 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMACMD: Multi-dilated Contextual Attention and Channel Mixer Decoding for Medical Image Segmentation
Nov 08, 2025Medical image segmentation faces challenges due to variations in anatomical structures. While convolutional neural networks (CNNs) effectively capture local features, they struggle with modeling long-range dependencies. Transformers mitigate this issue with self-attention mechanisms but lack the ability to preserve local contextual information. State-of-the-art models primarily follow an encoder-decoder architecture, achieving notable success. However, two key limitations remain: (1) Shallow layers, which are closer to the input, capture fine-grained details but suffer from information loss as data propagates through deeper layers. (2) Inefficient integration of local details and global context between the encoder and decoder stages. To address these challenges, we propose the MACMD-based decoder, which enhances attention mechanisms and facilitates channel mixing between encoder and decoder stages via skip connections. This design leverages hierarchical dilated convolutions, attention-driven modulation, and a cross channel-mixing module to capture long-range dependencies while preserving local contextual details, essential for precise medical image segmentation. We evaluated our approach using multiple transformer encoders on both binary and multi-organ segmentation tasks. The results demonstrate that our method outperforms state-of-the-art approaches in terms of Dice score and computational efficiency, highlighting its effectiveness in achieving accurate and robust segmentation performance. The code available at https://github.com/lalitmaurya47/MACMD
TCSA-UDA: Text-Driven Cross-Semantic Alignment for Unsupervised Domain Adaptation in Medical Image Segmentation
Nov 08, 2025Unsupervised domain adaptation for medical image segmentation remains a significant challenge due to substantial domain shifts across imaging modalities, such as CT and MRI. While recent vision-language representation learning methods have shown promise, their potential in UDA segmentation tasks remains underexplored. To address this gap, we propose TCSA-UDA, a Text-driven Cross-Semantic Alignment framework that leverages domain-invariant textual class descriptions to guide visual representation learning. Our approach introduces a vision-language covariance cosine loss to directly align image encoder features with inter-class textual semantic relations, encouraging semantically meaningful and modality-invariant feature representations. Additionally, we incorporate a prototype alignment module that aligns class-wise pixel-level feature distributions across domains using high-level semantic prototypes. This mitigates residual category-level discrepancies and enhances cross-modal consistency. Extensive experiments on challenging cross-modality cardiac, abdominal, and brain tumor segmentation benchmarks demonstrate that our TCSA-UDA framework significantly reduces domain shift and consistently outperforms state-of-the-art UDA methods, establishing a new paradigm for integrating language-driven semantics into domain-adaptive medical image analysis.
Natural Spectral Fusion: p-Exponent Cyclic Scheduling and Early Decision-Boundary Alignment in First-Order Optimization
Sep 05, 2025Spectral behaviors have been widely discussed in machine learning, yet the optimizer's own spectral bias remains unclear. We argue that first-order optimizers exhibit an intrinsic frequency preference that significantly reshapes the optimization path. To address this, we propose Natural Spectral Fusion (NSF): reframing training as controllable spectral coverage and information fusion rather than merely scaling step sizes. NSF has two core principles: treating the optimizer as a spectral controller that dynamically balances low- and high-frequency information; and periodically reweighting frequency bands at negligible cost, without modifying the model, data, or training pipeline. We realize NSF via a p-exponent extension of the second-moment term, enabling both positive and negative exponents, and implement it through cyclic scheduling. Theory and experiments show that adaptive methods emphasize low frequencies, SGD is near-neutral, and negative exponents amplify high-frequency information. Cyclic scheduling broadens spectral coverage, improves cross-band fusion, and induces early decision-boundary alignment, where accuracy improves even while loss remains high. Across multiple benchmarks, with identical learning-rate strategies and fixed hyperparameters, p-exponent cyclic scheduling consistently reduces test error and demonstrates distinct convergence behavior; on some tasks, it matches baseline accuracy with only one-quarter of the training cost. Overall, NSF reveals the optimizer's role as an active spectral controller and provides a unified, controllable, and efficient framework for first-order optimization.
