 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
Sep 11, 2025Vision-Language-Action (VLA) models typically bridge the gap between perceptual and action spaces by pre-training a large-scale Vision-Language Model (VLM) on robotic data. While this approach greatly enhances performance, it also incurs significant training costs. In this paper, we investigate how to effectively bridge vision-language (VL) representations to action (A). We introduce VLA-Adapter, a novel paradigm designed to reduce the reliance of VLA models on large-scale VLMs and extensive pre-training. To this end, we first systematically analyze the effectiveness of various VL conditions and present key findings on which conditions are essential for bridging perception and action spaces. Based on these insights, we propose a lightweight Policy module with Bridge Attention, which autonomously injects the optimal condition into the action space. In this way, our method achieves high performance using only a 0.5B-parameter backbone, without any robotic data pre-training. Extensive experiments on both simulated and real-world robotic benchmarks demonstrate that VLA-Adapter not only achieves state-of-the-art level performance, but also offers the fast inference speed reported to date. Furthermore, thanks to the proposed advanced bridging paradigm, VLA-Adapter enables the training of a powerful VLA model in just 8 hours on a single consumer-grade GPU, greatly lowering the barrier to deploying the VLA model. Project page: https://vla-adapter.github.io/.
Toward Copyright Integrity and Verifiability via Multi-Bit Watermarking for Intelligent Transportation Systems
Feb 08, 2025Intelligent transportation systems (ITS) use advanced technologies such as artificial intelligence to significantly improve traffic flow management efficiency, and promote the intelligent development of the transportation industry. However, if the data in ITS is attacked, such as tampering or forgery, it will endanger public safety and cause social losses. Therefore, this paper proposes a watermarking that can verify the integrity of copyright in response to the needs of ITS, termed ITSmark. ITSmark focuses on functions such as extracting watermarks, verifying permission, and tracing tampered locations. The scheme uses the copyright information to build the multi-bit space and divides this space into multiple segments. These segments will be assigned to tokens. Thus, the next token is determined by its segment which contains the copyright. In this way, the obtained data contains the custom watermark. To ensure the authorization, key parameters are encrypted during copyright embedding to obtain cipher data. Only by possessing the correct cipher data and private key, can the user entirely extract the watermark. Experiments show that ITSmark surpasses baseline performances in data quality, extraction accuracy, and unforgeability. It also shows unique capabilities of permission verification and tampered location tracing, which ensures the security of extraction and the reliability of copyright verification. Furthermore, ITSmark can also customize the watermark embedding position and proportion according to user needs, making embedding more flexible.
* 11 figures, 10 tables. Accepted for publication in IEEE Transactions on Intelligent Transportation Systems (accepted versions, not the IEEE-published versions). \copyright 2025 IEEE. All rights reserved, including rights for text and data mining, and training of artificial intelligence and similar technologies. Personal use is permitted, but republication/redistribution requires IEEE permission
