 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024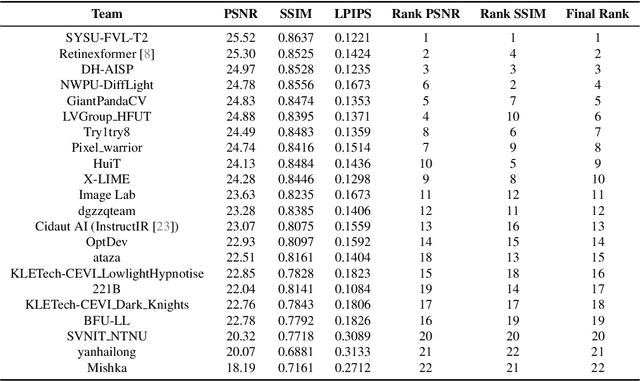


This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Equipping Diffusion Models with Differentiable Spatial Entropy for Low-Light Image Enhancement
Apr 15, 2024
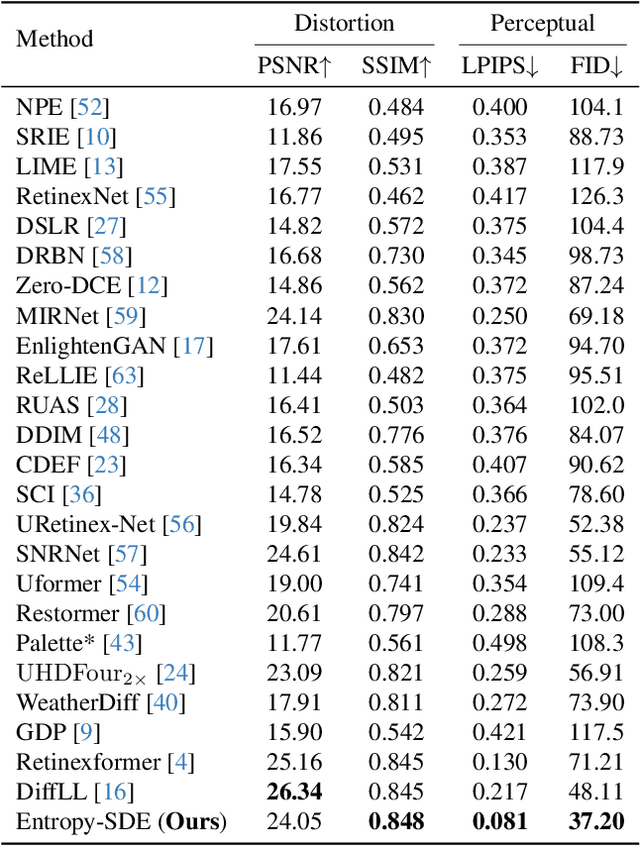


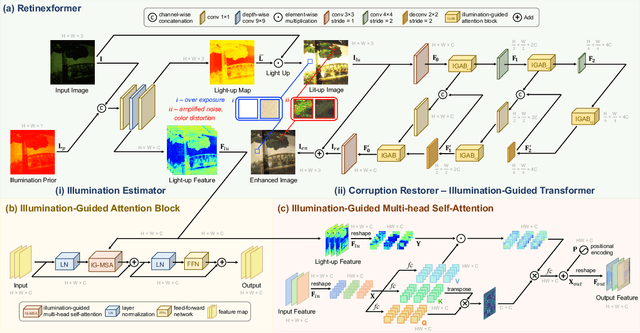
Image restoration, which aims to recover high-quality images from their corrupted counterparts, often faces the challenge of being an ill-posed problem that allows multiple solutions for a single input. However, most deep learning based works simply employ l1 loss to train their network in a deterministic way, resulting in over-smoothed predictions with inferior perceptual quality. In this work, we propose a novel method that shifts the focus from a deterministic pixel-by-pixel comparison to a statistical perspective, emphasizing the learning of distributions rather than individual pixel values. The core idea is to introduce spatial entropy into the loss function to measure the distribution difference between predictions and targets. To make this spatial entropy differentiable, we employ kernel density estimation (KDE) to approximate the probabilities for specific intensity values of each pixel with their neighbor areas. Specifically, we equip the entropy with diffusion models and aim for superior accuracy and enhanced perceptual quality over l1 based noise matching loss. In the experiments, we evaluate the proposed method for low light enhancement on two datasets and the NTIRE challenge 2024. All these results illustrate the effectiveness of our statistic-based entropy loss. Code is available at https://github.com/shermanlian/spatial-entropy-loss.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
Sliding Window Recurrent Network for Efficient Video Super-Resolution
Aug 24, 2022
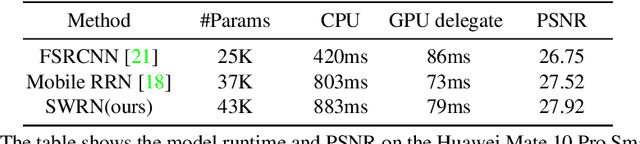
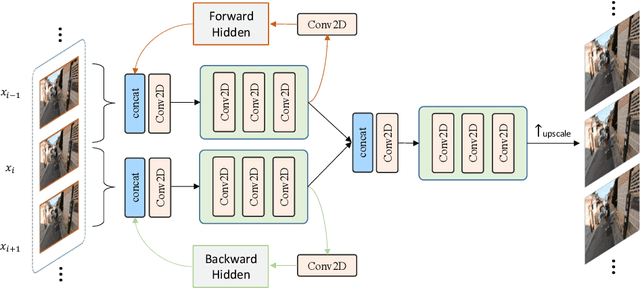
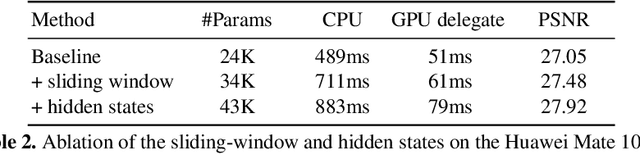
Video super-resolution (VSR) is the task of restoring high-resolution frames from a sequence of low-resolution inputs. Different from single image super-resolution, VSR can utilize frames' temporal information to reconstruct results with more details. Recently, with the rapid development of convolution neural networks (CNN), the VSR task has drawn increasing attention and many CNN-based methods have achieved remarkable results. However, only a few VSR approaches can be applied to real-world mobile devices due to the computational resources and runtime limitations. In this paper, we propose a \textit{Sliding Window based Recurrent Network} (SWRN) which can be real-time inference while still achieving superior performance. Specifically, we notice that video frames should have both spatial and temporal relations that can help to recover details, and the key point is how to extract and aggregate information. Address it, we input three neighboring frames and utilize a hidden state to recurrently store and update the important temporal information. Our experiment on REDS dataset shows that the proposed method can be well adapted to mobile devices and produce visually pleasant results.