 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Sample Efficiency in Multi-Agent Reinforcement Learning via Exploration
Mar 17, 2025Multi-agent reinforcement learning has shown promise in learning cooperative behaviors in team-based environments. However, such methods often demand extensive training time. For instance, the state-of-the-art method TiZero takes 40 days to train high-quality policies for a football environment. In this paper, we hypothesize that better exploration mechanisms can improve the sample efficiency of multi-agent methods. We propose two different approaches for better exploration in TiZero: a self-supervised intrinsic reward and a random network distillation bonus. Additionally, we introduce architectural modifications to the original algorithm to enhance TiZero's computational efficiency. We evaluate the sample efficiency of these approaches through extensive experiments. Our results show that random network distillation improves training sample efficiency by 18.8% compared to the original TiZero. Furthermore, we evaluate the qualitative behavior of the models produced by both variants against a heuristic AI, with the self-supervised reward encouraging possession and random network distillation leading to a more offensive performance. Our results highlights the applicability of our random network distillation variant in practical settings. Lastly, due to the nature of the proposed method, we acknowledge its use beyond football simulation, especially in environments with strong multi-agent and strategic aspects.
SPEQ: Stabilization Phases for Efficient Q-Learning in High Update-To-Data Ratio Reinforcement Learning
Jan 15, 2025A key challenge in Deep Reinforcement Learning is sample efficiency, especially in real-world applications where collecting environment interactions is expensive or risky. Recent off-policy algorithms improve sample efficiency by increasing the Update-To-Data (UTD) ratio and performing more gradient updates per environment interaction. While this improves sample efficiency, it significantly increases computational cost due to the higher number of gradient updates required. In this paper we propose a sample-efficient method to improve computational efficiency by separating training into distinct learning phases in order to exploit gradient updates more effectively. Our approach builds on top of the Dropout Q-Functions (DroQ) algorithm and alternates between an online, low UTD ratio training phase, and an offline stabilization phase. During the stabilization phase, we fine-tune the Q-functions without collecting new environment interactions. This process improves the effectiveness of the replay buffer and reduces computational overhead. Our experimental results on continuous control problems show that our method achieves results comparable to state-of-the-art, high UTD ratio algorithms while requiring 56\% fewer gradient updates and 50\% less training time than DroQ. Our approach offers an effective and computationally economical solution while maintaining the same sample efficiency as the more costly, high UTD ratio state-of-the-art.
