 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpyglass: Directional Spectrum Sensing with Single-shot AoA Estimation and Virtual Arrays
Mar 11, 2026In this paper, we introduce Spyglass, a spectrum sensor designed to address the challenges of effective spectrum usage in dense wireless environments. Spyglass is capable of observing a frequency band and accurately estimating the Angle of Arrival (AoA) of any signal during a single transmission. This includes additional signal context such as center frequency, bandwidth, and I/Q samples. We overcome challenges such as the clutter of fleeting transmissions in common bands, the high cost of array processing for AoA estimation, and the difficulty of detecting and estimating channels for unknown signals. Our first contribution is the development of Searchlite, a protocol-agnostic signal detection and separation algorithm. We use a switched array to reduce cost and processing complexity, and we develop SSFP, a signal processing technique using Fourier transforms that is synchronized to switching boundaries. Spyglass performs multi-channel blind AoA estimation synchronized with the array. Implemented using commercially available hardware, Spyglass demonstrates a median AoA accuracy of 1.4$^\circ$ and the ability to separate simultaneous signals from multiple devices in an unconstrained RF environment, providing valuable tools for large-scale RF data collection and analysis.
Unveiling the Cognitive Compass: Theory-of-Mind-Guided Multimodal Emotion Reasoning
Feb 01, 2026Despite rapid progress in multimodal large language models (MLLMs), their capability for deep emotional understanding remains limited. We argue that genuine affective intelligence requires explicit modeling of Theory of Mind (ToM), the cognitive substrate from which emotions arise. To this end, we introduce HitEmotion, a ToM-grounded hierarchical benchmark that diagnoses capability breakpoints across increasing levels of cognitive depth. Second, we propose a ToM-guided reasoning chain that tracks mental states and calibrates cross-modal evidence to achieve faithful emotional reasoning. We further introduce TMPO, a reinforcement learning method that uses intermediate mental states as process-level supervision to guide and strengthen model reasoning. Extensive experiments show that HitEmotion exposes deep emotional reasoning deficits in state-of-the-art models, especially on cognitively demanding tasks. In evaluation, the ToM-guided reasoning chain and TMPO improve end-task accuracy and yield more faithful, more coherent rationales. In conclusion, our work provides the research community with a practical toolkit for evaluating and enhancing the cognition-based emotional understanding capabilities of MLLMs. Our dataset and code are available at: https://HitEmotion.github.io/.
KnowVal: A Knowledge-Augmented and Value-Guided Autonomous Driving System
Dec 23, 2025Visual-language reasoning, driving knowledge, and value alignment are essential for advanced autonomous driving systems. However, existing approaches largely rely on data-driven learning, making it difficult to capture the complex logic underlying decision-making through imitation or limited reinforcement rewards. To address this, we propose KnowVal, a new autonomous driving system that enables visual-language reasoning through the synergistic integration of open-world perception and knowledge retrieval. Specifically, we construct a comprehensive driving knowledge graph that encodes traffic laws, defensive driving principles, and ethical norms, complemented by an efficient LLM-based retrieval mechanism tailored for driving scenarios. Furthermore, we develop a human-preference dataset and train a Value Model to guide interpretable, value-aligned trajectory assessment. Experimental results show that our method substantially improves planning performance while remaining compatible with existing architectures. Notably, KnowVal achieves the lowest collision rate on nuScenes and state-of-the-art results on Bench2Drive.
