 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Sample Efficiency in Multi-Agent Reinforcement Learning via Exploration
Mar 17, 2025Multi-agent reinforcement learning has shown promise in learning cooperative behaviors in team-based environments. However, such methods often demand extensive training time. For instance, the state-of-the-art method TiZero takes 40 days to train high-quality policies for a football environment. In this paper, we hypothesize that better exploration mechanisms can improve the sample efficiency of multi-agent methods. We propose two different approaches for better exploration in TiZero: a self-supervised intrinsic reward and a random network distillation bonus. Additionally, we introduce architectural modifications to the original algorithm to enhance TiZero's computational efficiency. We evaluate the sample efficiency of these approaches through extensive experiments. Our results show that random network distillation improves training sample efficiency by 18.8% compared to the original TiZero. Furthermore, we evaluate the qualitative behavior of the models produced by both variants against a heuristic AI, with the self-supervised reward encouraging possession and random network distillation leading to a more offensive performance. Our results highlights the applicability of our random network distillation variant in practical settings. Lastly, due to the nature of the proposed method, we acknowledge its use beyond football simulation, especially in environments with strong multi-agent and strategic aspects.
Improving Conditional Level Generation using Automated Validation in Match-3 Games
Sep 10, 2024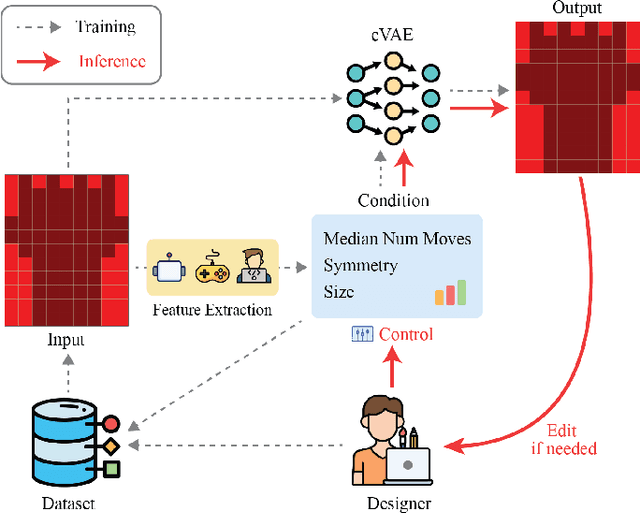

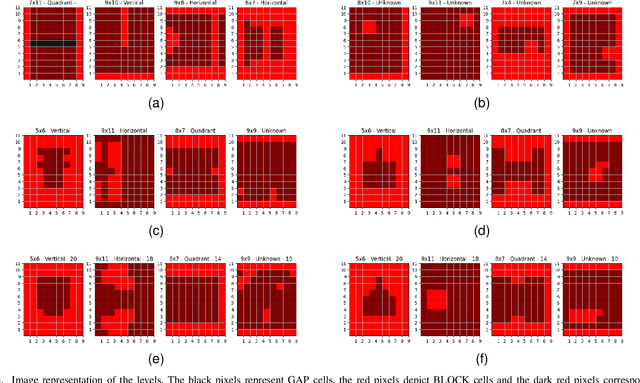
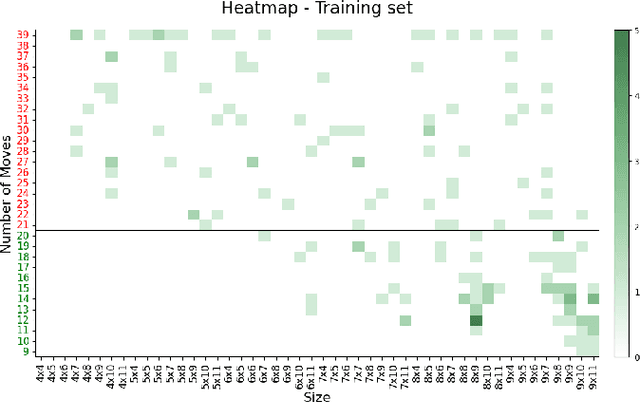
Generative models for level generation have shown great potential in game production. However, they often provide limited control over the generation, and the validity of the generated levels is unreliable. Despite this fact, only a few approaches that learn from existing data provide the users with ways of controlling the generation, simultaneously addressing the generation of unsolvable levels. %One of the main challenges it faces is that levels generated through automation may not be solvable thus requiring validation. are not always engaging, challenging, or even solvable. This paper proposes Avalon, a novel method to improve models that learn from existing level designs using difficulty statistics extracted from gameplay. In particular, we use a conditional variational autoencoder to generate layouts for match-3 levels, conditioning the model on pre-collected statistics such as game mechanics like difficulty and relevant visual features like size and symmetry. Our method is general enough that multiple approaches could potentially be used to generate these statistics. We quantitatively evaluate our approach by comparing it to an ablated model without difficulty conditioning. Additionally, we analyze both quantitatively and qualitatively whether the style of the dataset is preserved in the generated levels. Our approach generates more valid levels than the same method without difficulty conditioning.