Improving Conditional Level Generation using Automated Validation in Match-3 Games
Sep 10, 2024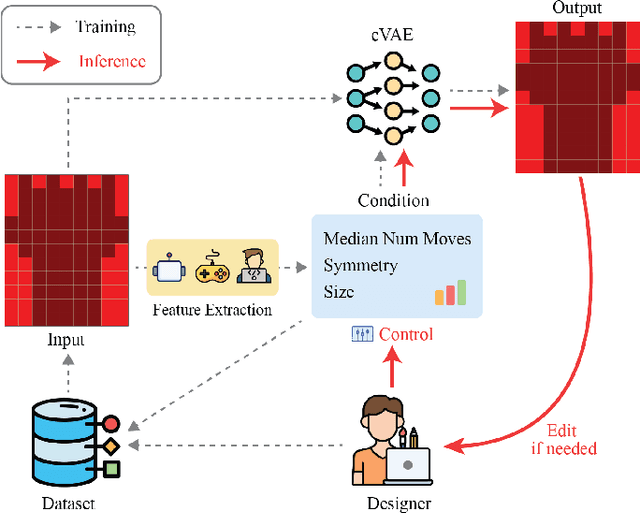

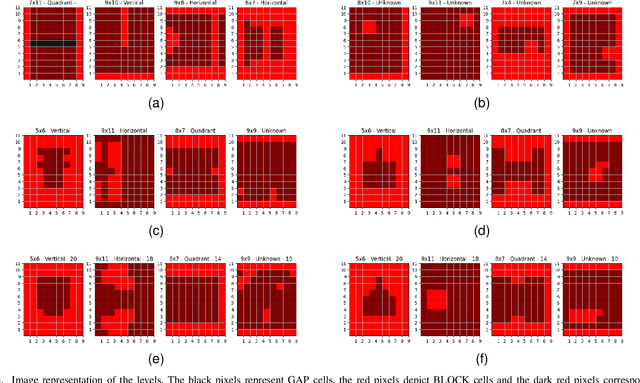
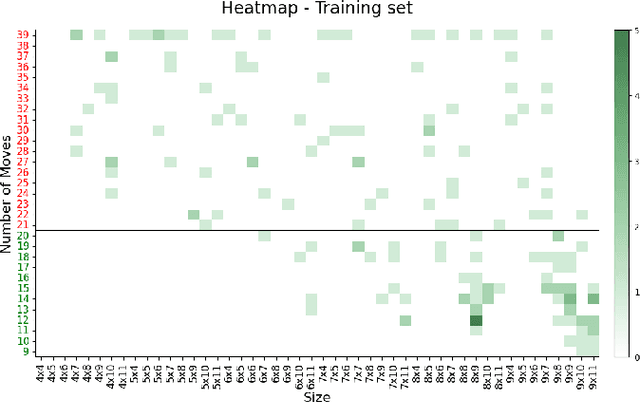
Generative models for level generation have shown great potential in game production. However, they often provide limited control over the generation, and the validity of the generated levels is unreliable. Despite this fact, only a few approaches that learn from existing data provide the users with ways of controlling the generation, simultaneously addressing the generation of unsolvable levels. %One of the main challenges it faces is that levels generated through automation may not be solvable thus requiring validation. are not always engaging, challenging, or even solvable. This paper proposes Avalon, a novel method to improve models that learn from existing level designs using difficulty statistics extracted from gameplay. In particular, we use a conditional variational autoencoder to generate layouts for match-3 levels, conditioning the model on pre-collected statistics such as game mechanics like difficulty and relevant visual features like size and symmetry. Our method is general enough that multiple approaches could potentially be used to generate these statistics. We quantitatively evaluate our approach by comparing it to an ablated model without difficulty conditioning. Additionally, we analyze both quantitatively and qualitatively whether the style of the dataset is preserved in the generated levels. Our approach generates more valid levels than the same method without difficulty conditioning.
* 10 pages, 5 figures, 2 tables
A Benchmark Environment for Offline Reinforcement Learning in Racing Games
Jul 12, 2024Offline Reinforcement Learning (ORL) is a promising approach to reduce the high sample complexity of traditional Reinforcement Learning (RL) by eliminating the need for continuous environmental interactions. ORL exploits a dataset of pre-collected transitions and thus expands the range of application of RL to tasks in which the excessive environment queries increase training time and decrease efficiency, such as in modern AAA games. This paper introduces OfflineMania a novel environment for ORL research. It is inspired by the iconic TrackMania series and developed using the Unity 3D game engine. The environment simulates a single-agent racing game in which the objective is to complete the track through optimal navigation. We provide a variety of datasets to assess ORL performance. These datasets, created from policies of varying ability and in different sizes, aim to offer a challenging testbed for algorithm development and evaluation. We further establish a set of baselines for a range of Online RL, ORL, and hybrid Offline to Online RL approaches using our environment.
