 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaDy: Lagrangian-Dynamic Informed Network for Skeleton-based Action Segmentation via Spatial-Temporal Modulation
Mar 25, 2026Skeleton-based Temporal Action Segmentation (STAS) aims to densely parse untrimmed skeletal sequences into frame-level action categories. However, existing methods, while proficient at capturing spatio-temporal kinematics, neglect the underlying physical dynamics that govern human motion. This oversight limits inter-class discriminability between actions with similar kinematics but distinct dynamic intents, and hinders precise boundary localization where dynamic force profiles shift. To address these, we propose the Lagrangian-Dynamic Informed Network (LaDy), a framework integrating principles of Lagrangian dynamics into the segmentation process. Specifically, LaDy first computes generalized coordinates from joint positions and then estimates Lagrangian terms under physical constraints to explicitly synthesize the generalized forces. To further ensure physical coherence, our Energy Consistency Loss enforces the work-energy theorem, aligning kinetic energy change with the work done by the net force. The learned dynamics then drive a Spatio-Temporal Modulation module: Spatially, generalized forces are fused with spatial representations to provide more discriminative semantics. Temporally, salient dynamic signals are constructed for temporal gating, thereby significantly enhancing boundary awareness. Experiments on challenging datasets show that LaDy achieves state-of-the-art performance, validating the integration of physical dynamics for action segmentation. Code is available at https://github.com/HaoyuJi/LaDy.
Spectral Scalpel: Amplifying Adjacent Action Discrepancy via Frequency-Selective Filtering for Skeleton-Based Action Segmentation
Mar 25, 2026Skeleton-based Temporal Action Segmentation (STAS) seeks to densely segment and classify diverse actions within long, untrimmed skeletal motion sequences. However, existing STAS methodologies face challenges of limited inter-class discriminability and blurred segmentation boundaries, primarily due to insufficient distinction of spatio-temporal patterns between adjacent actions. To address these limitations, we propose Spectral Scalpel, a frequency-selective filtering framework aimed at suppressing shared frequency components between adjacent distinct actions while amplifying their action-specific frequencies, thereby enhancing inter-action discrepancies and sharpening transition boundaries. Specifically, Spectral Scalpel employs adaptive multi-scale spectral filters as scalpels to edit frequency spectra, coupled with a discrepancy loss between adjacent actions serving as the surgical objective. This design amplifies representational disparities between neighboring actions, effectively mitigating boundary localization ambiguities and inter-class confusion. Furthermore, complementing long-term temporal modeling, we introduce a frequency-aware channel mixer to strengthen channel evolution by aggregating spectra across channels. This work presents a novel paradigm for STAS that extends conventional spatio-temporal modeling by incorporating frequency-domain analysis. Extensive experiments on five public datasets demonstrate that Spectral Scalpel achieves state-of-the-art performance. Code is available at https://github.com/HaoyuJi/SpecScalpel.
OpenVLN: Open-world aerial Vision-Language Navigation
Nov 09, 2025Vision-language models (VLMs) have been widely-applied in ground-based vision-language navigation (VLN). However, the vast complexity of outdoor aerial environments compounds data acquisition challenges and imposes long-horizon trajectory planning requirements on Unmanned Aerial Vehicles (UAVs), introducing novel complexities for aerial VLN. To address these challenges, we propose a data-efficient Open-world aerial Vision-Language Navigation (i.e., OpenVLN) framework, which could execute language-guided flight with limited data constraints and enhance long-horizon trajectory planning capabilities in complex aerial environments. Specifically, we reconfigure a reinforcement learning framework to optimize the VLM for UAV navigation tasks, which can efficiently fine-tune VLM by using rule-based policies under limited training data. Concurrently, we introduce a long-horizon planner for trajectory synthesis that dynamically generates precise UAV actions via value-based rewards. To the end, we conduct sufficient navigation experiments on the TravelUAV benchmark with dataset scaling across diverse reward settings. Our method demonstrates consistent performance gains of up to 4.34% in Success Rate, 6.19% in Oracle Success Rate, and 4.07% in Success weighted by Path Length over baseline methods, validating its deployment efficacy for long-horizon UAV navigation in complex aerial environments.