* 10 pages, 5 figures, 2 tables
Reinforcement Learning for High-Level Strategic Control in Tower Defense Games
Jun 12, 2024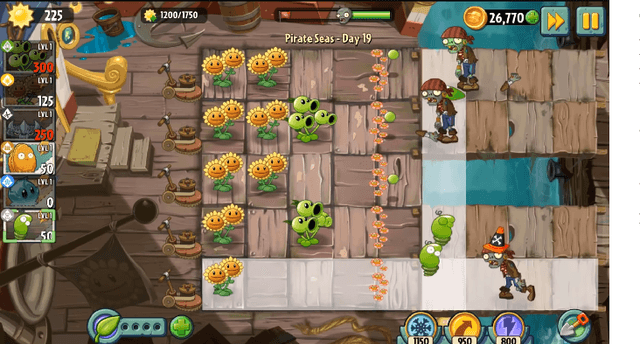
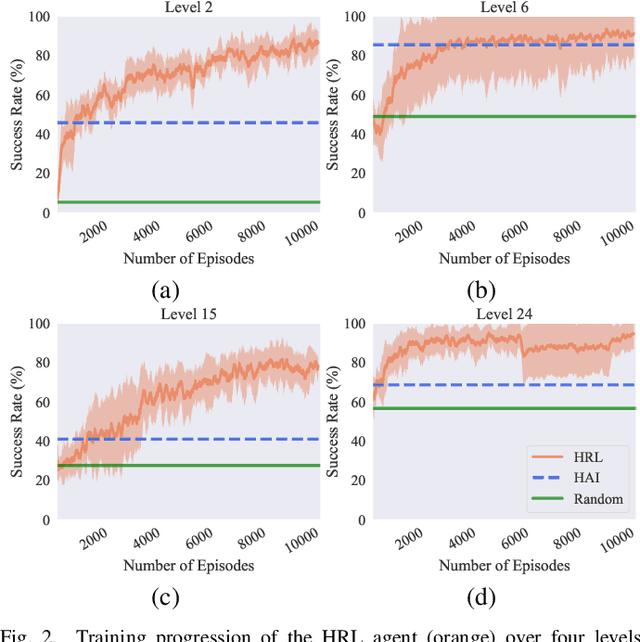
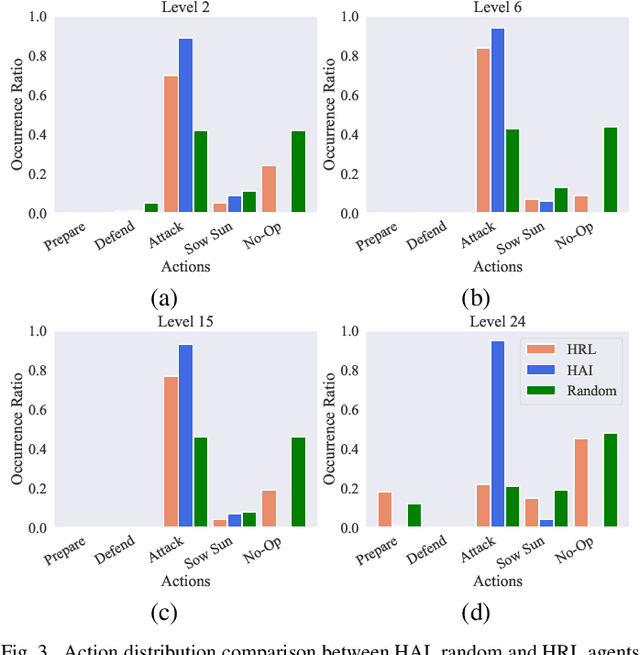
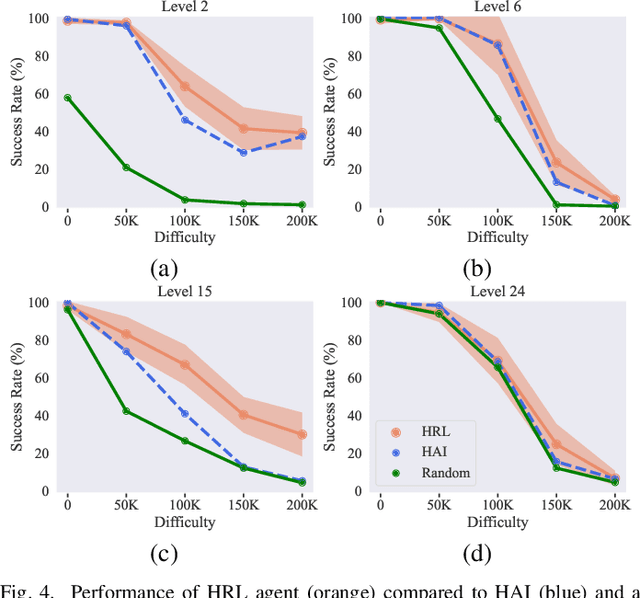
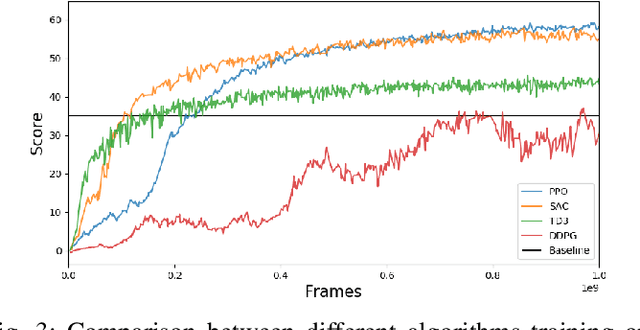
In strategy games, one of the most important aspects of game design is maintaining a sense of challenge for players. Many mobile titles feature quick gameplay loops that allow players to progress steadily, requiring an abundance of levels and puzzles to prevent them from reaching the end too quickly. As with any content creation, testing and validation are essential to ensure engaging gameplay mechanics, enjoyable game assets, and playable levels. In this paper, we propose an automated approach that can be leveraged for gameplay testing and validation that combines traditional scripted methods with reinforcement learning, reaping the benefits of both approaches while adapting to new situations similarly to how a human player would. We test our solution on a popular tower defense game, Plants vs. Zombies. The results show that combining a learned approach, such as reinforcement learning, with a scripted AI produces a higher-performing and more robust agent than using only heuristic AI, achieving a 57.12% success rate compared to 47.95% in a set of 40 levels. Moreover, the results demonstrate the difficulty of training a general agent for this type of puzzle-like game.
Technical Challenges of Deploying Reinforcement Learning Agents for Game Testing in AAA Games
Jul 19, 2023



Going from research to production, especially for large and complex software systems, is fundamentally a hard problem. In large-scale game production, one of the main reasons is that the development environment can be very different from the final product. In this technical paper we describe an effort to add an experimental reinforcement learning system to an existing automated game testing solution based on scripted bots in order to increase its capacity. We report on how this reinforcement learning system was integrated with the aim to increase test coverage similar to [1] in a set of AAA games including Battlefield 2042 and Dead Space (2023). The aim of this technical paper is to show a use-case of leveraging reinforcement learning in game production and cover some of the largest time sinks anyone who wants to make the same journey for their game may encounter. Furthermore, to help the game industry to adopt this technology faster, we propose a few research directions that we believe will be valuable and necessary for making machine learning, and especially reinforcement learning, an effective tool in game production.
