 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Rewarding Sequential Monte Carlo for Masked Diffusion Language Models
Feb 02, 2026This work presents self-rewarding sequential Monte Carlo (SMC), an inference-time scaling algorithm enabling effective sampling of masked diffusion language models (MDLMs). Our algorithm stems from the observation that most existing MDLMs rely on a confidence-based sampling strategy, where only tokens with the highest prediction confidence are preserved at each step. This restricts the generation to a noise-sensitive, greedy decoding paradigm, resulting in an inevitable collapse in the diversity of possible paths. We address this problem by launching multiple interacting diffusion processes in parallel, referred to as particles, for trajectory exploration. Importantly, we introduce the trajectory-level confidence as a self-rewarding signal for assigning particle importance weights. During sampling, particles are iteratively weighted and resampled to systematically steer generation towards globally confident, high-quality samples. Our self-rewarding SMC is verified on various masked diffusion language models and benchmarks, achieving significant improvement without extra training or reward guidance, while effectively converting parallel inference capacity into improved sampling quality. Our code is available at https://github.com/Algolzw/self-rewarding-smc.
Forward-only Diffusion Probabilistic Models
May 22, 2025This work presents a forward-only diffusion (FoD) approach for generative modelling. In contrast to traditional diffusion models that rely on a coupled forward-backward diffusion scheme, FoD directly learns data generation through a single forward diffusion process, yielding a simple yet efficient generative framework. The core of FoD is a state-dependent linear stochastic differential equation that involves a mean-reverting term in both the drift and diffusion functions. This mean-reversion property guarantees the convergence to clean data, naturally simulating a stochastic interpolation between source and target distributions. More importantly, FoD is analytically tractable and is trained using a simple stochastic flow matching objective, enabling a few-step non-Markov chain sampling during inference. The proposed FoD model, despite its simplicity, achieves competitive performance on various image-conditioned (e.g., image restoration) and unconditional generation tasks, demonstrating its effectiveness in generative modelling. Our code is available at https://github.com/Algolzw/FoD.
Taming Diffusion Models for Image Restoration: A Review
Sep 16, 2024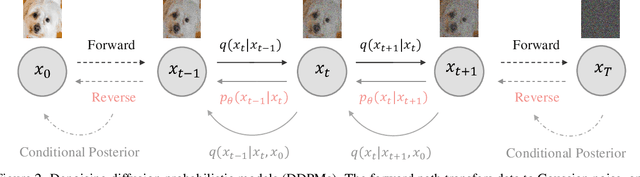
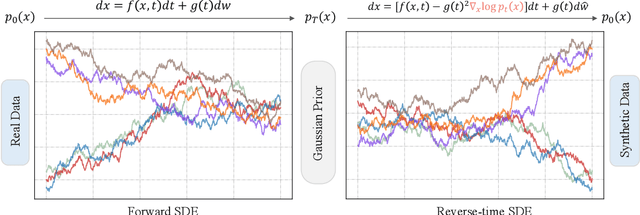
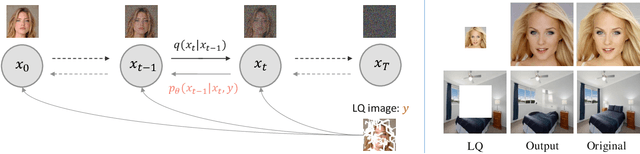
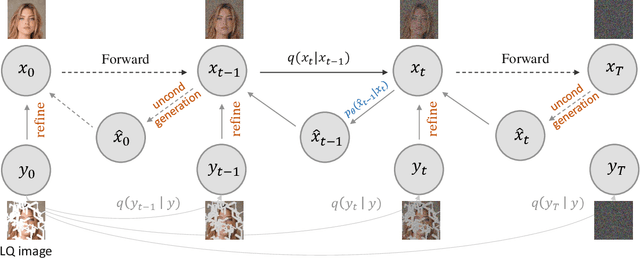
Diffusion models have achieved remarkable progress in generative modelling, particularly in enhancing image quality to conform to human preferences. Recently, these models have also been applied to low-level computer vision for photo-realistic image restoration (IR) in tasks such as image denoising, deblurring, dehazing, etc. In this review paper, we introduce key constructions in diffusion models and survey contemporary techniques that make use of diffusion models in solving general IR tasks. Furthermore, we point out the main challenges and limitations of existing diffusion-based IR frameworks and provide potential directions for future work.
Conditional sampling within generative diffusion models
Sep 15, 2024Generative diffusions are a powerful class of Monte Carlo samplers that leverage bridging Markov processes to approximate complex, high-dimensional distributions, such as those found in image processing and language models. Despite their success in these domains, an important open challenge remains: extending these techniques to sample from conditional distributions, as required in, for example, Bayesian inverse problems. In this paper, we present a comprehensive review of existing computational approaches to conditional sampling within generative diffusion models. Specifically, we highlight key methodologies that either utilise the joint distribution, or rely on (pre-trained) marginal distributions with explicit likelihoods, to construct conditional generative samplers.
Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models
Apr 15, 2024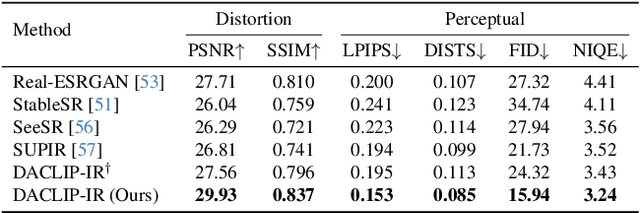

