 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Reinforcement Learning for Procedural Content Generation
Paper and Code
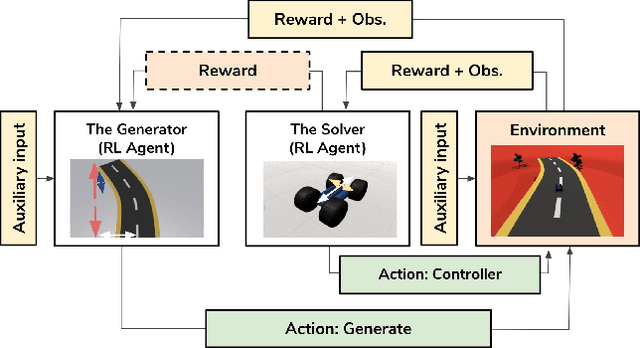
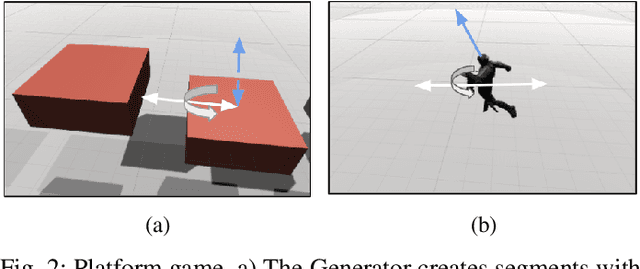


We present an approach for procedural content generation (PCG), and improving generalization in reinforcement learning (RL) agents, by using adversarial deep RL. Training RL agents for generalization over novel environments is a notoriously difficult task. One popular approach is to procedurally generate different environments to increase the generalizability of the trained agents. Here we deploy an adversarial model with one PCG RL agent (called Generator), and one solving RL agent (called Solver). The benefit is mainly two-fold: Firstly, the Solver achieves better generalization through the generated challenges from the Generator. Secondly, the trained Generator can be used as a creator of novel environments that, together with the Solver, can be shown to be solvable. The Generator receives a reward signal based on the performance of the Solver which encourages the environment design to be challenging but not impossible. To further drive diversity and control of the environment generation, we propose the use of auxiliary inputs for the Generator. Thus, we propose adversarial RL for procedural content generation (ARLPCG), an adversarial approach which procedurally generates previously unseen environments with an auxiliary input as a control variable. Herein we describe this concept in detail and compare it with previous methods showing improved generalization, as well as a new method to create novel environments.