Towards Informed Design and Validation Assistance in Computer Games Using Imitation Learning
Aug 19, 2022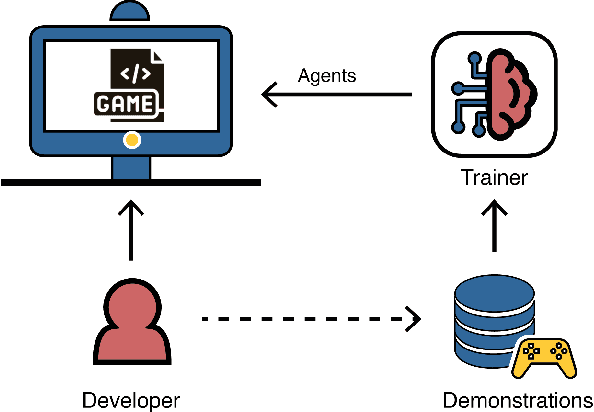

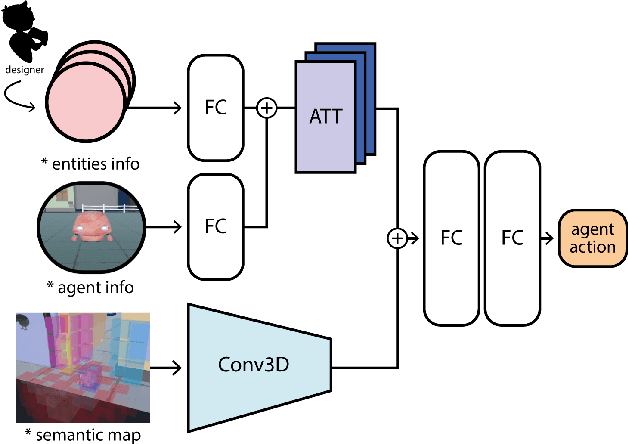
In games, as in and many other domains, design validation and testing is a huge challenge as systems are growing in size and manual testing is becoming infeasible. This paper proposes a new approach to automated game validation and testing. Our method leverages a data-driven imitation learning technique, which requires little effort and time and no knowledge of machine learning or programming, that designers can use to efficiently train game testing agents. We investigate the validity of our approach through a user study with industry experts. The survey results show that our method is indeed a valid approach to game validation and that data-driven programming would be a useful aid to reducing effort and increasing quality of modern playtesting. The survey also highlights several open challenges. With the help of the most recent literature, we analyze the identified challenges and propose future research directions suitable for supporting and maximizing the utility of our approach.
CCPT: Automatic Gameplay Testing and Validation with Curiosity-Conditioned Proximal Trajectories
Feb 21, 2022



This paper proposes a novel deep reinforcement learning algorithm to perform automatic analysis and detection of gameplay issues in complex 3D navigation environments. The Curiosity-Conditioned Proximal Trajectories (CCPT) method combines curiosity and imitation learning to train agents to methodically explore in the proximity of known trajectories derived from expert demonstrations. We show how CCPT can explore complex environments, discover gameplay issues and design oversights in the process, and recognize and highlight them directly to game designers. We further demonstrate the effectiveness of the algorithm in a novel 3D navigation environment which reflects the complexity of modern AAA video games. Our results show a higher level of coverage and bug discovery than baselines methods, and it hence can provide a valuable tool for game designers to identify issues in game design automatically.
