 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObservation-dependent Bayesian active learning via input-warped Gaussian processes
Feb 02, 2026Bayesian active learning relies on the precise quantification of predictive uncertainty to explore unknown function landscapes. While Gaussian process surrogates are the standard for such tasks, an underappreciated fact is that their posterior variance depends on the observed outputs only through the hyperparameters, rendering exploration largely insensitive to the actual measurements. We propose to inject observation-dependent feedback by warping the input space with a learned, monotone reparameterization. This mechanism allows the design policy to expand or compress regions of the input space in response to observed variability, thereby shaping the behavior of variance-based acquisition functions. We demonstrate that while such warps can be trained via marginal likelihood, a novel self-supervised objective yields substantially better performance. Our approach improves sample efficiency across a range of active learning benchmarks, particularly in regimes where non-stationarity challenges traditional methods.
Warm-starting active-set solvers using graph neural networks
Nov 17, 2025



Quadratic programming (QP) solvers are widely used in real-time control and optimization, but their computational cost often limits applicability in time-critical settings. We propose a learning-to-optimize approach using graph neural networks (GNNs) to predict active sets in the dual active-set solver DAQP. The method exploits the structural properties of QPs by representing them as bipartite graphs and learning to identify the optimal active set for efficiently warm-starting the solver. Across varying problem sizes, the GNN consistently reduces the number of solver iterations compared to cold-starting, while performance is comparable to a multilayer perceptron (MLP) baseline. Furthermore, a GNN trained on varying problem sizes generalizes effectively to unseen dimensions, demonstrating flexibility and scalability. These results highlight the potential of structure-aware learning to accelerate optimization in real-time applications such as model predictive control.
Learning to accelerate distributed ADMM using graph neural networks
Sep 05, 2025


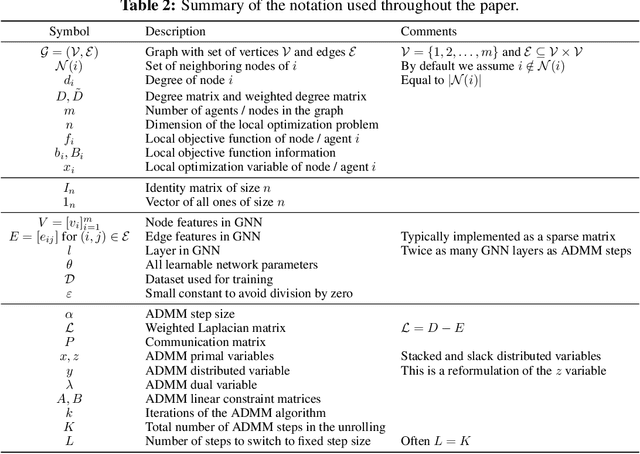
Distributed optimization is fundamental in large-scale machine learning and control applications. Among existing methods, the Alternating Direction Method of Multipliers (ADMM) has gained popularity due to its strong convergence guarantees and suitability for decentralized computation. However, ADMM often suffers from slow convergence and sensitivity to hyperparameter choices. In this work, we show that distributed ADMM iterations can be naturally represented within the message-passing framework of graph neural networks (GNNs). Building on this connection, we propose to learn adaptive step sizes and communication weights by a graph neural network that predicts the hyperparameters based on the iterates. By unrolling ADMM for a fixed number of iterations, we train the network parameters end-to-end to minimize the final iterates error for a given problem class, while preserving the algorithm's convergence properties. Numerical experiments demonstrate that our learned variant consistently improves convergence speed and solution quality compared to standard ADMM. The code is available at https://github.com/paulhausner/learning-distributed-admm.