Text-Derived Relational Graph-Enhanced Network for Skeleton-Based Action Segmentation
Mar 19, 2025Skeleton-based Temporal Action Segmentation (STAS) aims to segment and recognize various actions from long, untrimmed sequences of human skeletal movements. Current STAS methods typically employ spatio-temporal modeling to establish dependencies among joints as well as frames, and utilize one-hot encoding with cross-entropy loss for frame-wise classification supervision. However, these methods overlook the intrinsic correlations among joints and actions within skeletal features, leading to a limited understanding of human movements. To address this, we propose a Text-Derived Relational Graph-Enhanced Network (TRG-Net) that leverages prior graphs generated by Large Language Models (LLM) to enhance both modeling and supervision. For modeling, the Dynamic Spatio-Temporal Fusion Modeling (DSFM) method incorporates Text-Derived Joint Graphs (TJG) with channel- and frame-level dynamic adaptation to effectively model spatial relations, while integrating spatio-temporal core features during temporal modeling. For supervision, the Absolute-Relative Inter-Class Supervision (ARIS) method employs contrastive learning between action features and text embeddings to regularize the absolute class distributions, and utilizes Text-Derived Action Graphs (TAG) to capture the relative inter-class relationships among action features. Additionally, we propose a Spatial-Aware Enhancement Processing (SAEP) method, which incorporates random joint occlusion and axial rotation to enhance spatial generalization. Performance evaluations on four public datasets demonstrate that TRG-Net achieves state-of-the-art results.
A New Federated Learning Framework Against Gradient Inversion Attacks
Dec 10, 2024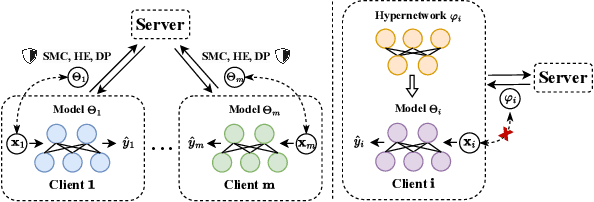
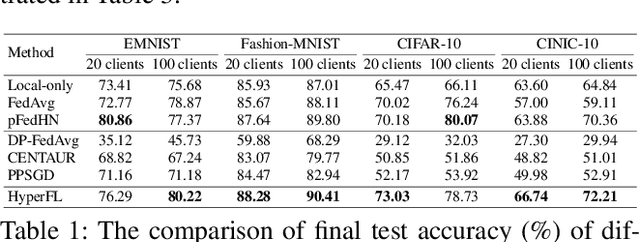
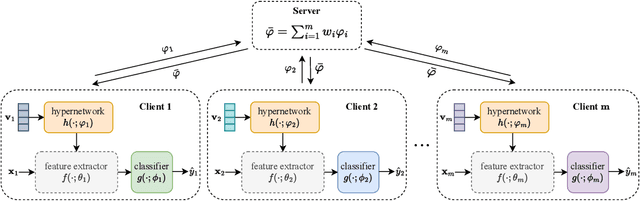
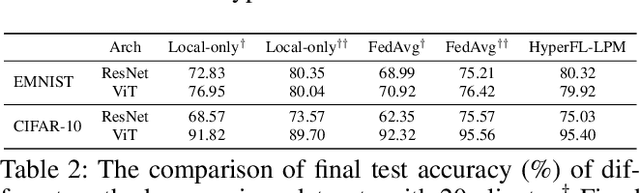
Federated Learning (FL) aims to protect data privacy by enabling clients to collectively train machine learning models without sharing their raw data. However, recent studies demonstrate that information exchanged during FL is subject to Gradient Inversion Attacks (GIA) and, consequently, a variety of privacy-preserving methods have been integrated into FL to thwart such attacks, such as Secure Multi-party Computing (SMC), Homomorphic Encryption (HE), and Differential Privacy (DP). Despite their ability to protect data privacy, these approaches inherently involve substantial privacy-utility trade-offs. By revisiting the key to privacy exposure in FL under GIA, which lies in the frequent sharing of model gradients that contain private data, we take a new perspective by designing a novel privacy preserve FL framework that effectively ``breaks the direct connection'' between the shared parameters and the local private data to defend against GIA. Specifically, we propose a Hypernetwork Federated Learning (HyperFL) framework that utilizes hypernetworks to generate the parameters of the local model and only the hypernetwork parameters are uploaded to the server for aggregation. Theoretical analyses demonstrate the convergence rate of the proposed HyperFL, while extensive experimental results show the privacy-preserving capability and comparable performance of HyperFL. Code is available at https://github.com/Pengxin-Guo/HyperFL.
