 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsolated Channel Vision Transformers: From Single-Channel Pretraining to Multi-Channel Finetuning
Mar 12, 2025Vision Transformers (ViTs) have achieved remarkable success in standard RGB image processing tasks. However, applying ViTs to multi-channel imaging (MCI) data, e.g., for medical and remote sensing applications, remains a challenge. In particular, MCI data often consist of layers acquired from different modalities. Directly training ViTs on such data can obscure complementary information and impair the performance. In this paper, we introduce a simple yet effective pretraining framework for large-scale MCI datasets. Our method, named Isolated Channel ViT (IC-ViT), patchifies image channels individually and thereby enables pretraining for multimodal multi-channel tasks. We show that this channel-wise patchifying is a key technique for MCI processing. More importantly, one can pretrain the IC-ViT on single channels and finetune it on downstream multi-channel datasets. This pretraining framework captures dependencies between patches as well as channels and produces robust feature representation. Experiments on various tasks and benchmarks, including JUMP-CP and CHAMMI for cell microscopy imaging, and So2Sat-LCZ42 for satellite imaging, show that the proposed IC-ViT delivers 4-14 percentage points of performance improvement over existing channel-adaptive approaches. Further, its efficient training makes it a suitable candidate for large-scale pretraining of foundation models on heterogeneous data.
Let it shine: Autofluorescence of Papanicolaou-stain improves AI-based cytological oral cancer detection
Jul 02, 2024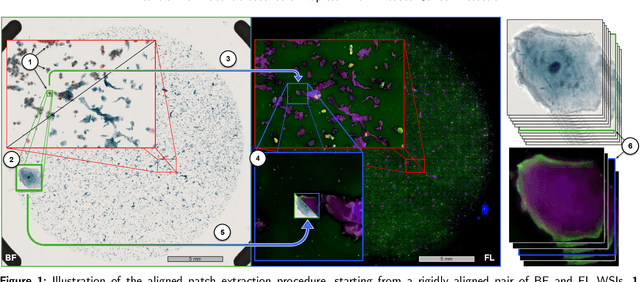
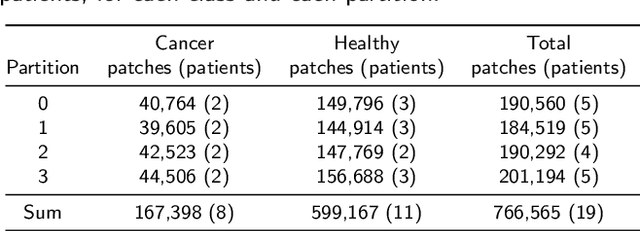
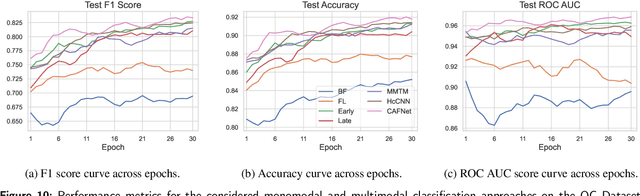
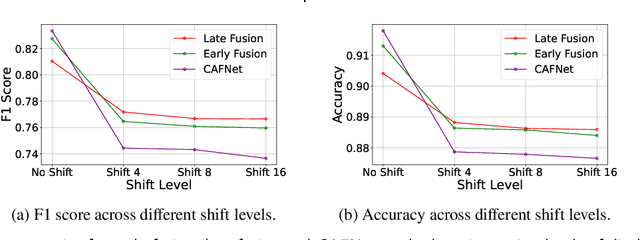
Oral cancer is a global health challenge. It is treatable if detected early, but it is often fatal in late stages. There is a shift from the invasive and time-consuming tissue sampling and histological examination, toward non-invasive brush biopsies and cytological examination. Reliable computer-assisted methods are essential for cost-effective and accurate cytological analysis, but the lack of detailed cell-level annotations impairs model effectiveness. This study aims to improve AI-based oral cancer detection using multimodal imaging and deep fusion. We combine brightfield and fluorescence whole slide microscopy imaging to analyze Papanicolaou-stained liquid-based cytology slides of brush biopsies collected from both healthy and cancer patients. Due to limited cytological annotations, we utilize a weakly supervised deep learning approach using only patient-level labels. We