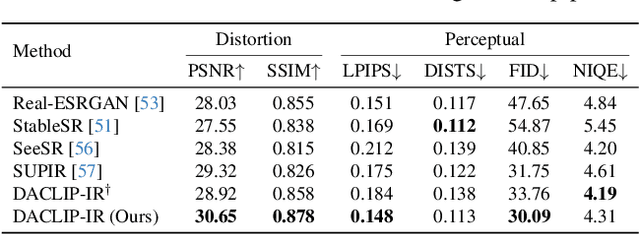

Though diffusion models have been successfully applied to various image restoration (IR) tasks, their performance is sensitive to the choice of training datasets. Typically, diffusion models trained in specific datasets fail to recover images that have out-of-distribution degradations. To address this problem, this work leverages a capable vision-language model and a synthetic degradation pipeline to learn image restoration in the wild (wild IR). More specifically, all low-quality images are simulated with a synthetic degradation pipeline that contains multiple common degradations such as blur, resize, noise, and JPEG compression. Then we introduce robust training for a degradation-aware CLIP model to extract enriched image content features to assist high-quality image restoration. Our base diffusion model is the image restoration SDE (IR-SDE). Built upon it, we further present a posterior sampling strategy for fast noise-free image generation. We evaluate our model on both synthetic and real-world degradation datasets. Moreover, experiments on the unified image restoration task illustrate that the proposed posterior sampling improves image generation quality for various degradations.
Equipping Diffusion Models with Differentiable Spatial Entropy for Low-Light Image Enhancement
Apr 15, 2024
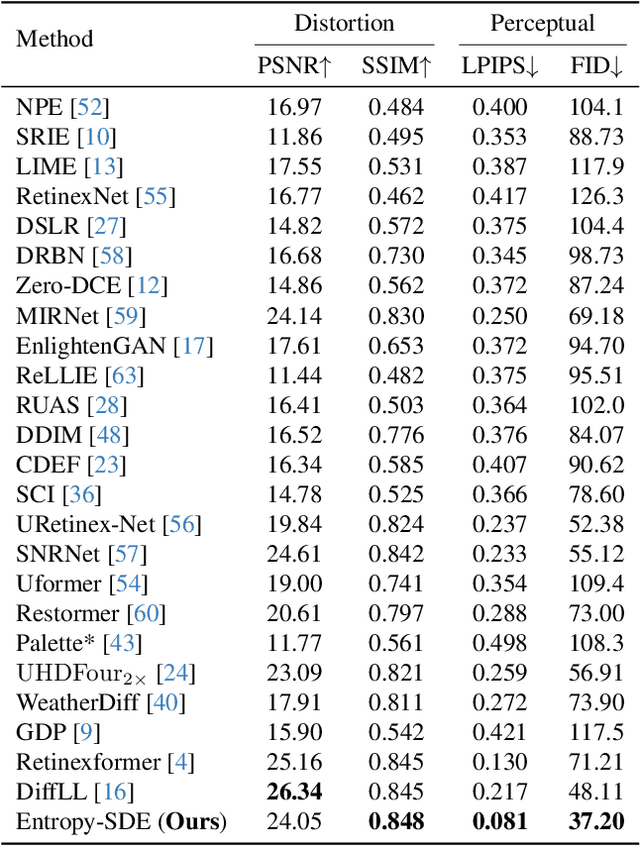