Language-Assisted Human Part Motion Learning for Skeleton-Based Temporal Action Segmentation
Oct 08, 2024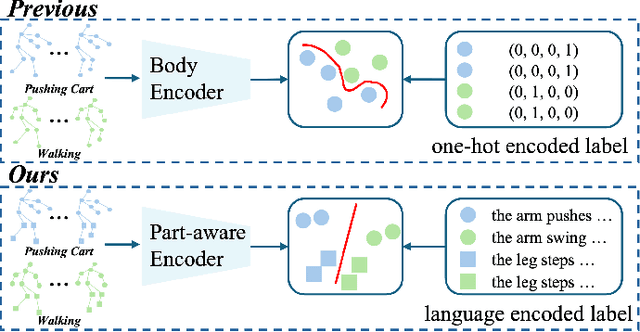
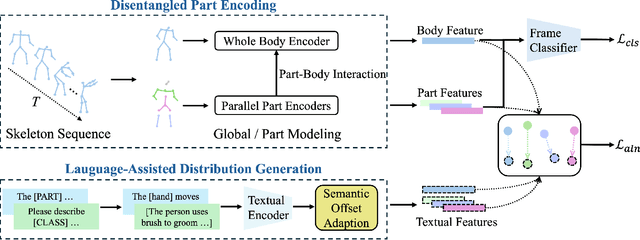
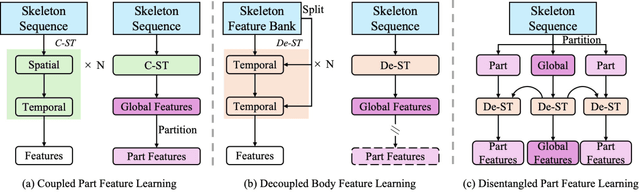
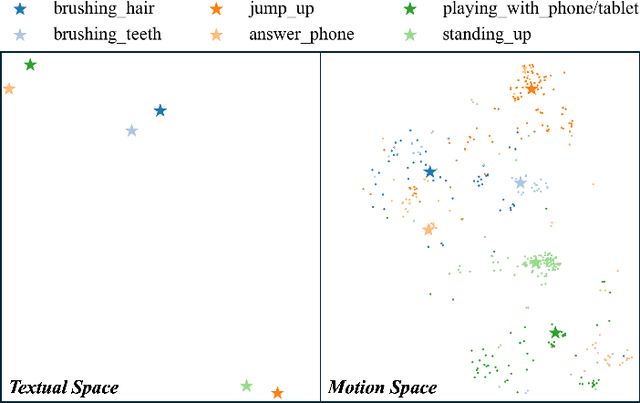
Skeleton-based Temporal Action Segmentation involves the dense action classification of variable-length skeleton sequences. Current approaches primarily apply graph-based networks to extract framewise, whole-body-level motion representations, and use one-hot encoded labels for model optimization. However, whole-body motion representations do not capture fine-grained part-level motion representations and the one-hot encoded labels neglect the intrinsic semantic relationships within the language-based action definitions. To address these limitations, we propose a novel method named Language-assisted Human Part Motion Representation Learning (LPL), which contains a Disentangled Part Motion Encoder (DPE) to extract dual-level (i.e., part and whole-body) motion representations and a Language-assisted Distribution Alignment (LDA) strategy for optimizing spatial relations within representations. Specifically, after part-aware skeleton encoding via DPE, LDA generates dual-level action descriptions to construct a textual embedding space with the help of a large-scale language model. Then, LDA motivates the alignment of the embedding space between text descriptions and motions. This alignment allows LDA not only to enhance intra-class compactness but also to transfer the language-encoded semantic correlations among actions to skeleton-based motion learning. Moreover, we propose a simple yet efficient Semantic Offset Adapter to smooth the cross-domain misalignment. Our experiments indicate that LPL achieves state-of-the-art performance across various datasets (e.g., +4.4\% Accuracy, +5.6\% F1 on the PKU-MMD dataset). Moreover, LDA is compatible with existing methods and improves their performance (e.g., +4.8\% Accuracy, +4.3\% F1 on the LARa dataset) without additional inference costs.
