 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFD-Mamba2Net: Strcture-Guided Frequency-Enhanced Dual-Stream Mamba2 Network for Coronary Artery Segmentation
Sep 10, 2025



Background: Coronary Artery Disease (CAD) is one of the leading causes of death worldwide. Invasive Coronary Angiography (ICA), regarded as the gold standard for CAD diagnosis, necessitates precise vessel segmentation and stenosis detection. However, ICA images are typically characterized by low contrast, high noise levels, and complex, fine-grained vascular structures, which pose significant challenges to the clinical adoption of existing segmentation and detection methods. Objective: This study aims to improve the accuracy of coronary artery segmentation and stenosis detection in ICA images by integrating multi-scale structural priors, state-space-based long-range dependency modeling, and frequency-domain detail enhancement strategies. Methods: We propose SFD-Mamba2Net, an end-to-end framework tailored for ICA-based vascular segmentation and stenosis detection. In the encoder, a Curvature-Aware Structural Enhancement (CASE) module is embedded to leverage multi-scale responses for highlighting slender tubular vascular structures, suppressing background interference, and directing attention toward vascular regions. In the decoder, we introduce a Progressive High-Frequency Perception (PHFP) module that employs multi-level wavelet decomposition to progressively refine high-frequency details while integrating low-frequency global structures. Results and Conclusions: SFD-Mamba2Net consistently outperformed state-of-the-art methods across eight segmentation metrics, and achieved the highest true positive rate and positive predictive value in stenosis detection.
PerPilot: Personalizing VLM-based Mobile Agents via Memory and Exploration
Aug 25, 2025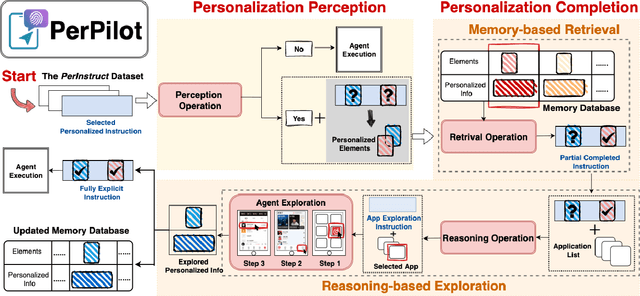

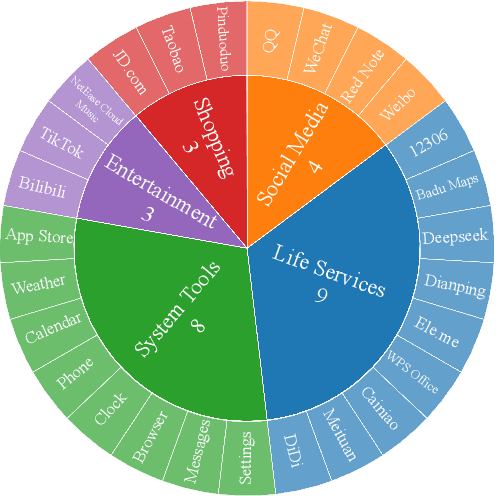
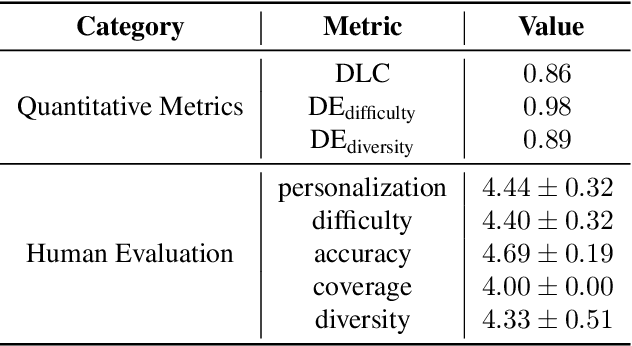
Vision language model (VLM)-based mobile agents show great potential for assisting users in performing instruction-driven tasks. However, these agents typically struggle with personalized instructions -- those containing ambiguous, user-specific context -- a challenge that has been largely overlooked in previous research. In this paper, we define personalized instructions and introduce PerInstruct, a novel human-annotated dataset covering diverse personalized instructions across various mobile scenarios. Furthermore, given the limited personalization capabilities of existing mobile agents, we propose PerPilot, a plug-and-play framework powered by large language models (LLMs) that enables mobile agents to autonomously perceive, understand, and execute personalized user instructions. PerPilot identifies personalized elements and autonomously completes instructions via two complementary approaches: memory-based retrieval and reasoning-based exploration. Experimental results demonstrate that PerPilot effectively handles personalized tasks with minimal user intervention and progressively improves its performance with continued use, underscoring the importance of personalization-aware reasoning for next-generation mobile agents. The dataset and code are available at: https://github.com/xinwang-nwpu/PerPilot
FAD-Net: Frequency-Domain Attention-Guided Diffusion Network for Coronary Artery Segmentation using Invasive Coronary Angiography
Jun 13, 2025Background: Coronary artery disease (CAD) remains one of the leading causes of mortality worldwide. Precise segmentation of coronary arteries from invasive coronary angiography (ICA) is critical for effective clinical decision-making. Objective: This study aims to propose a novel deep learning model based on frequency-domain analysis to enhance the accuracy of coronary artery segmentation and stenosis detection in ICA, thereby offering robust support for the stenosis detection and treatment of CAD. Methods: We propose the Frequency-Domain Attention-Guided Diffusion Network (FAD-Net), which integrates a frequency-domain-based attention mechanism and a cascading diffusion strategy to fully exploit frequency-domain information for improved segmentation accuracy. Specifically, FAD-Net employs a Multi-Level Self-Attention (MLSA) mechanism in the frequency domain, computing the similarity between queries and keys across high- and low-frequency components in ICAs. Furthermore, a Low-Frequency Diffusion Module (LFDM) is incorporated to decompose ICAs into low- and high-frequency components via multi-level wavelet transformation. Subsequently, it refines fine-grained arterial branches and edges by reintegrating high-frequency details via inverse fusion, enabling continuous enhancement of anatomical precision. Results and Conclusions: Extensive experiments demonstrate that FAD-Net achieves a mean Dice coefficient of 0.8717 in coronary artery segmentation, outperforming existing state-of-the-art methods. In addition, it attains a true positive rate of 0.6140 and a positive predictive value of 0.6398 in stenosis detection, underscoring its clinical applicability. These findings suggest that FAD-Net holds significant potential to assist in the accurate diagnosis and treatment planning of CAD.
