 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Asymmetric Momentum Make SGD Greatest Again
Sep 05, 2023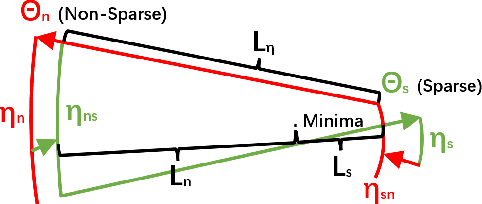

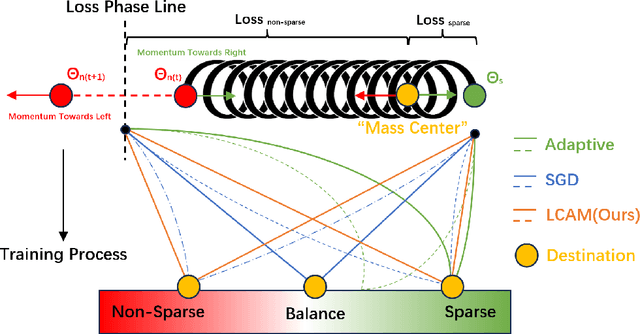
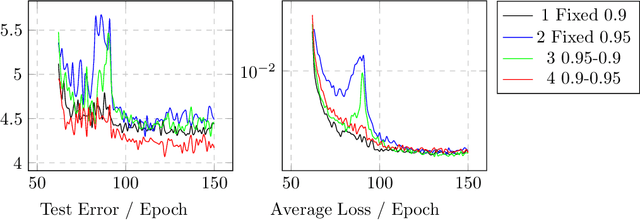
We propose the simplest SGD enhanced method ever, Loss-Controlled Asymmetric Momentum(LCAM), aimed directly at the Saddle Point problem. Compared to the traditional SGD with Momentum, there's no increase in computational demand, yet it outperforms all current optimizers. We use the concepts of weight conjugation and traction effect to explain this phenomenon. We designed experiments to rapidly reduce the learning rate at specified epochs to trap parameters more easily at saddle points. We selected WRN28-10 as the test network and chose cifar10 and cifar100 as test datasets, an identical group to the original paper of WRN and Cosine Annealing Scheduling(CAS). We compared the ability to bypass saddle points of Asymmetric Momentum with different priorities. Finally, using WRN28-10 on Cifar100, we achieved a peak average test accuracy of 80.78\% around 120 epoch. For comparison, the original WRN paper reported 80.75\%, while CAS was at 80.42\%, all at 200 epoch. This means that while potentially increasing accuracy, we use nearly half convergence time. Our demonstration code is available at\\ https://github.com/hakumaicc/Asymmetric-Momentum-LCAM