U-GIFT: Uncertainty-Guided Firewall for Toxic Speech in Few-Shot Scenario
Jan 01, 2025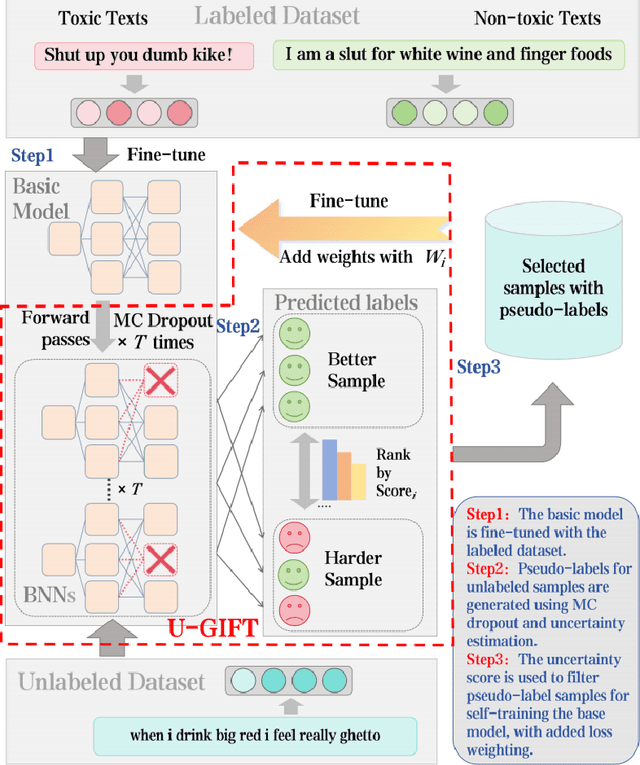
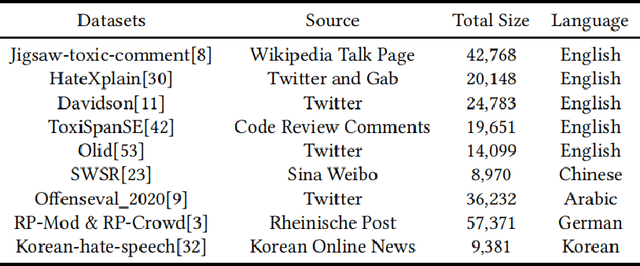
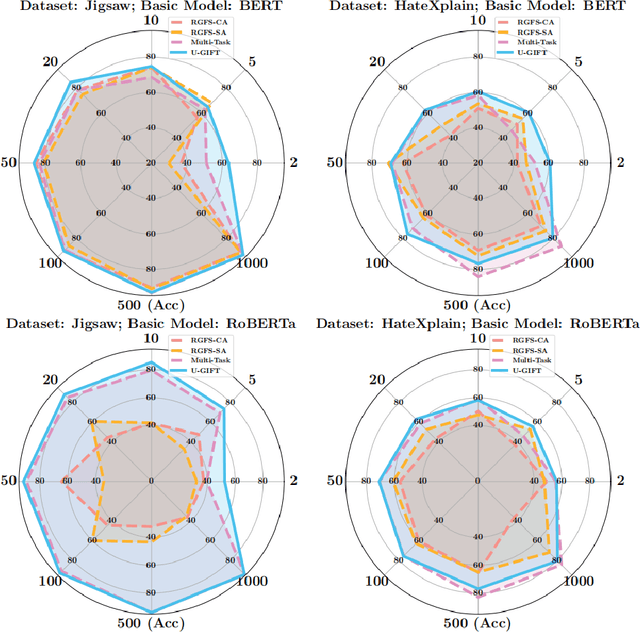
With the widespread use of social media, user-generated content has surged on online platforms. When such content includes hateful, abusive, offensive, or cyberbullying behavior, it is classified as toxic speech, posing a significant threat to the online ecosystem's integrity and safety. While manual content moderation is still prevalent, the overwhelming volume of content and the psychological strain on human moderators underscore the need for automated toxic speech detection. Previously proposed detection methods often rely on large annotated datasets; however, acquiring such datasets is both costly and challenging in practice. To address this issue, we propose an uncertainty-guided firewall for toxic speech in few-shot scenarios, U-GIFT, that utilizes self-training to enhance detection performance even when labeled data is limited. Specifically, U-GIFT combines active learning with Bayesian Neural Networks (BNNs) to automatically identify high-quality samples from unlabeled data, prioritizing the selection of pseudo-labels with higher confidence for training based on uncertainty estimates derived from model predictions. Extensive experiments demonstrate that U-GIFT significantly outperforms competitive baselines in few-shot detection scenarios. In the 5-shot setting, it achieves a 14.92\% performance improvement over the basic model. Importantly, U-GIFT is user-friendly and adaptable to various pre-trained language models (PLMs). It also exhibits robust performance in scenarios with sample imbalance and cross-domain settings, while showcasing strong generalization across various language applications. We believe that U-GIFT provides an efficient solution for few-shot toxic speech detection, offering substantial support for automated content moderation in cyberspace, thereby acting as a firewall to promote advancements in cybersecurity.
State-of-the-art Advances of Deep-learning Linguistic Steganalysis Research
Sep 03, 2024With the evolution of generative linguistic steganography techniques, conventional steganalysis falls short in robustly quantifying the alterations induced by steganography, thereby complicating detection. Consequently, the research paradigm has pivoted towards deep-learning-based linguistic steganalysis. This study offers a comprehensive review of existing contributions and evaluates prevailing developmental trajectories. Specifically, we first provided a formalized exposition of the general formulas for linguistic steganalysis, while comparing the differences between this field and the domain of text classification. Subsequently, we classified the existing work into two levels based on vector space mapping and feature extraction models, thereby comparing the research motivations, model advantages, and other details. A comparative analysis of the experiments is conducted to assess the performances. Finally, the challenges faced by this field are discussed, and several directions for future development and key issues that urgently need to be addressed are proposed.