Augmenting Automated Game Testing with Deep Reinforcement Learning
Mar 29, 2021


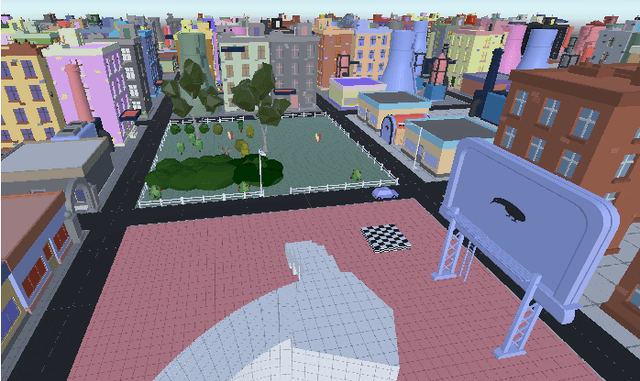
General game testing relies on the use of human play testers, play test scripting, and prior knowledge of areas of interest to produce relevant test data. Using deep reinforcement learning (DRL), we introduce a self-learning mechanism to the game testing framework. With DRL, the framework is capable of exploring and/or exploiting the game mechanics based on a user-defined, reinforcing reward signal. As a result, test coverage is increased and unintended game play mechanics, exploits and bugs are discovered in a multitude of game types. In this paper, we show that DRL can be used to increase test coverage, find exploits, test map difficulty, and to detect common problems that arise in the testing of first-person shooter (FPS) games.
* 4 pages, 6 figures, 2020 IEEE Conference on Games (CoG), 600-603
Improving Playtesting Coverage via Curiosity Driven Reinforcement Learning Agents
Mar 25, 2021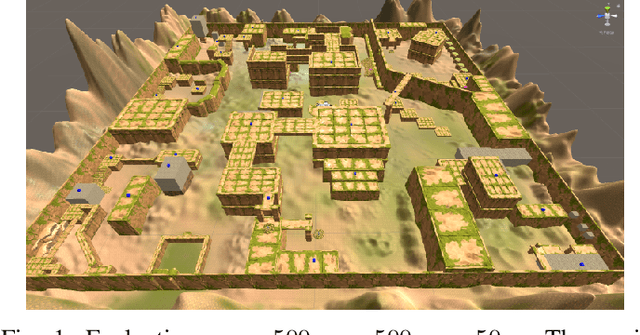


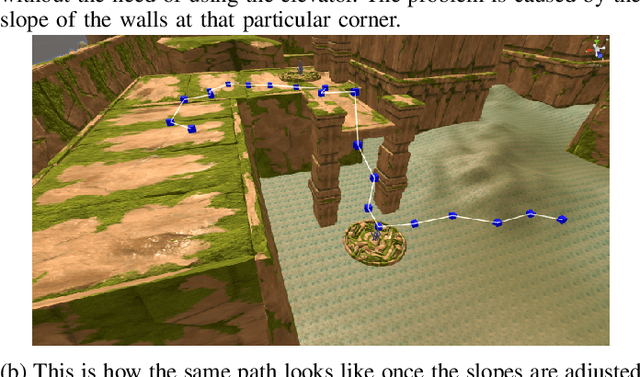
As modern games continue growing both in size and complexity, it has become more challenging to ensure that all the relevant content is tested and that any potential issue is properly identified and fixed. Attempting to maximize testing coverage using only human participants, however, results in a tedious and hard to orchestrate process which normally slows down the development cycle. Complementing playtesting via autonomous agents has shown great promise accelerating and simplifying this process. This paper addresses the problem of automatically exploring and testing a given scenario using reinforcement learning agents trained to maximize game state coverage. Each of these agents is rewarded based on the novelty of its actions, thus encouraging a curious and exploratory behaviour on a complex 3D scenario where previously proposed exploration techniques perform poorly. The curious agents are able to learn the complex navigation mechanics required to reach the different areas around the map, thus providing the necessary data to identify potential issues. Moreover, the paper also explores different visualization strategies and evaluates how to make better use of the collected data to drive design decisions and to recognize possible problems and oversights.