Machine learning for in-situ composition mapping in a self-driving magnetron sputtering system
Jun 06, 2025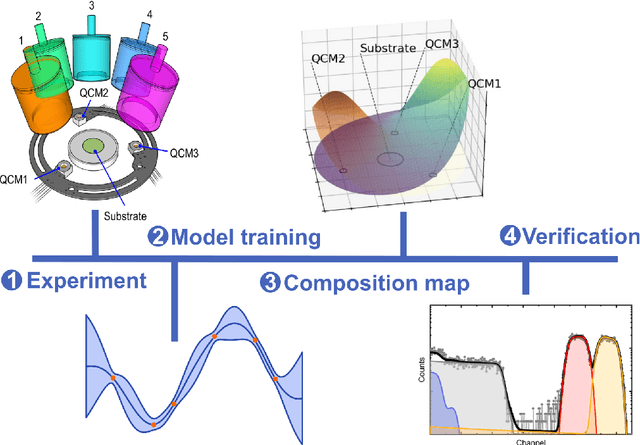



Self-driving labs (SDLs), employing automation and machine learning (ML) to accelerate experimental procedures, have enormous potential in the discovery of new materials. However, in thin film science, SDLs are mainly restricted to solution-based synthetic methods which are easier to automate but cannot access the broad chemical space of inorganic materials. This work presents an SDL based on magnetron co-sputtering. We are using combinatorial frameworks, obtaining accurate composition maps on multi-element, compositionally graded thin films. This normally requires time-consuming ex-situ analysis prone to systematic errors. We present a rapid and calibration-free in-situ, ML driven approach to produce composition maps for arbitrary source combinations and sputtering conditions. We develop a method to predict the composition distribution in a multi-element combinatorial thin film, using in-situ measurements from quartz-crystal microbalance sensors placed in a sputter chamber. For a given source, the sensor readings are learned as a function of the sputtering pressure and magnetron power, through active learning using Gaussian processes (GPs). The final GPs are combined with a geometric model of the deposition flux distribution in the chamber, which allows interpolation of the deposition rates from each source, at any position across the sample. We investigate several acquisition functions for the ML procedure. A fully Bayesian GP - BALM (Bayesian active learning MacKay) - achieved the best performance, learning the deposition rates for a single source in 10 experiments. Prediction accuracy for co-sputtering composition distributions was verified experimentally. Our framework dramatically increases throughput by avoiding the need for extensive characterisation or calibration, thus demonstrating the potential of ML-guided SDLs to accelerate materials exploration.
Forward-only Diffusion Probabilistic Models
May 22, 2025This work presents a forward-only diffusion (FoD) approach for generative modelling. In contrast to traditional diffusion models that rely on a coupled forward-backward diffusion scheme, FoD directly learns data generation through a single forward diffusion process, yielding a simple yet efficient generative framework. The core of FoD is a state-dependent linear stochastic differential equation that involves a mean-reverting term in both the drift and diffusion functions. This mean-reversion property guarantees the convergence to clean data, naturally simulating a stochastic interpolation between source and target distributions. More importantly, FoD is analytically tractable and is trained using a simple stochastic flow matching objective, enabling a few-step non-Markov chain sampling during inference. The proposed FoD model, despite its simplicity, achieves competitive performance on various image-conditioned (e.g., image restoration) and unconditional generation tasks, demonstrating its effectiveness in generative modelling. Our code is available at https://github.com/Algolzw/FoD.
Towards Better Sample Efficiency in Multi-Agent Reinforcement Learning via Exploration
Mar 17, 2025Multi-agent reinforcement learning has shown promise in learning cooperative behaviors in team-based environments. However, such methods often demand extensive training time. For instance, the state-of-the-art method TiZero takes 40 days to train high-quality policies for a football environment. In this paper, we hypothesize that better exploration mechanisms can improve the sample efficiency of multi-agent methods. We propose two different approaches for better exploration in TiZero: a self-supervised intrinsic reward and a random network distillation bonus. Additionally, we introduce architectural modifications to the original algorithm to enhance TiZero's computational efficiency. We evaluate the sample efficiency of these approaches through extensive experiments. Our results show that random network distillation improves training sample efficiency by 18.8% compared to the original TiZero. Furthermore, we evaluate the qualitative behavior of the models produced by both variants against a heuristic AI, with the self-supervised reward encouraging possession and random network distillation leading to a more offensive performance. Our results highlights the applicability of our random network distillation variant in practical settings. Lastly, due to the nature of the proposed method, we acknowledge its use beyond football simulation, especially in environments with strong multi-agent and strategic aspects.
Online learning in motion modeling for intra-interventional image sequences
Oct 15, 2024Image monitoring and guidance during medical examinations can aid both diagnosis and treatment. However, the sampling frequency is often too low, which creates a need to estimate the missing images. We present a probabilistic motion model for sequential medical images, with the ability to both estimate motion between acquired images and forecast the motion ahead of time. The core is a low-dimensional temporal process based on a linear Gaussian state-space model with analytically tractable solutions for forecasting, simulation, and imputation of missing samples. The results, from two experiments on publicly available cardiac datasets, show reliable motion estimates and an improved forecasting performance using patient-specific adaptation by online learning.