A New Federated Learning Framework Against Gradient Inversion Attacks
Dec 10, 2024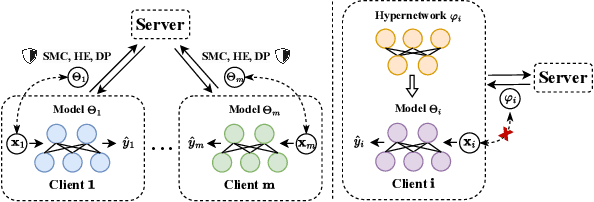
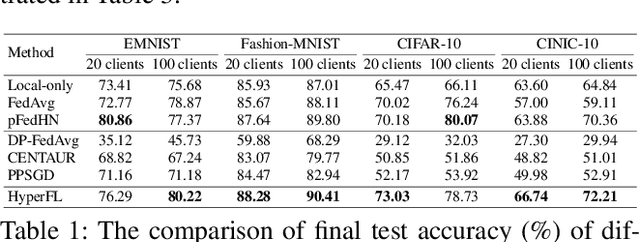
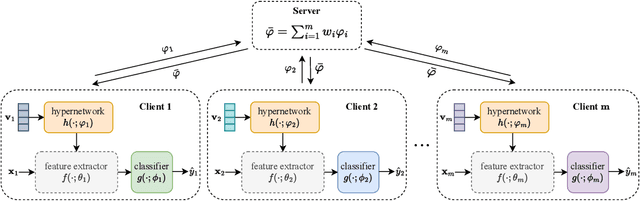
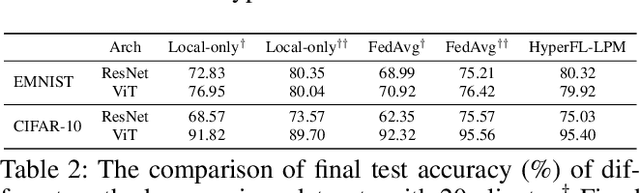
Federated Learning (FL) aims to protect data privacy by enabling clients to collectively train machine learning models without sharing their raw data. However, recent studies demonstrate that information exchanged during FL is subject to Gradient Inversion Attacks (GIA) and, consequently, a variety of privacy-preserving methods have been integrated into FL to thwart such attacks, such as Secure Multi-party Computing (SMC), Homomorphic Encryption (HE), and Differential Privacy (DP). Despite their ability to protect data privacy, these approaches inherently involve substantial privacy-utility trade-offs. By revisiting the key to privacy exposure in FL under GIA, which lies in the frequent sharing of model gradients that contain private data, we take a new perspective by designing a novel privacy preserve FL framework that effectively ``breaks the direct connection'' between the shared parameters and the local private data to defend against GIA. Specifically, we propose a Hypernetwork Federated Learning (HyperFL) framework that utilizes hypernetworks to generate the parameters of the local model and only the hypernetwork parameters are uploaded to the server for aggregation. Theoretical analyses demonstrate the convergence rate of the proposed HyperFL, while extensive experimental results show the privacy-preserving capability and comparable performance of HyperFL. Code is available at https://github.com/Pengxin-Guo/HyperFL.
DEFN: Dual-Encoder Fourier Group Harmonics Network for Three-Dimensional Macular Hole Reconstruction with Stochastic Retinal Defect Augmentation and Dynamic Weight Composition
Nov 01, 2023The spatial and quantitative parameters of macular holes are vital for diagnosis, surgical choices, and post-op monitoring. Macular hole diagnosis and treatment rely heavily on spatial and quantitative data, yet the scarcity of such data has impeded the progress of deep learning techniques for effective segmentation and real-time 3D reconstruction. To address this challenge, we assembled the world's largest macular hole dataset, Retinal OCTfor Macular Hole Enhancement (ROME-3914), and a Comprehensive Archive for Retinal Segmentation (CARS-30k), both expertly annotated. In addition, we developed an innovative 3D segmentation network, the Dual-Encoder FuGH Network (DEFN), which integrates three innovative modules: Fourier Group Harmonics (FuGH), Simplified 3D Spatial Attention (S3DSA) and Harmonic Squeeze-and-Excitation Module (HSE). These three modules synergistically filter noise, reduce computational complexity, emphasize detailed features, and enhance the network's representation ability. We also proposed a novel data augmentation method, Stochastic Retinal Defect Injection (SRDI), and a network optimization strategy DynamicWeightCompose (DWC), to further improve the performance of DEFN. Compared with 13 baselines, our DEFN shows the best performance. We also offer precise 3D retinal reconstruction and quantitative metrics, bringing revolutionary diagnostic and therapeutic decision-making tools for ophthalmologists, and is expected to completely reshape the diagnosis and treatment patterns of difficult-to-treat macular degeneration. The source code is publicly available at: https://github.com/IIPL-HangzhouDianUniversity/DEFN-Pytorch.