Current Status and Trends in Image Anti-Forensics Research: A Bibliometric Analysis
Aug 21, 2024

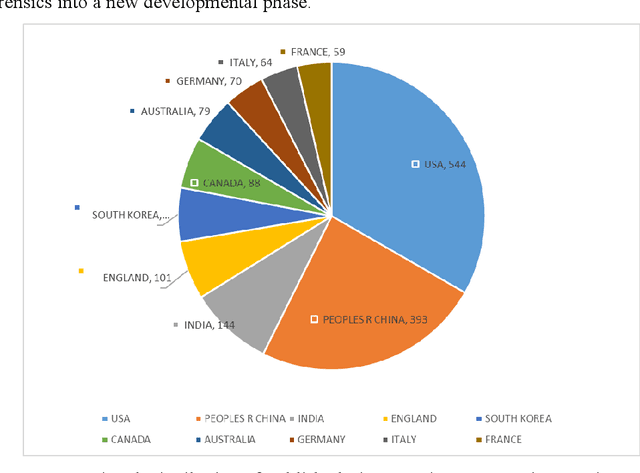

Image anti-forensics is a critical topic in the field of image privacy and security research. With the increasing ease of manipulating or generating human faces in images, the potential misuse of such forged images is a growing concern. This study aims to comprehensively review the knowledge structure and research hotspots related to image anti-forensics by analyzing publications in the Web of Science Core Collection (WoSCC) database. The bibliometric analysis conducted using VOSViewer software has revealed the research trends, major research institutions, most influential publications, top publishing venues, and most active contributors in this field. This is the first comprehensive bibliometric study summarizing research trends and developments in image anti-forensics. The information highlights recent and primary research directions, serving as a reference for future research in image anti-forensics.
LICM: Effective and Efficient Long Interest Chain Modeling for News Recommendation
Aug 01, 2024



Accurately recommending personalized candidate news articles to users has always been the core challenge of news recommendation system. News recommendations often require modeling of user interests to match candidate news. Recent efforts have primarily focused on extract local subgraph information, the lack of a comprehensive global news graph extraction has hindered the ability to utilize global news information collaboratively among similar users. To overcome these limitations, we propose an effective and efficient Long Interest Chain Modeling for News Recommendation(LICM), which combines neighbor interest with long-chain interest distilled from a global news click graph based on the collaborative of similar users to enhance news recommendation. For a global news graph based on the click history of all users, long chain interest generated from it can better utilize the high-dimensional information within it, enhancing the effectiveness of collaborative recommendations. We therefore design a comprehensive selection mechanism and interest encoder to obtain long-chain interest from the global graph. Finally, we use a gated network to integrate long-chain information with neighbor information to achieve the final user representation. Experiment results on real-world datasets validate the effectiveness and efficiency of our model to improve the performance of news recommendation.
Rethinking LLM and Linguistic Steganalysis: An Efficient Detection of Strongly Concealed Stego
Jun 06, 2024



To detect stego (steganographic text) in complex scenarios, linguistic steganalysis (LS) with various motivations has been proposed and achieved excellent performance. However, with the development of generative steganography, some stegos have strong concealment, especially after the emergence of LLMs-based steganography, the existing LS has low detection or even cannot detect them. We designed a novel LS with two modes called LSGC. In the generation mode, we created an LS-task "description" and used the generation ability of LLM to explain whether texts to be detected are stegos. On this basis, we rethought the principle of LS and LLMs, and proposed the classification mode. In this mode, LSGC deleted the LS-task "description" and changed the "causalLM" LLMs to the "sequenceClassification" architecture. The LS features can be extracted by only one pass of the model, and a linear layer with initialization weights is added to obtain the classification probability. Experiments on strongly concealed stegos show that LSGC significantly improves detection and reaches SOTA performance. Additionally, LSGC in classification mode greatly reduces training time while maintaining high performance.