Attribute-Text Guided Forgetting Compensation for Lifelong Person Re-Identification
Sep 30, 2024Lifelong person re-identification (LReID) aims to continuously learn from non-stationary data to match individuals in different environments. Each task is affected by variations in illumination and person-related information (such as pose and clothing), leading to task-wise domain gaps. Current LReID methods focus on task-specific knowledge and ignore intrinsic task-shared representations within domain gaps, limiting model performance. Bridging task-wise domain gaps is crucial for improving anti-forgetting and generalization capabilities, especially when accessing limited old classes during training. To address these issues, we propose a novel attribute-text guided forgetting compensation (ATFC) model, which explores text-driven global representations of identity-related information and attribute-related local representations of identity-free information for LReID. Due to the lack of paired text-image data, we design an attribute-text generator (ATG) to dynamically generate a text descriptor for each instance. We then introduce a text-guided aggregation network (TGA) to explore robust text-driven global representations for each identity and knowledge transfer. Furthermore, we propose an attribute compensation network (ACN) to investigate attribute-related local representations, which distinguish similar identities and bridge domain gaps. Finally, we develop an attribute anti-forgetting (AF) loss and knowledge transfer (KT) loss to minimize domain gaps and achieve knowledge transfer, improving model performance. Extensive experiments demonstrate that our ATFC method achieves superior performance, outperforming existing LReID methods by over 9.0$\%$/7.4$\%$ in average mAP/R-1 on the seen dataset.
Exploring Self- and Cross-Triplet Correlations for Human-Object Interaction Detection
Jan 11, 2024



Human-Object Interaction (HOI) detection plays a vital role in scene understanding, which aims to predict the HOI triplet in the form of <human, object, action>. Existing methods mainly extract multi-modal features (e.g., appearance, object semantics, human pose) and then fuse them together to directly predict HOI triplets. However, most of these methods focus on seeking for self-triplet aggregation, but ignore the potential cross-triplet dependencies, resulting in ambiguity of action prediction. In this work, we propose to explore Self- and Cross-Triplet Correlations (SCTC) for HOI detection. Specifically, we regard each triplet proposal as a graph where Human, Object represent nodes and Action indicates edge, to aggregate self-triplet correlation. Also, we try to explore cross-triplet dependencies by jointly considering instance-level, semantic-level, and layout-level relations. Besides, we leverage the CLIP model to assist our SCTC obtain interaction-aware feature by knowledge distillation, which provides useful action clues for HOI detection. Extensive experiments on HICO-DET and V-COCO datasets verify the effectiveness of our proposed SCTC.
CountingMOT: Joint Counting, Detection and Re-Identification for Multiple Object Tracking
Dec 12, 2022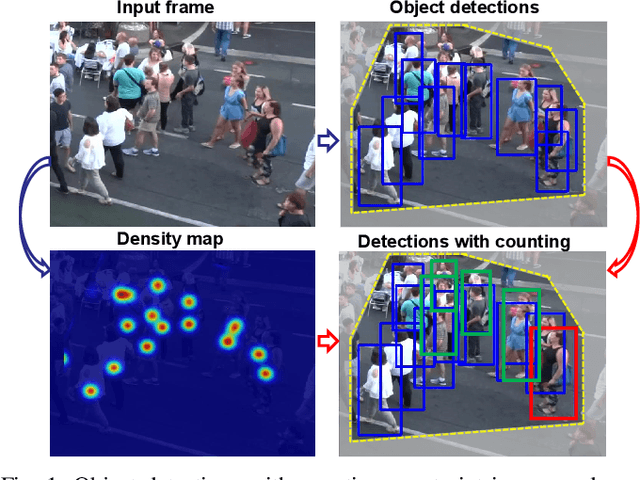
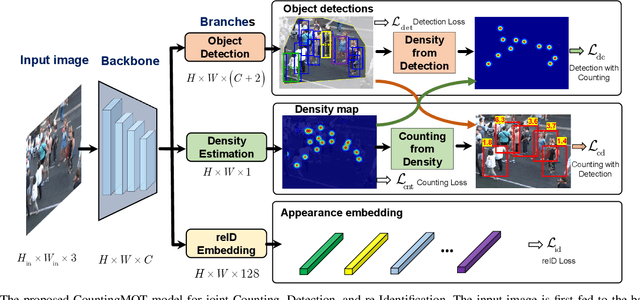


The recent trend in multiple object tracking (MOT) is jointly solving detection and tracking, where object detection and appearance feature (or motion) are learned simultaneously. Despite competitive performance, in crowded scenes, joint detection and tracking usually fail to find accurate object associations due to missed or false detections. In this paper, we jointly model counting, detection and re-identification in an end-to-end framework, named CountingMOT, tailored for crowded scenes. By imposing mutual object-count constraints between detection and counting, the CountingMOT tries to find a balance between object detection and crowd density map estimation, which can help it to recover missed detections or reject false detections. Our approach is an attempt to bridge the gap of object detection, counting, and re-Identification. This is in contrast to prior MOT methods that either ignore the crowd density and thus are prone to failure in crowded scenes, or depend on local correlations to build a graphical relationship for matching targets. The proposed MOT tracker can perform online and real-time tracking, and achieves the state-of-the-art results on public benchmarks MOT16 (MOTA of 77.6), MOT17 (MOTA of 78.0%) and MOT20 (MOTA of 70.2%).