Adversarial Reinforcement Learning for Procedural Content Generation
Mar 08, 2021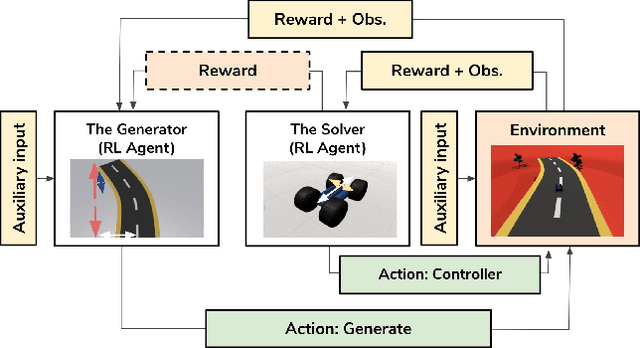
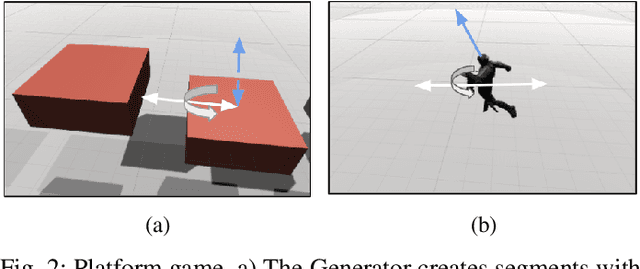


We present an approach for procedural content generation (PCG), and improving generalization in reinforcement learning (RL) agents, by using adversarial deep RL. Training RL agents for generalization over novel environments is a notoriously difficult task. One popular approach is to procedurally generate different environments to increase the generalizability of the trained agents. Here we deploy an adversarial model with one PCG RL agent (called Generator), and one solving RL agent (called Solver). The benefit is mainly two-fold: Firstly, the Solver achieves better generalization through the generated challenges from the Generator. Secondly, the trained Generator can be used as a creator of novel environments that, together with the Solver, can be shown to be solvable. The Generator receives a reward signal based on the performance of the Solver which encourages the environment design to be challenging but not impossible. To further drive diversity and control of the environment generation, we propose the use of auxiliary inputs for the Generator. Thus, we propose adversarial RL for procedural content generation (ARLPCG), an adversarial approach which procedurally generates previously unseen environments with an auxiliary input as a control variable. Herein we describe this concept in detail and compare it with previous methods showing improved generalization, as well as a new method to create novel environments.
Imitation Learning with Concurrent Actions in 3D Games
Sep 06, 2018

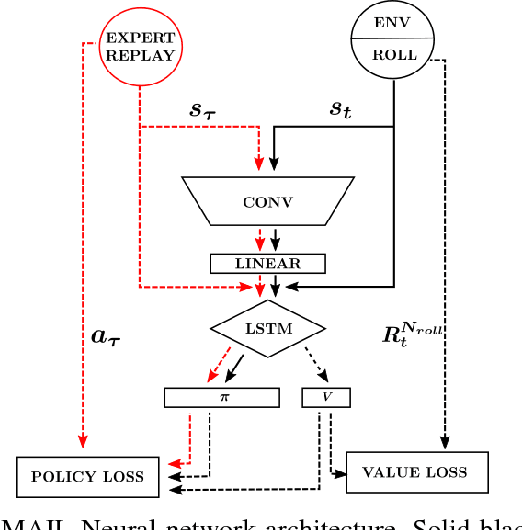

In this work we describe a novel deep reinforcement learning architecture that allows multiple actions to be selected at every time-step in an efficient manner. Multi-action policies allow complex behaviours to be learnt that would otherwise be hard to achieve when using single action selection techniques. We use both imitation learning and temporal difference (TD) reinforcement learning (RL) to provide a 4x improvement in training time and 2.5x improvement in performance over single action selection TD RL. We demonstrate the capabilities of this network using a complex in-house 3D game. Mimicking the behavior of the expert teacher significantly improves world state exploration and allows the agents vision system to be trained more rapidly than TD RL alone. This initial training technique kick-starts TD learning and the agent quickly learns to surpass the capabilities of the expert.