An Enhanced Prompt-Based LLM Reasoning Scheme via Knowledge Graph-Integrated Collaboration
Feb 07, 2024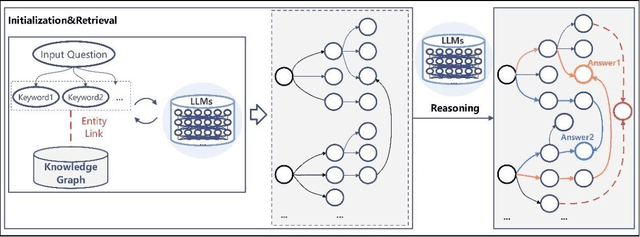
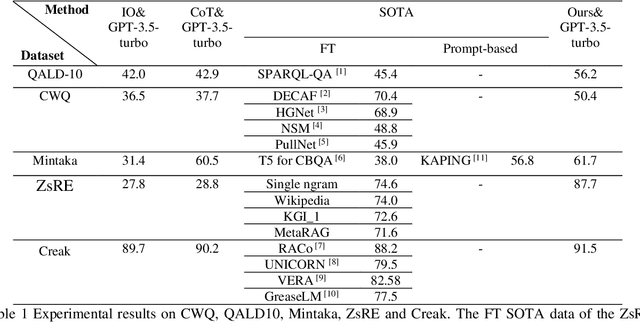
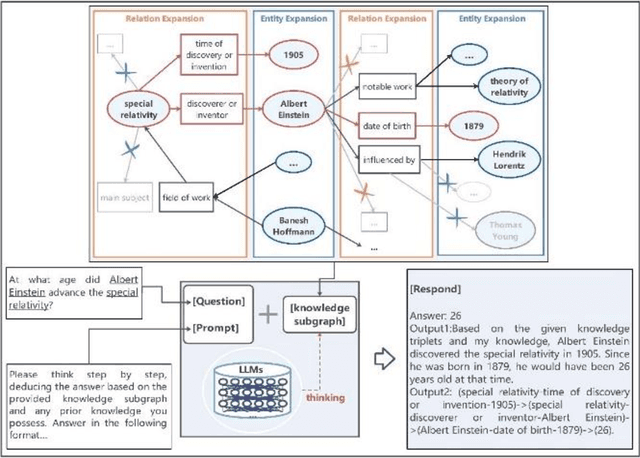

While Large Language Models (LLMs) demonstrate exceptional performance in a multitude of Natural Language Processing (NLP) tasks, they encounter challenges in practical applications, including issues with hallucinations, inadequate knowledge updating, and limited transparency in the reasoning process. To overcome these limitations, this study innovatively proposes a collaborative training-free reasoning scheme involving tight cooperation between Knowledge Graph (KG) and LLMs. This scheme first involves using LLMs to iteratively explore KG, selectively retrieving a task-relevant knowledge subgraph to support reasoning. The LLMs are then guided to further combine inherent implicit knowledge to reason on the subgraph while explicitly elucidating the reasoning process. Through such a cooperative approach, our scheme achieves more reliable knowledge-based reasoning and facilitates the tracing of the reasoning results. Experimental results show that our scheme significantly progressed across multiple datasets, notably achieving over a 10% improvement on the QALD10 dataset compared to the best baseline and the fine-tuned state-of-the-art (SOTA) work. Building on this success, this study hopes to offer a valuable reference for future research in the fusion of KG and LLMs, thereby enhancing LLMs' proficiency in solving complex issues.
LLsM: Generative Linguistic Steganography with Large Language Model
Feb 06, 2024Linguistic Steganography (LS) tasks aim to generate steganographic text (stego) based on secret information. Only authorized recipients can perceive the existence of secrets in the texts and extract them, thereby preserving privacy. However, the controllability of the stego generated by existing schemes is poor, and the stego is difficult to contain specific discourse characteristics such as style. As a result, the stego is easily detectable, compromising covert communication. To address these problems, this paper proposes LLsM, the first LS with the Large Language Model (LLM). We fine-tuned the LLaMA2 with a large-scale constructed dataset encompassing rich discourse characteristics, which enables the fine-tuned LLM to generate texts with specific discourse in a controllable manner. Then the discourse is used as guiding information and inputted into the fine-tuned LLM in the form of the Prompt together with secret. On this basis, the constructed candidate pool will be range encoded and use secret to determine the interval. The same prefix of this interval's beginning and ending is the secret embedded at this moment. Experiments show that LLsM performs superior to prevalent LS-task and related-task baselines regarding text quality, statistical analysis, discourse matching, and anti-steganalysis. In particular, LLsM's MAUVE matric surpasses some baselines by 70%-80%, and its anti-steganalysis performance is 30%-40% higher. Notably, we also present examples of longer stegos generated by LLsM, showing its potential superiority in long LS tasks.
UP4LS: User Profile Constructed by Multiple Attributes for Enhancing Linguistic Steganalysis
Nov 03, 2023Linguistic steganalysis (LS) tasks aim to effectively detect stegos generated by linguistic steganography. Existing LS methods overlook the distinctive user characteristics, leading to weak performance in social networks. The limited occurrence of stegos further complicates detection. In this paper, we propose the UP4LS, a novel framework with the User Profile for enhancing LS performance. Specifically, by delving into post content, we explore user attributes like writing habits, psychological states, and focal areas, thereby building the user profile for LS. For each attribute, we design the identified feature extraction module. The extracted features are mapped to high-dimensional user features via deep-learning networks from existing methods. Then the language model is employed to extract content features. The user and content features are integrated to optimize feature representation. During the training phase, we prioritize the distribution of stegos. Experiments demonstrate that UP4LS can significantly enhance the performance of existing methods, and an overall accuracy improvement of nearly 25%. In particular, the improvement is especially pronounced with fewer stego samples. Additionally, UP4LS also sets the stage for studies on related tasks, encouraging extensive applications on LS tasks.