Tracking-by-Counting: Using Network Flows on Crowd Density Maps for Tracking Multiple Targets
Jul 18, 2020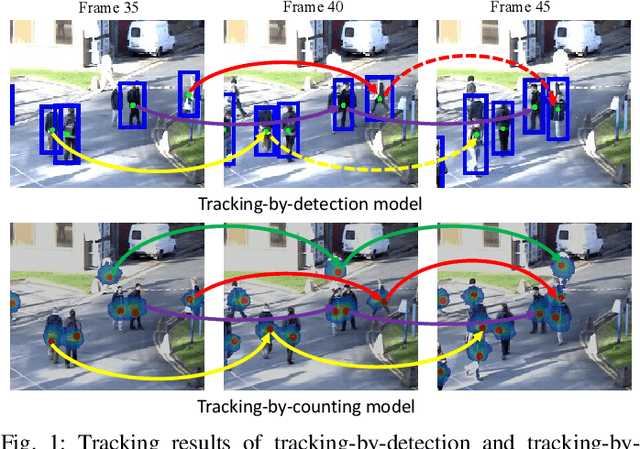
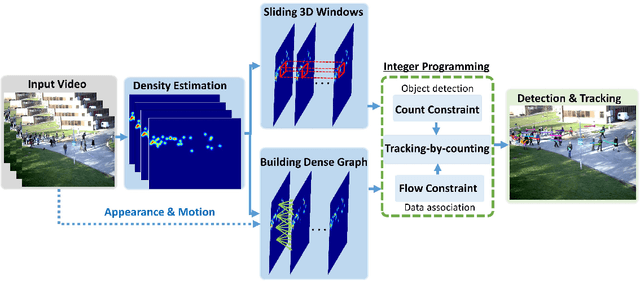
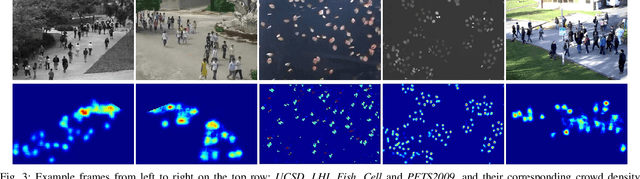

State-of-the-art multi-object tracking~(MOT) methods follow the tracking-by-detection paradigm, where object trajectories are obtained by associating per-frame outputs of object detectors. In crowded scenes, however, detectors often fail to obtain accurate detections due to heavy occlusions and high crowd density. In this paper, we propose a new MOT paradigm, tracking-by-counting, tailored for crowded scenes. Using crowd density maps, we jointly model detection, counting, and tracking of multiple targets as a network flow program, which simultaneously finds the global optimal detections and trajectories of multiple targets over the whole video. This is in contrast to prior MOT methods that either ignore the crowd density and thus are prone to errors in crowded scenes, or rely on a suboptimal two-step process using heuristic density-aware point-tracks for matching targets.Our approach yields promising results on public benchmarks of various domains including people tracking, cell tracking, and fish tracking.