 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHERMES: A Unified Open-Source Framework for Realtime Multimodal Physiological Sensing, Edge AI, and Intervention in Closed-Loop Smart Healthcare Applications
Jan 18, 2026Intelligent assistive technologies are increasingly recognized as critical daily-use enablers for people with disabilities and age-related functional decline. Longitudinal studies, curation of quality datasets, live monitoring in activities of daily living, and intelligent intervention devices, share the largely unsolved need in reliable high-throughput multimodal sensing and processing. Streaming large heterogeneous data from distributed sensors, historically closed-source environments, and limited prior works on realtime closed-loop AI methodologies, inhibit such applications. To accelerate the emergence of clinical deployments, we deliver HERMES - an open-source high-performance Python framework for continuous multimodal sensing and AI processing at the edge. It enables synchronized data collection, and realtime streaming inference with user PyTorch models, on commodity computing devices. HERMES is applicable to fixed-lab and free-living environments, of distributed commercial and custom sensors. It is the first work to offer a holistic methodology that bridges cross-disciplinary gaps in real-world implementation strategies, and guides downstream AI model development. Its application on the closed-loop intelligent prosthesis use case illustrates the process of suitable AI model development from the generated constraints and trade-offs. Validation on the use case, with 4 synchronized hosts cooperatively capturing 18 wearable and off-body modalities, demonstrates performance and relevance of HERMES to the trajectory of the intelligent healthcare domain.
CARE-PD: A Multi-Site Anonymized Clinical Dataset for Parkinson's Disease Gait Assessment
Oct 05, 2025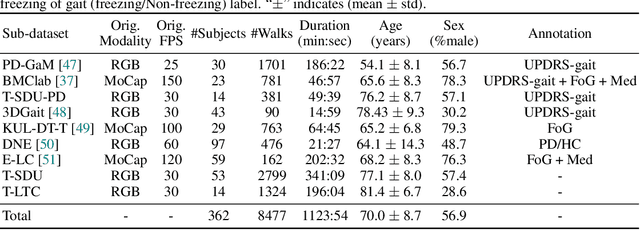
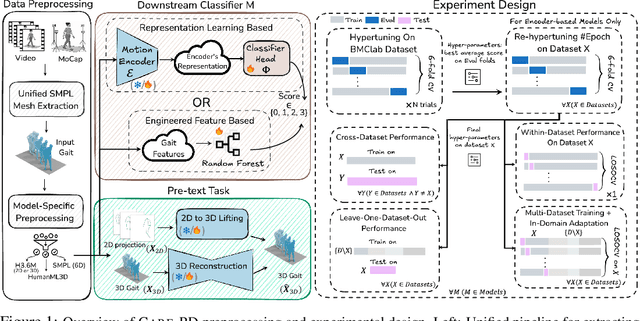
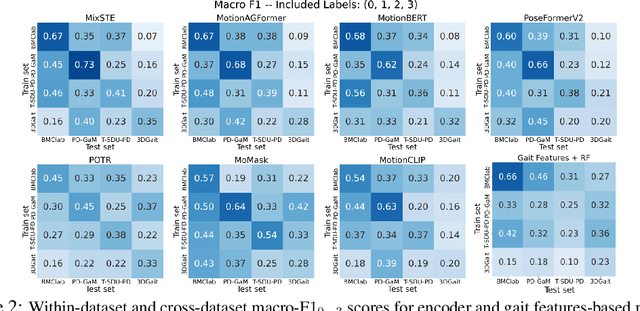
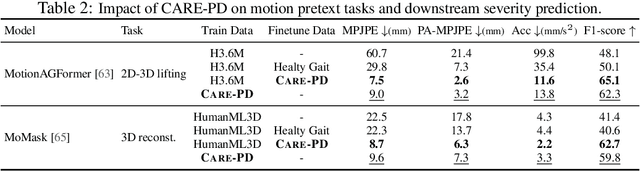
Objective gait assessment in Parkinson's Disease (PD) is limited by the absence of large, diverse, and clinically annotated motion datasets. We introduce CARE-PD, the largest publicly available archive of 3D mesh gait data for PD, and the first multi-site collection spanning 9 cohorts from 8 clinical centers. All recordings (RGB video or motion capture) are converted into anonymized SMPL meshes via a harmonized preprocessing pipeline. CARE-PD supports two key benchmarks: supervised clinical score prediction (estimating Unified Parkinson's Disease Rating Scale, UPDRS, gait scores) and unsupervised motion pretext tasks (2D-to-3D keypoint lifting and full-body 3D reconstruction). Clinical prediction is evaluated under four generalization protocols: within-dataset, cross-dataset, leave-one-dataset-out, and multi-dataset in-domain adaptation. To assess clinical relevance, we compare state-of-the-art motion encoders with a traditional gait-feature baseline, finding that encoders consistently outperform handcrafted features. Pretraining on CARE-PD reduces MPJPE (from 60.8mm to 7.5mm) and boosts PD severity macro-F1 by 17 percentage points, underscoring the value of clinically curated, diverse training data. CARE-PD and all benchmark code are released for non-commercial research at https://neurips2025.care-pd.ca/.
