 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowPIE: Test-Time Scientific Idea Evolution with Flow-Guided Literature Exploration
Mar 31, 2026Scientific idea generation (SIG) is critical to AI-driven autonomous research, yet existing approaches are often constrained by a static retrieval-then-generation paradigm, leading to homogeneous and insufficiently divergent ideas. In this work, we propose FlowPIE, a tightly coupled retrieval-generation framework that treats literature exploration and idea generation as a co-evolving process. FlowPIE expands literature trajectories via a flow-guided Monte Carlo Tree Search (MCTS) inspired by GFlowNets, using the quality of current ideas assessed by an LLM-based generative reward model (GRM) as a supervised signal to guide adaptive retrieval and construct a diverse, high-quality initial population. Based on this population, FlowPIE models idea generation as a test-time idea evolution process, applying selection, crossover, and mutation with the isolation island paradigm and GRM-based fitness computation to incorporate cross-domain knowledge. It effectively mitigates the information cocoons arising from over-reliance on parametric knowledge and static literature. Extensive evaluations demonstrate that FlowPIE consistently produces ideas with higher novelty, feasibility and diversity compared to strong LLM-based and agent-based frameworks, while enabling reward scaling during test time.
LaDy: Lagrangian-Dynamic Informed Network for Skeleton-based Action Segmentation via Spatial-Temporal Modulation
Mar 25, 2026Skeleton-based Temporal Action Segmentation (STAS) aims to densely parse untrimmed skeletal sequences into frame-level action categories. However, existing methods, while proficient at capturing spatio-temporal kinematics, neglect the underlying physical dynamics that govern human motion. This oversight limits inter-class discriminability between actions with similar kinematics but distinct dynamic intents, and hinders precise boundary localization where dynamic force profiles shift. To address these, we propose the Lagrangian-Dynamic Informed Network (LaDy), a framework integrating principles of Lagrangian dynamics into the segmentation process. Specifically, LaDy first computes generalized coordinates from joint positions and then estimates Lagrangian terms under physical constraints to explicitly synthesize the generalized forces. To further ensure physical coherence, our Energy Consistency Loss enforces the work-energy theorem, aligning kinetic energy change with the work done by the net force. The learned dynamics then drive a Spatio-Temporal Modulation module: Spatially, generalized forces are fused with spatial representations to provide more discriminative semantics. Temporally, salient dynamic signals are constructed for temporal gating, thereby significantly enhancing boundary awareness. Experiments on challenging datasets show that LaDy achieves state-of-the-art performance, validating the integration of physical dynamics for action segmentation. Code is available at https://github.com/HaoyuJi/LaDy.
Spectral Scalpel: Amplifying Adjacent Action Discrepancy via Frequency-Selective Filtering for Skeleton-Based Action Segmentation
Mar 25, 2026Skeleton-based Temporal Action Segmentation (STAS) seeks to densely segment and classify diverse actions within long, untrimmed skeletal motion sequences. However, existing STAS methodologies face challenges of limited inter-class discriminability and blurred segmentation boundaries, primarily due to insufficient distinction of spatio-temporal patterns between adjacent actions. To address these limitations, we propose Spectral Scalpel, a frequency-selective filtering framework aimed at suppressing shared frequency components between adjacent distinct actions while amplifying their action-specific frequencies, thereby enhancing inter-action discrepancies and sharpening transition boundaries. Specifically, Spectral Scalpel employs adaptive multi-scale spectral filters as scalpels to edit frequency spectra, coupled with a discrepancy loss between adjacent actions serving as the surgical objective. This design amplifies representational disparities between neighboring actions, effectively mitigating boundary localization ambiguities and inter-class confusion. Furthermore, complementing long-term temporal modeling, we introduce a frequency-aware channel mixer to strengthen channel evolution by aggregating spectra across channels. This work presents a novel paradigm for STAS that extends conventional spatio-temporal modeling by incorporating frequency-domain analysis. Extensive experiments on five public datasets demonstrate that Spectral Scalpel achieves state-of-the-art performance. Code is available at https://github.com/HaoyuJi/SpecScalpel.
RuCL: Stratified Rubric-Based Curriculum Learning for Multimodal Large Language Model Reasoning
Feb 25, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a prevailing paradigm for enhancing reasoning in Multimodal Large Language Models (MLLMs). However, relying solely on outcome supervision risks reward hacking, where models learn spurious reasoning patterns to satisfy final answer checks. While recent rubric-based approaches offer fine-grained supervision signals, they suffer from high computational costs of instance-level generation and inefficient training dynamics caused by treating all rubrics as equally learnable. In this paper, we propose Stratified Rubric-based Curriculum Learning (RuCL), a novel framework that reformulates curriculum learning by shifting the focus from data selection to reward design. RuCL generates generalized rubrics for broad applicability and stratifies them based on the model's competence. By dynamically adjusting rubric weights during training, RuCL guides the model from mastering foundational perception to tackling advanced logical reasoning. Extensive experiments on various visual reasoning benchmarks show that RuCL yields a remarkable +7.83% average improvement over the Qwen2.5-VL-7B model, achieving a state-of-the-art accuracy of 60.06%.