SimWorld: A Unified Benchmark for Simulator-Conditioned Scene Generation via World Model
Mar 18, 2025



With the rapid advancement of autonomous driving technology, a lack of data has become a major obstacle to enhancing perception model accuracy. Researchers are now exploring controllable data generation using world models to diversify datasets. However, previous work has been limited to studying image generation quality on specific public datasets. There is still relatively little research on how to build data generation engines for real-world application scenes to achieve large-scale data generation for challenging scenes. In this paper, a simulator-conditioned scene generation engine based on world model is proposed. By constructing a simulation system consistent with real-world scenes, simulation data and labels, which serve as the conditions for data generation in the world model, for any scenes can be collected. It is a novel data generation pipeline by combining the powerful scene simulation capabilities of the simulation engine with the robust data generation capabilities of the world model. In addition, a benchmark with proportionally constructed virtual and real data, is provided for exploring the capabilities of world models in real-world scenes. Quantitative results show that these generated images significantly improve downstream perception models performance. Finally, we explored the generative performance of the world model in urban autonomous driving scenarios. All the data and code will be available at https://github.com/Li-Zn-H/SimWorld.
InsightDrive: Insight Scene Representation for End-to-End Autonomous Driving
Mar 17, 2025Directly generating planning results from raw sensors has become increasingly prevalent due to its adaptability and robustness in complex scenarios. Scene representation, as a key module in the pipeline, has traditionally relied on conventional perception, which focus on the global scene. However, in driving scenarios, human drivers typically focus only on regions that directly impact driving, which often coincide with those required for end-to-end autonomous driving. In this paper, a novel end-to-end autonomous driving method called InsightDrive is proposed, which organizes perception by language-guided scene representation. We introduce an instance-centric scene tokenizer that transforms the surrounding environment into map- and object-aware instance tokens. Scene attention language descriptions, which highlight key regions and obstacles affecting the ego vehicle's movement, are generated by a vision-language model that leverages the cognitive reasoning capabilities of foundation models. We then align scene descriptions with visual features using the vision-language model, guiding visual attention through these descriptions to give effectively scene representation. Furthermore, we employ self-attention and cross-attention mechanisms to model the ego-agents and ego-map relationships to comprehensively build the topological relationships of the scene. Finally, based on scene understanding, we jointly perform motion prediction and planning. Extensive experiments on the widely used nuScenes benchmark demonstrate that the proposed InsightDrive achieves state-of-the-art performance in end-to-end autonomous driving. The code is available at https://github.com/songruiqi/InsightDrive
Emergence of Social Norms in Large Language Model-based Agent Societies
Mar 13, 2024The emergence of social norms has attracted much interest in a wide array of disciplines, ranging from social science and cognitive science to artificial intelligence. In this paper, we propose the first generative agent architecture that empowers the emergence of social norms within a population of large language model-based agents. Our architecture, named CRSEC, consists of four modules: Creation & Representation, Spreading, Evaluation, and Compliance. Our architecture addresses several important aspects of the emergent processes all in one: (i) where social norms come from, (ii) how they are formally represented, (iii) how they spread through agents' communications and observations, (iv) how they are examined with a sanity check and synthesized in the long term, and (v) how they are incorporated into agents' planning and actions. Our experiments deployed in the Smallville sandbox game environment demonstrate the capability of our architecture to establish social norms and reduce social conflicts within large language model-based multi-agent systems. The positive outcomes of our human evaluation, conducted with 30 evaluators, further affirm the effectiveness of our approach.