evaluate various multimodal fusion strategies, including early, late, and three recent intermediate fusion methods. Our results show: (i) fluorescence imaging of Papanicolaou-stained samples provides substantial diagnostic information; (ii) multimodal fusion enhances classification and cancer detection accuracy over single-modality methods. Intermediate fusion is the leading method among the studied approaches. Specifically, the Co-Attention Fusion Network (CAFNet) model excels with an F1 score of 83.34% and accuracy of 91.79%, surpassing human performance on the task. Additional tests highlight the need for precise image registration to optimize multimodal analysis benefits. This study advances cytopathology by combining deep learning and multimodal imaging to enhance early, non-invasive detection of oral cancer, improving diagnostic accuracy and streamlining clinical workflows. The developed pipeline is also applicable in other cytological settings. Our codes and dataset are available online for further research.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024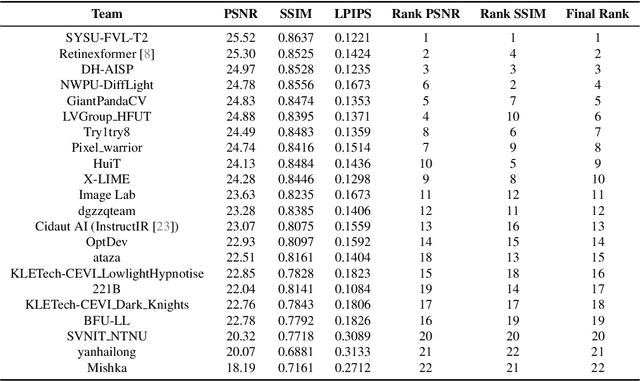


This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Equipping Diffusion Models with Differentiable Spatial Entropy for Low-Light Image Enhancement
Apr 15, 2024
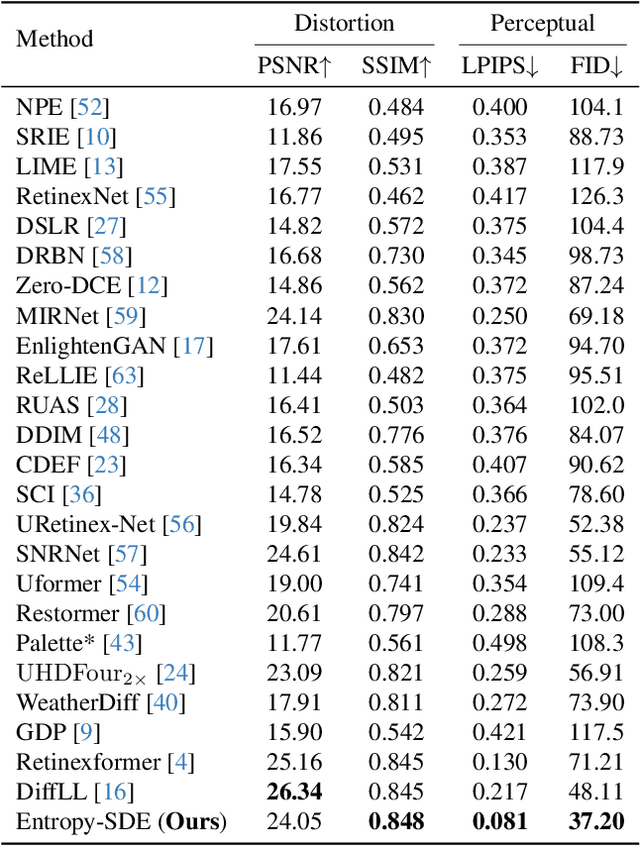


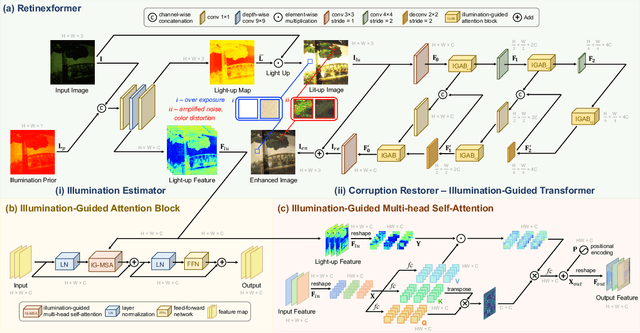
Image restoration, which aims to recover high-quality images from their corrupted counterparts, often faces the challenge of being an ill-posed problem that allows multiple solutions for a single input. However, most deep learning based works simply employ l1 loss to train their network in a deterministic way, resulting in over-smoothed predictions with inferior perceptual quality. In this work, we propose a novel method that shifts the focus from a deterministic pixel-by-pixel comparison to a statistical perspective, emphasizing the learning of distributions rather than individual pixel values. The core idea is to introduce spatial entropy into the loss function to measure the distribution difference between predictions and targets. To make this spatial entropy differentiable, we employ kernel density estimation (KDE) to approximate the probabilities for specific intensity values of each pixel with their neighbor areas. Specifically, we equip the entropy with diffusion models and aim for superior accuracy and enhanced perceptual quality over l1 based noise matching loss. In the experiments, we evaluate the proposed method for low light enhancement on two datasets and the NTIRE challenge 2024. All these results illustrate the effectiveness of our statistic-based entropy loss. Code is available at https://github.com/shermanlian/spatial-entropy-loss.