Training Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
Improving the accuracy and generalizability of molecular property regression models with a substructure-substitution-rule-informed framework
Nov 11, 2025Artificial Intelligence (AI)-aided drug discovery is an active research field, yet AI models often exhibit poor accuracy in regression tasks for molecular property prediction, and perform catastrophically poorly for out-of-distribution (OOD) molecules. Here, we present MolRuleLoss, a substructure-substitution-rule-informed framework that improves the accuracy and generalizability of multiple molecular property regression models (MPRMs) such as GEM and UniMol for diverse molecular property prediction tasks. MolRuleLoss incorporates partial derivative constraints for substructure substitution rules (SSRs) into an MPRM's loss function. When using GEM models for predicting lipophilicity, water solubility, and solvation-free energy (using lipophilicity, ESOL, and freeSolv datasets from MoleculeNet), the root mean squared error (RMSE) values with and without MolRuleLoss were 0.587 vs. 0.660, 0.777 vs. 0.798, and 1.252 vs. 1.877, respectively, representing 2.6-33.3% performance improvements. We show that both the number and the quality of SSRs contribute to the magnitude of prediction accuracy gains obtained upon adding MolRuleLoss to an MPRM. MolRuleLoss improved the generalizability of MPRMs for "activity cliff" molecules in a lipophilicity prediction task and improved the generalizability of MPRMs for OOD molecules in a melting point prediction task. In a molecular weight prediction task for OOD molecules, MolRuleLoss reduced the RMSE value of a GEM model from 29.507 to 0.007. We also provide a formal demonstration that the upper bound of the variation for property change of SSRs is positively correlated with an MPRM's error. Together, we show that using the MolRuleLoss framework as a bolt-on boosts the prediction accuracy and generalizability of multiple MPRMs, supporting diverse applications in areas like cheminformatics and AI-aided drug discovery.
Modeling the Multivariate Relationship with Contextualized Representations for Effective Human-Object Interaction Detection
Sep 16, 2025Human-Object Interaction (HOI) detection aims to simultaneously localize human-object pairs and recognize their interactions. While recent two-stage approaches have made significant progress, they still face challenges due to incomplete context modeling. In this work, we introduce a Contextualized Representation Learning Network that integrates both affordance-guided reasoning and contextual prompts with visual cues to better capture complex interactions. We enhance the conventional HOI detection framework by expanding it beyond simple human-object pairs to include multivariate relationships involving auxiliary entities like tools. Specifically, we explicitly model the functional role (affordance) of these auxiliary objects through triplet structures <human, tool, object>. This enables our model to identify tool-dependent interactions such as 'filling'. Furthermore, the learnable prompt is enriched with instance categories and subsequently integrated with contextual visual features using an attention mechanism. This process aligns language with image content at both global and regional levels. These contextualized representations equip the model with enriched relational cues for more reliable reasoning over complex, context-dependent interactions. Our proposed method demonstrates superior performance on both the HICO-Det and V-COCO datasets in most scenarios. Codes will be released upon acceptance.