Neural Parameter Search for Slimmer Fine-Tuned Models and Better Transfer
May 24, 2025Foundation models and their checkpoints have significantly advanced deep learning, boosting performance across various applications. However, fine-tuned models often struggle outside their specific domains and exhibit considerable redundancy. Recent studies suggest that combining a pruned fine-tuned model with the original pre-trained model can mitigate forgetting, reduce interference when merging model parameters across tasks, and improve compression efficiency. In this context, developing an effective pruning strategy for fine-tuned models is crucial. Leveraging the advantages of the task vector mechanism, we preprocess fine-tuned models by calculating the differences between them and the original model. Recognizing that different task vector subspaces contribute variably to model performance, we introduce a novel method called Neural Parameter Search (NPS-Pruning) for slimming down fine-tuned models. This method enhances pruning efficiency by searching through neural parameters of task vectors within low-rank subspaces. Our method has three key applications: enhancing knowledge transfer through pairwise model interpolation, facilitating effective knowledge fusion via model merging, and enabling the deployment of compressed models that retain near-original performance while significantly reducing storage costs. Extensive experiments across vision, NLP, and multi-modal benchmarks demonstrate the effectiveness and robustness of our approach, resulting in substantial performance gains. The code is publicly available at: https://github.com/duguodong7/NPS-Pruning.
Unsupervised Cross-Domain 3D Human Pose Estimation via Pseudo-Label-Guided Global Transforms
Apr 17, 2025Existing 3D human pose estimation methods often suffer in performance, when applied to cross-scenario inference, due to domain shifts in characteristics such as camera viewpoint, position, posture, and body size. Among these factors, camera viewpoints and locations {have been shown} to contribute significantly to the domain gap by influencing the global positions of human poses. To address this, we propose a novel framework that explicitly conducts global transformations between pose positions in the camera coordinate systems of source and target domains. We start with a Pseudo-Label Generation Module that is applied to the 2D poses of the target dataset to generate pseudo-3D poses. Then, a Global Transformation Module leverages a human-centered coordinate system as a novel bridging mechanism to seamlessly align the positional orientations of poses across disparate domains, ensuring consistent spatial referencing. To further enhance generalization, a Pose Augmentor is incorporated to address variations in human posture and body size. This process is iterative, allowing refined pseudo-labels to progressively improve guidance for domain adaptation. Our method is evaluated on various cross-dataset benchmarks, including Human3.6M, MPI-INF-3DHP, and 3DPW. The proposed method outperforms state-of-the-art approaches and even outperforms the target-trained model.
Text-Derived Relational Graph-Enhanced Network for Skeleton-Based Action Segmentation
Mar 19, 2025Skeleton-based Temporal Action Segmentation (STAS) aims to segment and recognize various actions from long, untrimmed sequences of human skeletal movements. Current STAS methods typically employ spatio-temporal modeling to establish dependencies among joints as well as frames, and utilize one-hot encoding with cross-entropy loss for frame-wise classification supervision. However, these methods overlook the intrinsic correlations among joints and actions within skeletal features, leading to a limited understanding of human movements. To address this, we propose a Text-Derived Relational Graph-Enhanced Network (TRG-Net) that leverages prior graphs generated by Large Language Models (LLM) to enhance both modeling and supervision. For modeling, the Dynamic Spatio-Temporal Fusion Modeling (DSFM) method incorporates Text-Derived Joint Graphs (TJG) with channel- and frame-level dynamic adaptation to effectively model spatial relations, while integrating spatio-temporal core features during temporal modeling. For supervision, the Absolute-Relative Inter-Class Supervision (ARIS) method employs contrastive learning between action features and text embeddings to regularize the absolute class distributions, and utilizes Text-Derived Action Graphs (TAG) to capture the relative inter-class relationships among action features. Additionally, we propose a Spatial-Aware Enhancement Processing (SAEP) method, which incorporates random joint occlusion and axial rotation to enhance spatial generalization. Performance evaluations on four public datasets demonstrate that TRG-Net achieves state-of-the-art results.