GAITGen: Disentangled Motion-Pathology Impaired Gait Generative Model -- Bringing Motion Generation to the Clinical Domain
Mar 28, 2025Gait analysis is crucial for the diagnosis and monitoring of movement disorders like Parkinson's Disease. While computer vision models have shown potential for objectively evaluating parkinsonian gait, their effectiveness is limited by scarce clinical datasets and the challenge of collecting large and well-labelled data, impacting model accuracy and risk of bias. To address these gaps, we propose GAITGen, a novel framework that generates realistic gait sequences conditioned on specified pathology severity levels. GAITGen employs a Conditional Residual Vector Quantized Variational Autoencoder to learn disentangled representations of motion dynamics and pathology-specific factors, coupled with Mask and Residual Transformers for conditioned sequence generation. GAITGen generates realistic, diverse gait sequences across severity levels, enriching datasets and enabling large-scale model training in parkinsonian gait analysis. Experiments on our new PD-GaM (real) dataset demonstrate that GAITGen outperforms adapted state-of-the-art models in both reconstruction fidelity and generation quality, accurately capturing critical pathology-specific gait features. A clinical user study confirms the realism and clinical relevance of our generated sequences. Moreover, incorporating GAITGen-generated data into downstream tasks improves parkinsonian gait severity estimation, highlighting its potential for advancing clinical gait analysis.
Language-Assisted Human Part Motion Learning for Skeleton-Based Temporal Action Segmentation
Oct 08, 2024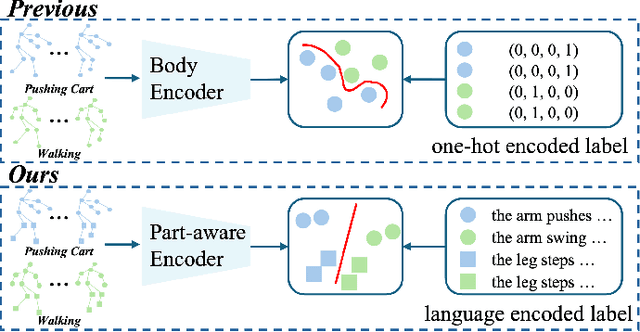
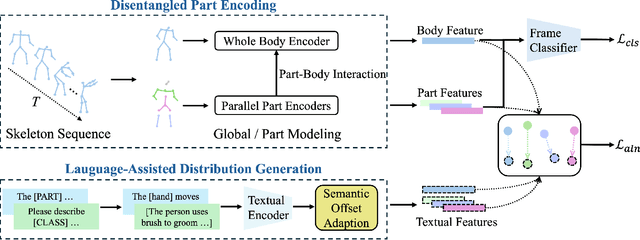
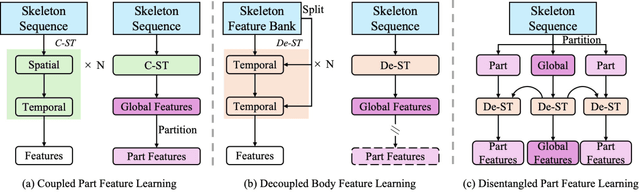
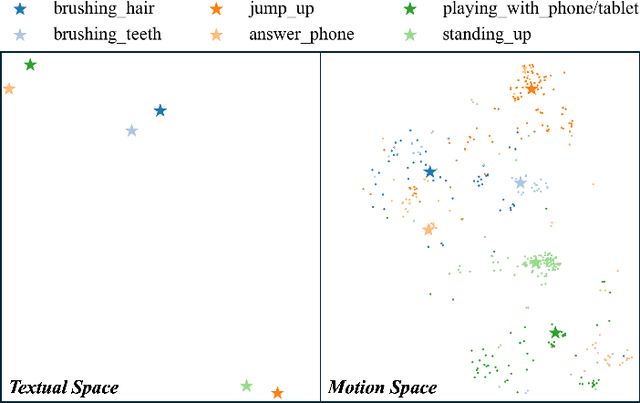
Skeleton-based Temporal Action Segmentation involves the dense action classification of variable-length skeleton sequences. Current approaches primarily apply graph-based networks to extract framewise, whole-body-level motion representations, and use one-hot encoded labels for model optimization. However, whole-body motion representations do not capture fine-grained part-level motion representations and the one-hot encoded labels neglect the intrinsic semantic relationships within the language-based action definitions. To address these limitations, we propose a novel method named Language-assisted Human Part Motion Representation Learning (LPL), which contains a Disentangled Part Motion Encoder (DPE) to extract dual-level (i.e., part and whole-body) motion representations and a Language-assisted Distribution Alignment (LDA) strategy for optimizing spatial relations within representations. Specifically, after part-aware skeleton encoding via DPE, LDA generates dual-level action descriptions to construct a textual embedding space with the help of a large-scale language model. Then, LDA motivates the alignment of the embedding space between text descriptions and motions. This alignment allows LDA not only to enhance intra-class compactness but also to transfer the language-encoded semantic correlations among actions to skeleton-based motion learning. Moreover, we propose a simple yet efficient Semantic Offset Adapter to smooth the cross-domain misalignment. Our experiments indicate that LPL achieves state-of-the-art performance across various datasets (e.g., +4.4\% Accuracy, +5.6\% F1 on the PKU-MMD dataset). Moreover, LDA is compatible with existing methods and improves their performance (e.g., +4.8\% Accuracy, +4.3\% F1 on the LARa dataset) without additional inference costs.