Technical Report of TeleChat2, TeleChat2.5 and T1
Jul 24, 2025
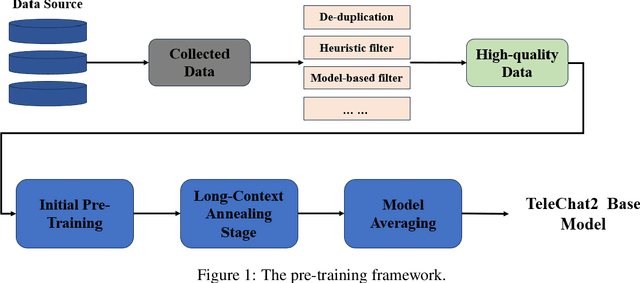

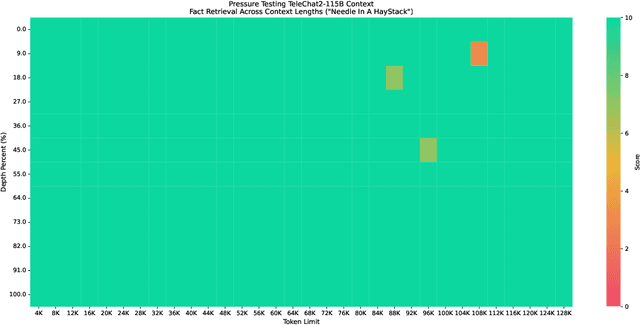
We introduce the latest series of TeleChat models: \textbf{TeleChat2}, \textbf{TeleChat2.5}, and \textbf{T1}, offering a significant upgrade over their predecessor, TeleChat. Despite minimal changes to the model architecture, the new series achieves substantial performance gains through enhanced training strategies in both pre-training and post-training stages. The series begins with \textbf{TeleChat2}, which undergoes pretraining on 10 trillion high-quality and diverse tokens. This is followed by Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) to further enhance its capabilities. \textbf{TeleChat2.5} and \textbf{T1} expand the pipeline by incorporating a continual pretraining phase with domain-specific datasets, combined with reinforcement learning (RL) to improve performance in code generation and mathematical reasoning tasks. The \textbf{T1} variant is designed for complex reasoning, supporting long Chain-of-Thought (CoT) reasoning and demonstrating substantial improvements in mathematics and coding. In contrast, \textbf{TeleChat2.5} prioritizes speed, delivering rapid inference. Both flagship models of \textbf{T1} and \textbf{TeleChat2.5} are dense Transformer-based architectures with 115B parameters, showcasing significant advancements in reasoning and general task performance compared to the original TeleChat. Notably, \textbf{T1-115B} outperform proprietary models such as OpenAI's o1-mini and GPT-4o. We publicly release \textbf{TeleChat2}, \textbf{TeleChat2.5} and \textbf{T1}, including post-trained versions with 35B and 115B parameters, to empower developers and researchers with state-of-the-art language models tailored for diverse applications.
EVADE: Multimodal Benchmark for Evasive Content Detection in E-Commerce Applications
May 23, 2025E-commerce platforms increasingly rely on Large Language Models (LLMs) and Vision-Language Models (VLMs) to detect illicit or misleading product content. However, these models remain vulnerable to evasive content: inputs (text or images) that superficially comply with platform policies while covertly conveying prohibited claims. Unlike traditional adversarial attacks that induce overt failures, evasive content exploits ambiguity and context, making it far harder to detect. Existing robustness benchmarks provide little guidance for this demanding, real-world challenge. We introduce EVADE, the first expert-curated, Chinese, multimodal benchmark specifically designed to evaluate foundation models on evasive content detection in e-commerce. The dataset contains 2,833 annotated text samples and 13,961 images spanning six demanding product categories, including body shaping, height growth, and health supplements. Two complementary tasks assess distinct capabilities: Single-Violation, which probes fine-grained reasoning under short prompts, and All-in-One, which tests long-context reasoning by merging overlapping policy rules into unified instructions. Notably, the All-in-One setting significantly narrows the performance gap between partial and full-match accuracy, suggesting that clearer rule definitions improve alignment between human and model judgment. We benchmark 26 mainstream LLMs and VLMs and observe substantial performance gaps: even state-of-the-art models frequently misclassify evasive samples. By releasing EVADE and strong baselines, we provide the first rigorous standard for evaluating evasive-content detection, expose fundamental limitations in current multimodal reasoning, and lay the groundwork for safer and more transparent content moderation systems in e-commerce. The dataset is publicly available at https://huggingface.co/datasets/koenshen/EVADE-Bench.
Text-Derived Relational Graph-Enhanced Network for Skeleton-Based Action Segmentation
Mar 19, 2025Skeleton-based Temporal Action Segmentation (STAS) aims to segment and recognize various actions from long, untrimmed sequences of human skeletal movements. Current STAS methods typically employ spatio-temporal modeling to establish dependencies among joints as well as frames, and utilize one-hot encoding with cross-entropy loss for frame-wise classification supervision. However, these methods overlook the intrinsic correlations among joints and actions within skeletal features, leading to a limited understanding of human movements. To address this, we propose a Text-Derived Relational Graph-Enhanced Network (TRG-Net) that leverages prior graphs generated by Large Language Models (LLM) to enhance both modeling and supervision. For modeling, the Dynamic Spatio-Temporal Fusion Modeling (DSFM) method incorporates Text-Derived Joint Graphs (TJG) with channel- and frame-level dynamic adaptation to effectively model spatial relations, while integrating spatio-temporal core features during temporal modeling. For supervision, the Absolute-Relative Inter-Class Supervision (ARIS) method employs contrastive learning between action features and text embeddings to regularize the absolute class distributions, and utilizes Text-Derived Action Graphs (TAG) to capture the relative inter-class relationships among action features. Additionally, we propose a Spatial-Aware Enhancement Processing (SAEP) method, which incorporates random joint occlusion and axial rotation to enhance spatial generalization. Performance evaluations on four public datasets demonstrate that TRG-Net achieves state-of-the-art results.