Language-Assisted Human Part Motion Learning for Skeleton-Based Temporal Action Segmentation
Oct 08, 2024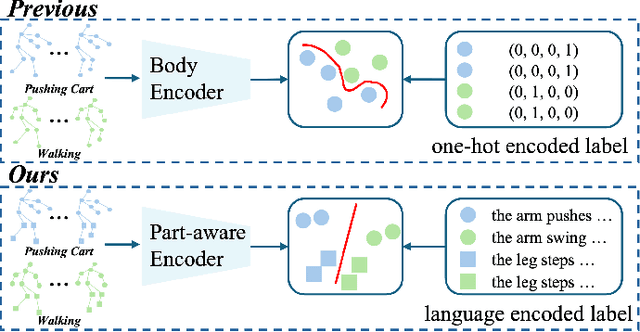
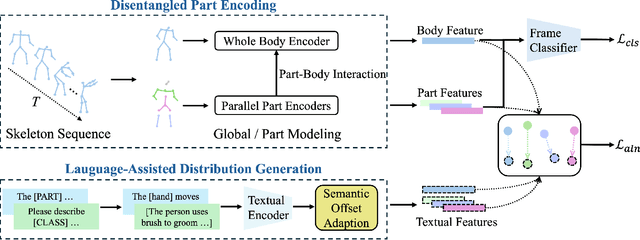
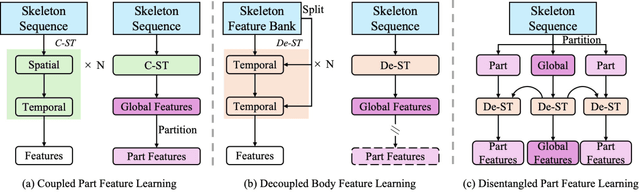
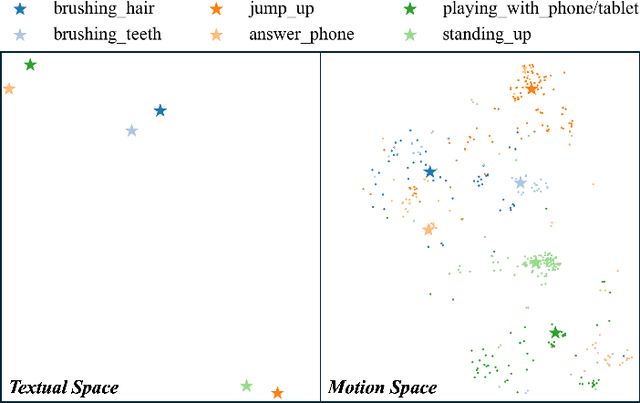
Skeleton-based Temporal Action Segmentation involves the dense action classification of variable-length skeleton sequences. Current approaches primarily apply graph-based networks to extract framewise, whole-body-level motion representations, and use one-hot encoded labels for model optimization. However, whole-body motion representations do not capture fine-grained part-level motion representations and the one-hot encoded labels neglect the intrinsic semantic relationships within the language-based action definitions. To address these limitations, we propose a novel method named Language-assisted Human Part Motion Representation Learning (LPL), which contains a Disentangled Part Motion Encoder (DPE) to extract dual-level (i.e., part and whole-body) motion representations and a Language-assisted Distribution Alignment (LDA) strategy for optimizing spatial relations within representations. Specifically, after part-aware skeleton encoding via DPE, LDA generates dual-level action descriptions to construct a textual embedding space with the help of a large-scale language model. Then, LDA motivates the alignment of the embedding space between text descriptions and motions. This alignment allows LDA not only to enhance intra-class compactness but also to transfer the language-encoded semantic correlations among actions to skeleton-based motion learning. Moreover, we propose a simple yet efficient Semantic Offset Adapter to smooth the cross-domain misalignment. Our experiments indicate that LPL achieves state-of-the-art performance across various datasets (e.g., +4.4\% Accuracy, +5.6\% F1 on the PKU-MMD dataset). Moreover, LDA is compatible with existing methods and improves their performance (e.g., +4.8\% Accuracy, +4.3\% F1 on the LARa dataset) without additional inference costs.
