shown that loss attitudes may lead the human to behave quite differently from a rational decision maker.