Taming Diffusion Models for Image Restoration: A Review
Sep 16, 2024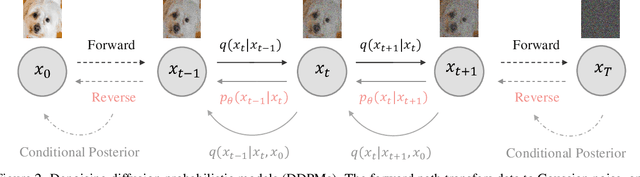
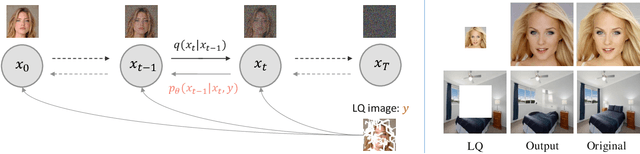
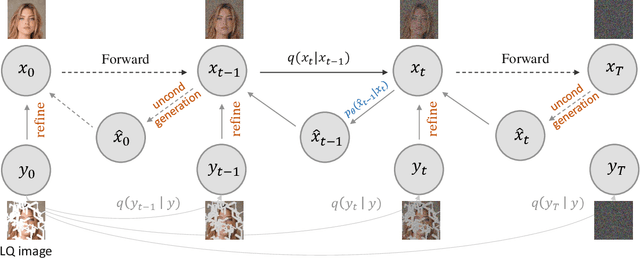
Diffusion models have achieved remarkable progress in generative modelling, particularly in enhancing image quality to conform to human preferences. Recently, these models have also been applied to low-level computer vision for photo-realistic image restoration (IR) in tasks such as image denoising, deblurring, dehazing, etc. In this review paper, we introduce key constructions in diffusion models and survey contemporary techniques that make use of diffusion models in solving general IR tasks. Furthermore, we point out the main challenges and limitations of existing diffusion-based IR frameworks and provide potential directions for future work.
Conditional sampling within generative diffusion models
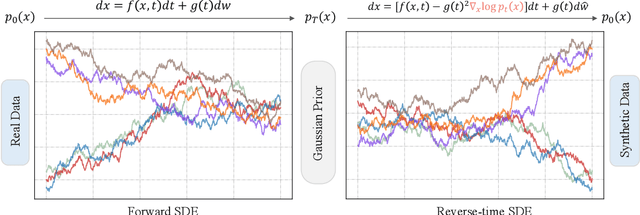
Sep 15, 2024Generative diffusions are a powerful class of Monte Carlo samplers that leverage bridging Markov processes to approximate complex, high-dimensional distributions, such as those found in image processing and language models. Despite their success in these domains, an important open challenge remains: extending these techniques to sample from conditional distributions, as required in, for example, Bayesian inverse problems. In this paper, we present a comprehensive review of existing computational approaches to conditional sampling within generative diffusion models. Specifically, we highlight key methodologies that either utilise the joint distribution, or rely on (pre-trained) marginal distributions with explicit likelihoods, to construct conditional generative samplers.
Learning incomplete factorization preconditioners for GMRES
Sep 12, 2024In this paper, we develop a data-driven approach to generate incomplete LU factorizations of large-scale sparse matrices. The learned approximate factorization is utilized as a preconditioner for the corresponding linear equation system in the GMRES method. Incomplete factorization methods are one of the most commonly applied algebraic preconditioners for sparse linear equation systems and are able to speed up the convergence of Krylov subspace methods. However, they are sensitive to hyper-parameters and might suffer from numerical breakdown or lead to slow convergence when not properly applied. We replace the typically hand-engineered algorithms with a graph neural network based approach that is trained against data to predict an approximate factorization. This allows us to learn preconditioners tailored for a specific problem distribution. We analyze and empirically evaluate different loss functions to train the learned preconditioners and show their effectiveness to decrease the number of GMRES iterations and improve the spectral properties on our synthetic dataset. The code is available at https://github.com/paulhausner/neural-incomplete-factorization.