Branch Ranking for Efficient Mixed-Integer Programming via Offline Ranking-based Policy Learning
Jul 26, 2022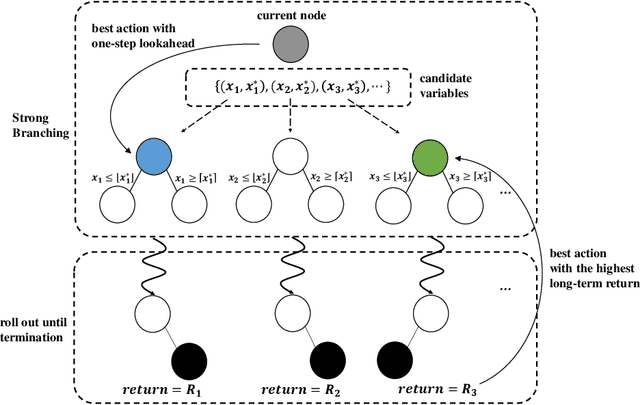
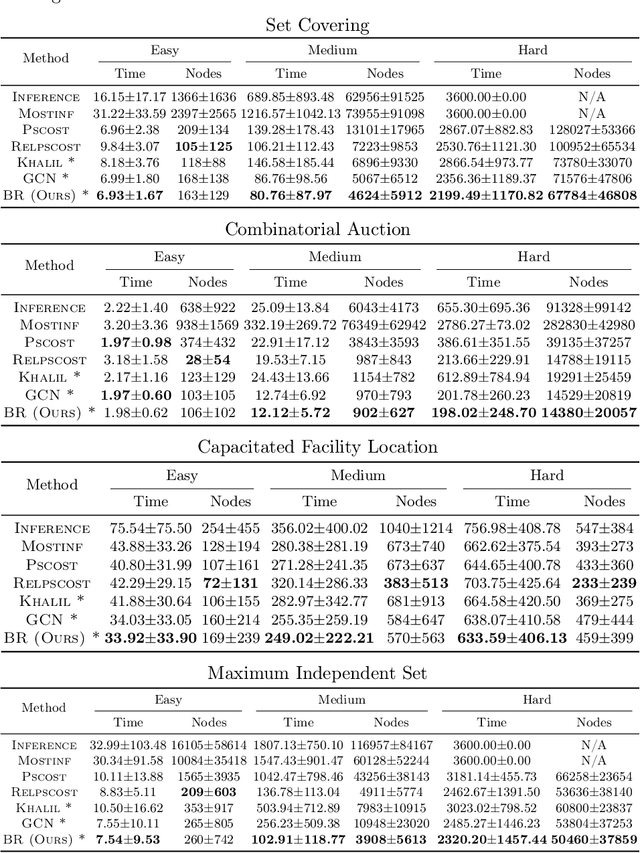
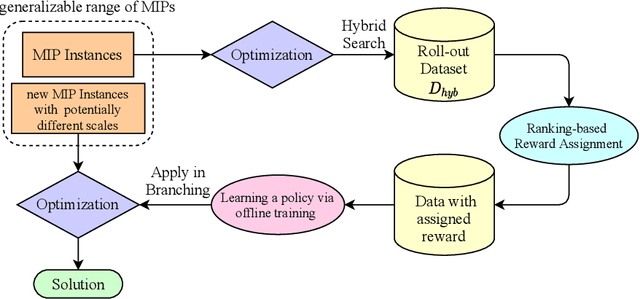

Deriving a good variable selection strategy in branch-and-bound is essential for the efficiency of modern mixed-integer programming (MIP) solvers. With MIP branching data collected during the previous solution process, learning to branch methods have recently become superior over heuristics. As branch-and-bound is naturally a sequential decision making task, one should learn to optimize the utility of the whole MIP solving process instead of being myopic on each step. In this work, we formulate learning to branch as an offline reinforcement learning (RL) problem, and propose a long-sighted hybrid search scheme to construct the offline MIP dataset, which values the long-term utilities of branching decisions. During the policy training phase, we deploy a ranking-based reward assignment scheme to distinguish the promising samples from the long-term or short-term view, and train the branching model named Branch Ranking via offline policy learning. Experiments on synthetic MIP benchmarks and real-world tasks demonstrate that Branch Rankink is more efficient and robust, and can better generalize to large scales of MIP instances compared to the widely used heuristics and state-of-the-art learning-based branching models.