Online 4D Ultrasound-Guided Robotic Tracking Enables 3D Ultrasound Localisation Microscopy with Large Tissue Displacements
Sep 17, 2024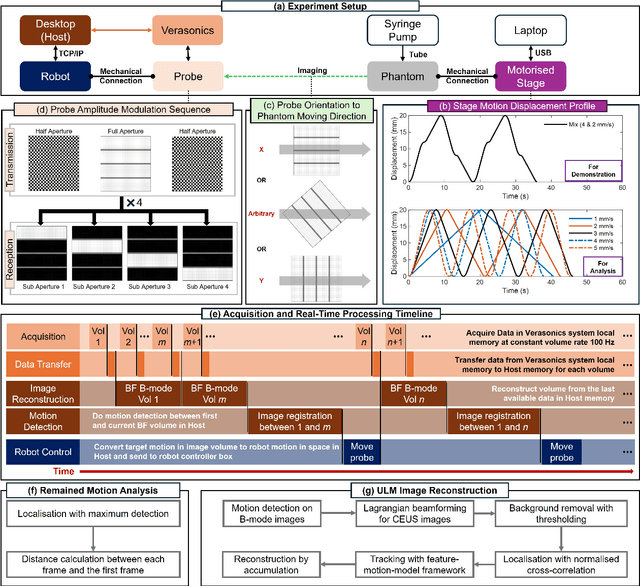
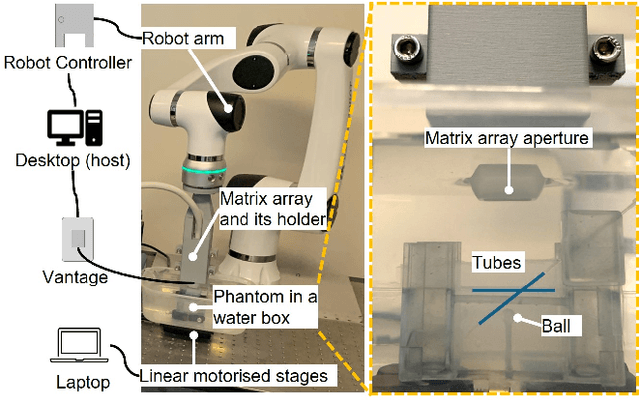

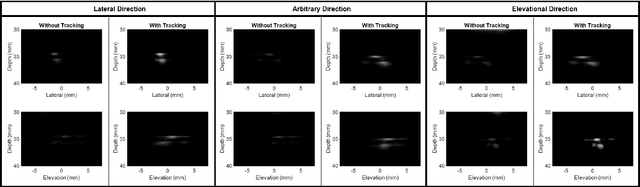
Super-Resolution Ultrasound (SRUS) imaging through localising and tracking microbubbles, also known as Ultrasound Localisation Microscopy (ULM), has demonstrated significant potential for reconstructing microvasculature and flows with sub-diffraction resolution in clinical diagnostics. However, imaging organs with large tissue movements, such as those caused by respiration, presents substantial challenges. Existing methods often require breath holding to maintain accumulation accuracy, which limits data acquisition time and ULM image saturation. To improve image quality in the presence of large tissue movements, this study introduces an approach integrating high-frame-rate ultrasound with online precise robotic probe control. Tested on a microvasculature phantom with translation motions up to 20 mm, twice the aperture size of the matrix array used, our method achieved real-time tracking of the moving phantom and imaging volume rate at 85 Hz, keeping majority of the target volume in the imaging field of view. ULM images of the moving cross channels in the phantom were successfully reconstructed in post-processing, demonstrating the feasibility of super-resolution imaging under large tissue motions. This represents a significant step towards ULM imaging of organs with large motion.
The Unified Balance Theory of Second-Moment Exponential Scaling Optimizers in Visual Tasks
May 28, 2024We have identified a potential method for unifying first-order optimizers through the use of variable Second-Moment Exponential Scaling(SMES). We begin with back propagation, addressing classic phenomena such as gradient vanishing and explosion, as well as issues related to dataset sparsity, and introduce the theory of balance in optimization. Through this theory, we suggest that SGD and adaptive optimizers can be unified under a broader inference, employing variable moving exponential scaling to achieve a balanced approach within a generalized formula for first-order optimizers. We conducted tests on some classic datasets and networks to confirm the impact of different balance coefficients on the overall training process.
Exploring Self- and Cross-Triplet Correlations for Human-Object Interaction Detection
Jan 11, 2024



Human-Object Interaction (HOI) detection plays a vital role in scene understanding, which aims to predict the HOI triplet in the form of <human, object, action>. Existing methods mainly extract multi-modal features (e.g., appearance, object semantics, human pose) and then fuse them together to directly predict HOI triplets. However, most of these methods focus on seeking for self-triplet aggregation, but ignore the potential cross-triplet dependencies, resulting in ambiguity of action prediction. In this work, we propose to explore Self- and Cross-Triplet Correlations (SCTC) for HOI detection. Specifically, we regard each triplet proposal as a graph where Human, Object represent nodes and Action indicates edge, to aggregate self-triplet correlation. Also, we try to explore cross-triplet dependencies by jointly considering instance-level, semantic-level, and layout-level relations. Besides, we leverage the CLIP model to assist our SCTC obtain interaction-aware feature by knowledge distillation, which provides useful action clues for HOI detection. Extensive experiments on HICO-DET and V-COCO datasets verify the effectiveness of our proposed SCTC.