 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Automated Game Testing with Deep Reinforcement Learning
Mar 29, 2021

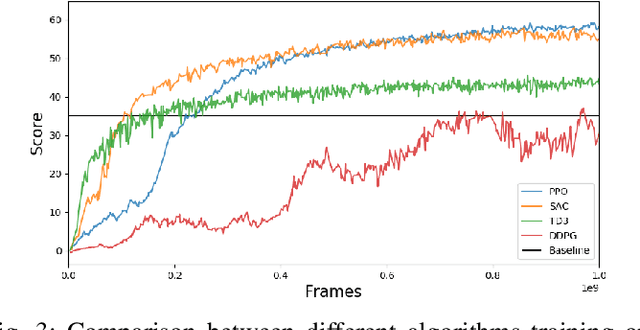

General game testing relies on the use of human play testers, play test scripting, and prior knowledge of areas of interest to produce relevant test data. Using deep reinforcement learning (DRL), we introduce a self-learning mechanism to the game testing framework. With DRL, the framework is capable of exploring and/or exploiting the game mechanics based on a user-defined, reinforcing reward signal. As a result, test coverage is increased and unintended game play mechanics, exploits and bugs are discovered in a multitude of game types. In this paper, we show that DRL can be used to increase test coverage, find exploits, test map difficulty, and to detect common problems that arise in the testing of first-person shooter (FPS) games.
* 4 pages, 6 figures, 2020 IEEE Conference on Games (CoG), 600-603
Improving Playtesting Coverage via Curiosity Driven Reinforcement Learning Agents
Mar 25, 2021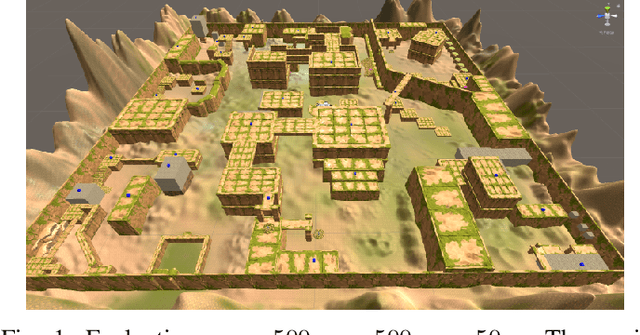


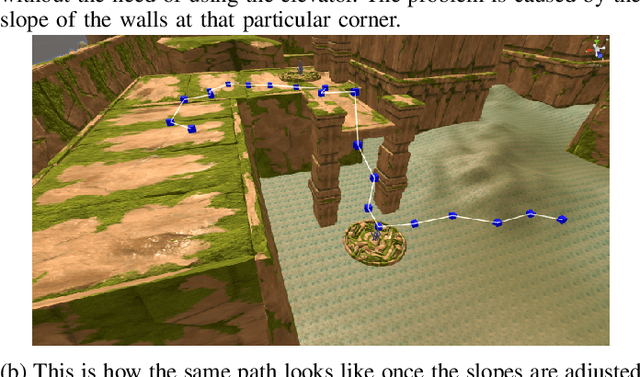
As modern games continue growing both in size and complexity, it has become more challenging to ensure that all the relevant content is tested and that any potential issue is properly identified and fixed. Attempting to maximize testing coverage using only human participants, however, results in a tedious and hard to orchestrate process which normally slows down the development cycle. Complementing playtesting via autonomous agents has shown great promise accelerating and simplifying this process. This paper addresses the problem of automatically exploring and testing a given scenario using reinforcement learning agents trained to maximize game state coverage. Each of these agents is rewarded based on the novelty of its actions, thus encouraging a curious and exploratory behaviour on a complex 3D scenario where previously proposed exploration techniques perform poorly. The curious agents are able to learn the complex navigation mechanics required to reach the different areas around the map, thus providing the necessary data to identify potential issues. Moreover, the paper also explores different visualization strategies and evaluates how to make better use of the collected data to drive design decisions and to recognize possible problems and oversights.
Adversarial Reinforcement Learning for Procedural Content Generation
Mar 08, 2021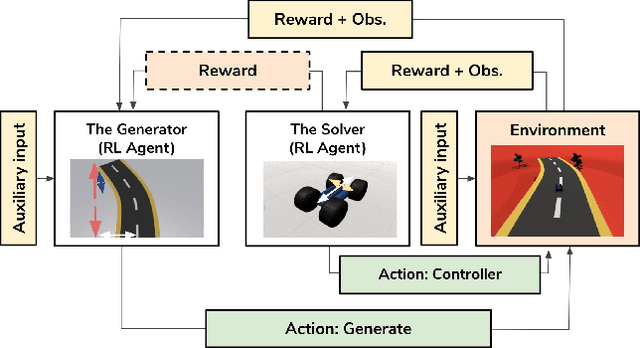
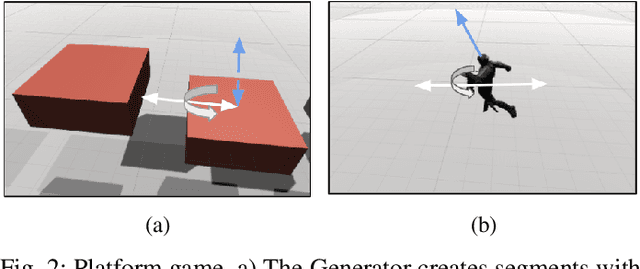


We present an approach for procedural content generation (PCG), and improving generalization in reinforcement learning (RL) agents, by using adversarial deep RL. Training RL agents for generalization over novel environments is a notoriously difficult task. One popular approach is to procedurally generate different environments to increase the generalizability of the trained agents. Here we deploy an adversarial model with one PCG RL agent (called Generator), and one solving RL agent (called Solver). The benefit is mainly two-fold: Firstly, the Solver achieves better generalization through the generated challenges from the Generator. Secondly, the trained Generator can be used as a creator of novel environments that, together with the Solver, can be shown to be solvable. The Generator receives a reward signal based on the performance of the Solver which encourages the environment design to be challenging but not impossible. To further drive diversity and control of the environment generation, we propose the use of auxiliary inputs for the Generator. Thus, we propose adversarial RL for procedural content generation (ARLPCG), an adversarial approach which procedurally generates previously unseen environments with an auxiliary input as a control variable. Herein we describe this concept in detail and compare it with previous methods showing improved generalization, as well as a new method to create novel environments.