GenAD: Generative End-to-End Autonomous Driving
Feb 20, 2024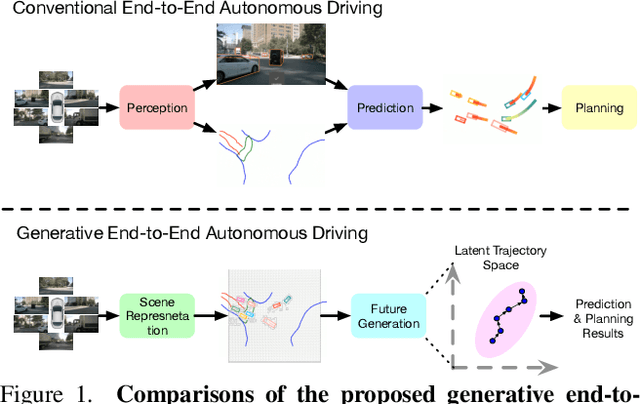



Directly producing planning results from raw sensors has been a long-desired solution for autonomous driving and has attracted increasing attention recently. Most existing end-to-end autonomous driving methods factorize this problem into perception, motion prediction, and planning. However, we argue that the conventional progressive pipeline still cannot comprehensively model the entire traffic evolution process, e.g., the future interaction between the ego car and other traffic participants and the structural trajectory prior. In this paper, we explore a new paradigm for end-to-end autonomous driving, where the key is to predict how the ego car and the surroundings evolve given past scenes. We propose GenAD, a generative framework that casts autonomous driving into a generative modeling problem. We propose an instance-centric scene tokenizer that first transforms the surrounding scenes into map-aware instance tokens. We then employ a variational autoencoder to learn the future trajectory distribution in a structural latent space for trajectory prior modeling. We further adopt a temporal model to capture the agent and ego movements in the latent space to generate more effective future trajectories. GenAD finally simultaneously performs motion prediction and planning by sampling distributions in the learned structural latent space conditioned on the instance tokens and using the learned temporal model to generate futures. Extensive experiments on the widely used nuScenes benchmark show that the proposed GenAD achieves state-of-the-art performance on vision-centric end-to-end autonomous driving with high efficiency. Code: https://github.com/wzzheng/GenAD.
LLsM: Generative Linguistic Steganography with Large Language Model
Feb 06, 2024Linguistic Steganography (LS) tasks aim to generate steganographic text (stego) based on secret information. Only authorized recipients can perceive the existence of secrets in the texts and extract them, thereby preserving privacy. However, the controllability of the stego generated by existing schemes is poor, and the stego is difficult to contain specific discourse characteristics such as style. As a result, the stego is easily detectable, compromising covert communication. To address these problems, this paper proposes LLsM, the first LS with the Large Language Model (LLM). We fine-tuned the LLaMA2 with a large-scale constructed dataset encompassing rich discourse characteristics, which enables the fine-tuned LLM to generate texts with specific discourse in a controllable manner. Then the discourse is used as guiding information and inputted into the fine-tuned LLM in the form of the Prompt together with secret. On this basis, the constructed candidate pool will be range encoded and use secret to determine the interval. The same prefix of this interval's beginning and ending is the secret embedded at this moment. Experiments show that LLsM performs superior to prevalent LS-task and related-task baselines regarding text quality, statistical analysis, discourse matching, and anti-steganalysis. In particular, LLsM's MAUVE matric surpasses some baselines by 70%-80%, and its anti-steganalysis performance is 30%-40% higher. Notably, we also present examples of longer stegos generated by LLsM, showing its potential superiority in long LS tasks.
UP4LS: User Profile Constructed by Multiple Attributes for Enhancing Linguistic Steganalysis
Nov 03, 2023Linguistic steganalysis (LS) tasks aim to effectively detect stegos generated by linguistic steganography. Existing LS methods overlook the distinctive user characteristics, leading to weak performance in social networks. The limited occurrence of stegos further complicates detection. In this paper, we propose the UP4LS, a novel framework with the User Profile for enhancing LS performance. Specifically, by delving into post content, we explore user attributes like writing habits, psychological states, and focal areas, thereby building the user profile for LS. For each attribute, we design the identified feature extraction module. The extracted features are mapped to high-dimensional user features via deep-learning networks from existing methods. Then the language model is employed to extract content features. The user and content features are integrated to optimize feature representation. During the training phase, we prioritize the distribution of stegos. Experiments demonstrate that UP4LS can significantly enhance the performance of existing methods, and an overall accuracy improvement of nearly 25%. In particular, the improvement is especially pronounced with fewer stego samples. Additionally, UP4LS also sets the stage for studies on related tasks, encouraging extensive applications on LS tasks.