Skeleton-Based Action Segmentation with Multi-Stage Spatial-Temporal Graph Convolutional Neural Networks
Feb 03, 2022
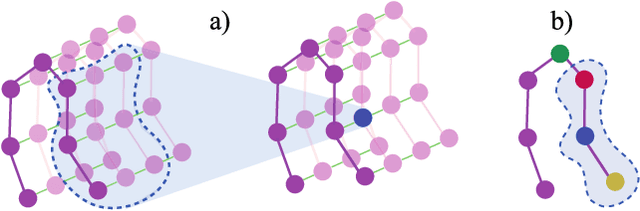

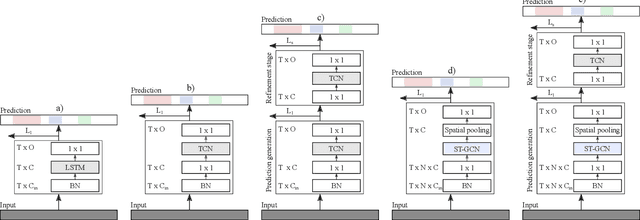
The ability to identify and temporally segment fine-grained actions in motion capture sequences is crucial for applications in human movement analysis. Motion capture is typically performed with optical or inertial measurement systems, which encode human movement as a time series of human joint locations and orientations or their higher-order representations. State-of-the-art action segmentation approaches use multiple stages of temporal convolutions. The main idea is to generate an initial prediction with several layers of temporal convolutions and refine these predictions over multiple stages, also with temporal convolutions. Although these approaches capture long-term temporal patterns, the initial predictions do not adequately consider the spatial hierarchy among the human joints. To address this limitation, we present multi-stage spatial-temporal graph convolutional neural networks (MS-GCN). Our framework decouples the architecture of the initial prediction generation stage from the refinement stages. Specifically, we replace the initial stage of temporal convolutions with spatial-temporal graph convolutions, which better exploit the spatial configuration of the joints and their temporal dynamics. Our framework was compared to four strong baselines on five tasks. Experimental results demonstrate that our framework achieves state-of-the-art performance.
Automated freezing of gait assessment with marker-based motion capture and multi-stage graph convolutional neural networks approaches expert-level detection
Apr 07, 2021
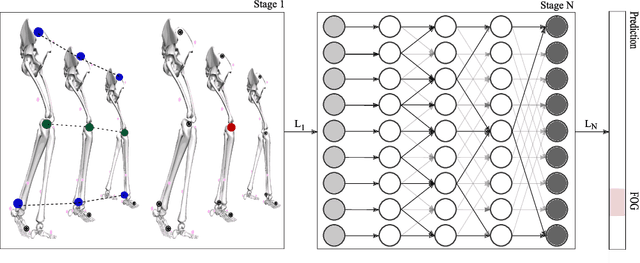


Freezing of gait (FOG) is a common and debilitating gait impairment in Parkinson's disease. Further insight in this phenomenon is hampered by the difficulty to objectively assess FOG. To meet this clinical need, this paper proposes a motion capture-based FOG assessment method driven by a novel deep neural network. The proposed network, termed multi-stage graph convolutional network (MS-GCN), combines the spatial-temporal graph convolutional network (ST-GCN) and the multi-stage temporal convolutional network (MS-TCN). The ST-GCN captures the hierarchical motion among the optical markers inherent to motion capture, while the multi-stage component reduces over-segmentation errors by refining the predictions over multiple stages. The proposed model was validated on a dataset of fourteen freezers, fourteen non-freezers, and fourteen healthy control subjects. The experiments indicate that the proposed model outperforms state-of-the-art baselines. An in-depth quantitative and qualitative analysis demonstrates that the proposed model is able to achieve clinician-like FOG assessment. The proposed MS-GCN can provide an automated and objective alternative to labor-intensive clinician-based FOG assessment.