Image restoration, which aims to recover high-quality images from their corrupted counterparts, often faces the challenge of being an ill-posed problem that allows multiple solutions for a single input. However, most deep learning based works simply employ l1 loss to train their network in a deterministic way, resulting in over-smoothed predictions with inferior perceptual quality. In this work, we propose a novel method that shifts the focus from a deterministic pixel-by-pixel comparison to a statistical perspective, emphasizing the learning of distributions rather than individual pixel values. The core idea is to introduce spatial entropy into the loss function to measure the distribution difference between predictions and targets. To make this spatial entropy differentiable, we employ kernel density estimation (KDE) to approximate the probabilities for specific intensity values of each pixel with their neighbor areas. Specifically, we equip the entropy with diffusion models and aim for superior accuracy and enhanced perceptual quality over l1 based noise matching loss. In the experiments, we evaluate the proposed method for low light enhancement on two datasets and the NTIRE challenge 2024. All these results illustrate the effectiveness of our statistic-based entropy loss. Code is available at https://github.com/shermanlian/spatial-entropy-loss.
Entropy-regularized Diffusion Policy with Q-Ensembles for Offline Reinforcement Learning
Feb 06, 2024This paper presents advanced techniques of training diffusion policies for offline reinforcement learning (RL). At the core is a mean-reverting stochastic differential equation (SDE) that transfers a complex action distribution into a standard Gaussian and then samples actions conditioned on the environment state with a corresponding reverse-time SDE, like a typical diffusion policy. We show that such an SDE has a solution that we can use to calculate the log probability of the policy, yielding an entropy regularizer that improves the exploration of offline datasets. To mitigate the impact of inaccurate value functions from out-of-distribution data points, we further propose to learn the lower confidence bound of Q-ensembles for more robust policy improvement. By combining the entropy-regularized diffusion policy with Q-ensembles in offline RL, our method achieves state-of-the-art performance on most tasks in D4RL benchmarks. Code is available at \href{https://github.com/ruoqizzz/Entropy-Regularized-Diffusion-Policy-with-QEnsemble}{https://github.com/ruoqizzz/Entropy-Regularized-Diffusion-Policy-with-QEnsemble}.
Controlling Vision-Language Models for Universal Image Restoration
Oct 02, 2023



Vision-language models such as CLIP have shown great impact on diverse downstream tasks for zero-shot or label-free predictions. However, when it comes to low-level vision such as image restoration their performance deteriorates dramatically due to corrupted inputs. In this paper, we present a degradation-aware vision-language model (DA-CLIP) to better transfer pretrained vision-language models to low-level vision tasks as a universal framework for image restoration. More specifically, DA-CLIP trains an additional controller that adapts the fixed CLIP image encoder to predict high-quality feature embeddings. By integrating the embedding into an image restoration network via cross-attention, we are able to pilot the model to learn a high-fidelity image reconstruction. The controller itself will also output a degradation feature that matches the real corruptions of the input, yielding a natural classifier for different degradation types. In addition, we construct a mixed degradation dataset with synthetic captions for DA-CLIP training. Our approach advances state-of-the-art performance on both degradation-specific and unified image restoration tasks, showing a promising direction of prompting image restoration with large-scale pretrained vision-language models. Our code is available at https://github.com/Algolzw/daclip-uir.
Deep Reinforcement Learning for Image-to-Image Translation
Sep 24, 2023



Most existing Image-to-Image Translation (I2IT) methods generate images in a single run of a deep learning (DL) model. However, designing such a single-step model is always challenging, requiring a huge number of parameters and easily falling into bad global minimums and overfitting. In this work, we reformulate I2IT as a step-wise decision-making problem via deep reinforcement learning (DRL) and propose a novel framework that performs RL-based I2IT (RL-I2IT). The key feature in the RL-I2IT framework is to decompose a monolithic learning process into small steps with a lightweight model to progressively transform a source image successively to a target image. Considering that it is challenging to handle high dimensional continuous state and action spaces in the conventional RL framework, we introduce meta policy with a new concept Plan to the standard Actor-Critic model, which is of a lower dimension than the original image and can facilitate the actor to generate a tractable high dimensional action. In the RL-I2IT framework, we also employ a task-specific auxiliary learning strategy to stabilize the training process and improve the performance of the corresponding task. Experiments on several I2IT tasks demonstrate the effectiveness and robustness of the proposed method when facing high-dimensional continuous action space problems.
Refusion: Enabling Large-Size Realistic Image Restoration with Latent-Space Diffusion Models
Apr 17, 2023This work aims to improve the applicability of diffusion models in realistic image restoration. Specifically, we enhance the diffusion model in several aspects such as network architecture, noise level, denoising steps, training image size, and optimizer/scheduler. We show that tuning these hyperparameters allows us to achieve better performance on both distortion and perceptual scores. We also propose a U-Net based latent diffusion model which performs diffusion in a low-resolution latent space while preserving high-resolution information from the original input for the decoding process. Compared to the previous latent-diffusion model which trains a VAE-GAN to compress the image, our proposed U-Net compression strategy is significantly more stable and can recover highly accurate images without relying on adversarial optimization. Importantly, these modifications allow us to apply diffusion models to various image restoration tasks, including real-world shadow removal, HR non-homogeneous dehazing, stereo super-resolution, and bokeh effect transformation. By simply replacing the datasets and slightly changing the noise network, our model, named Refusion, is able to deal with large-size images (e.g., 6000 x 4000 x 3 in HR dehazing) and produces good results on all the above restoration problems. Our Refusion achieves the best perceptual performance in the NTIRE 2023 Image Shadow Removal Challenge and wins 2nd place overall.