BokehOrNot: Transforming Bokeh Effect with Image Transformer and Lens Metadata Embedding
Jun 06, 2023



Bokeh effect is an optical phenomenon that offers a pleasant visual experience, typically generated by high-end cameras with wide aperture lenses. The task of bokeh effect transformation aims to produce a desired effect in one set of lenses and apertures based on another combination. Current models are limited in their ability to render a specific set of bokeh effects, primarily transformations from sharp to blur. In this paper, we propose a novel universal method for embedding lens metadata into the model and introducing a loss calculation method using alpha masks from the newly released Bokeh Effect Transformation Dataset(BETD) [3]. Based on the above techniques, we propose the BokehOrNot model, which is capable of producing both blur-to-sharp and sharp-to-blur bokeh effect with various combinations of lenses and aperture sizes. Our proposed model outperforms current leading bokeh rendering and image restoration models and renders visually natural bokeh effects. Our code is available at: https://github.com/indicator0/bokehornot.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
Sliding Window Recurrent Network for Efficient Video Super-Resolution
Aug 24, 2022
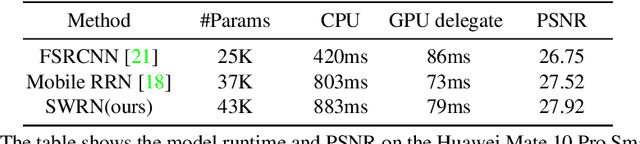
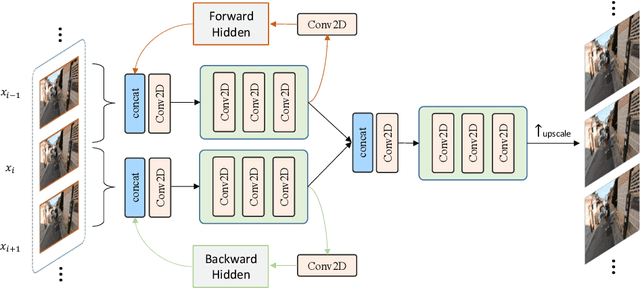
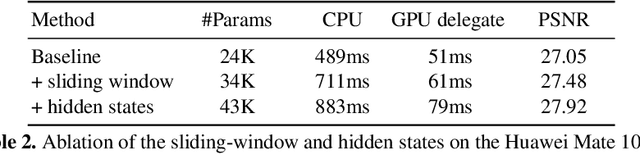
Video super-resolution (VSR) is the task of restoring high-resolution frames from a sequence of low-resolution inputs. Different from single image super-resolution, VSR can utilize frames' temporal information to reconstruct results with more details. Recently, with the rapid development of convolution neural networks (CNN), the VSR task has drawn increasing attention and many CNN-based methods have achieved remarkable results. However, only a few VSR approaches can be applied to real-world mobile devices due to the computational resources and runtime limitations. In this paper, we propose a \textit{Sliding Window based Recurrent Network} (SWRN) which can be real-time inference while still achieving superior performance. Specifically, we notice that video frames should have both spatial and temporal relations that can help to recover details, and the key point is how to extract and aggregate information. Address it, we input three neighboring frames and utilize a hidden state to recurrently store and update the important temporal information. Our experiment on REDS dataset shows that the proposed method can be well adapted to mobile devices and produce visually pleasant results.
Kernel-aware Raw Burst Blind Super-Resolution
Dec 14, 2021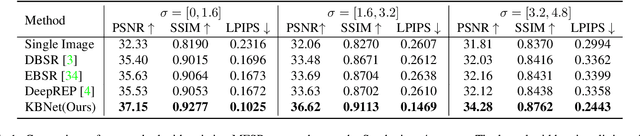

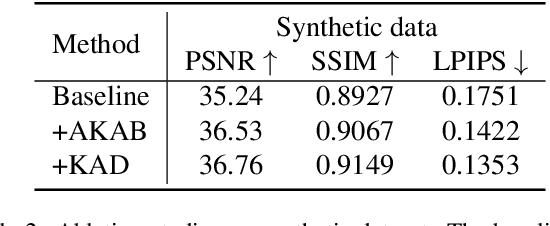
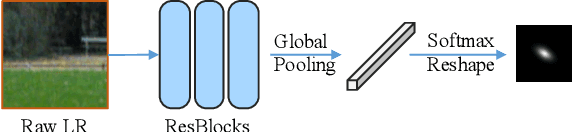
Burst super-resolution (SR) provides a possibility of restoring rich details from low-quality images. However, since low-resolution (LR) images in practical applications have multiple complicated and unknown degradations, existing non-blind (e.g., bicubic) designed networks usually lead to a severe performance drop in recovering high-resolution (HR) images. Moreover, handling multiple misaligned noisy raw inputs is also challenging. In this paper, we address the problem of reconstructing HR images from raw burst sequences acquired from modern handheld devices. The central idea is a kernel-guided strategy which can solve the burst SR with two steps: kernel modeling and HR restoring. The former estimates burst kernels from raw inputs, while the latter predicts the super-resolved image based on the estimated kernels. Furthermore, we introduce a kernel-aware deformable alignment module which can effectively align the raw images with consideration of the blurry priors. Extensive experiments on synthetic and real-world datasets demonstrate that the proposed method can perform favorable state-of-the-art performance in the burst SR problem.