Reinforcement Learning for High-Level Strategic Control in Tower Defense Games
Jun 12, 2024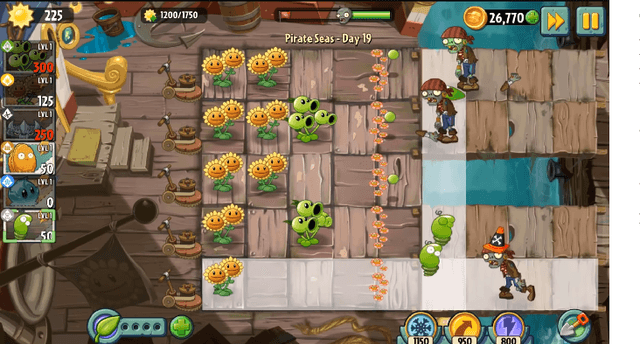
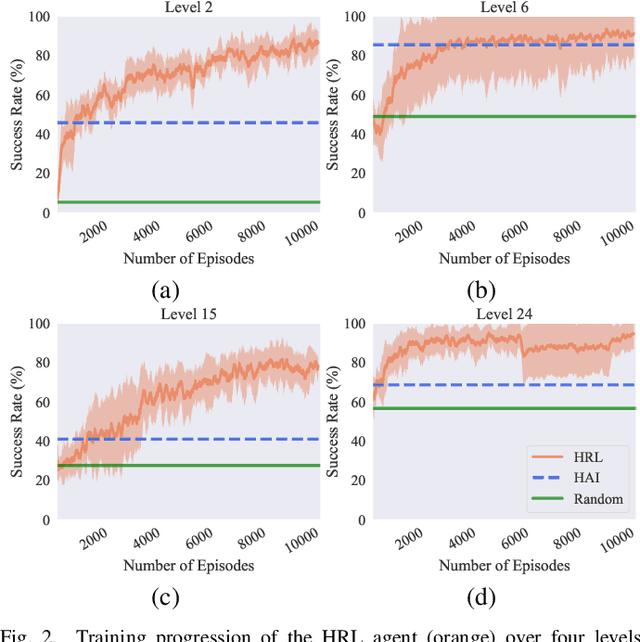
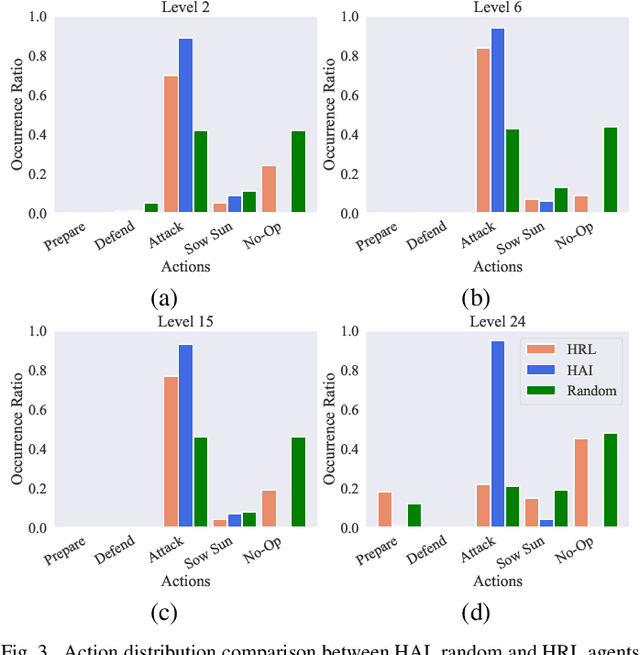
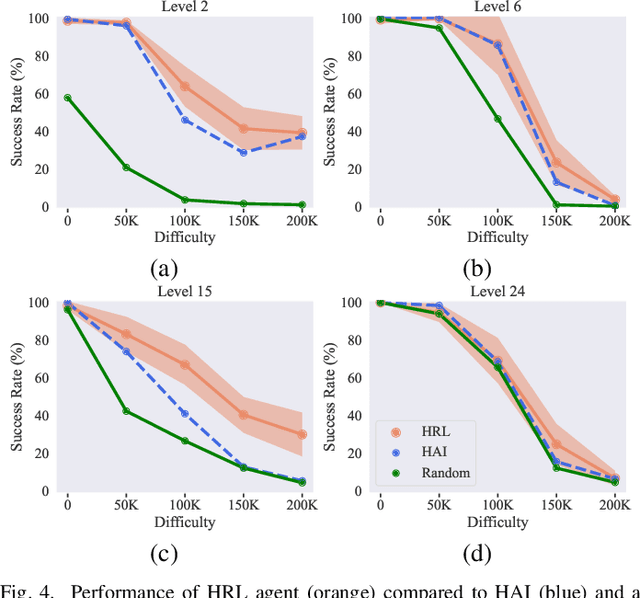
In strategy games, one of the most important aspects of game design is maintaining a sense of challenge for players. Many mobile titles feature quick gameplay loops that allow players to progress steadily, requiring an abundance of levels and puzzles to prevent them from reaching the end too quickly. As with any content creation, testing and validation are essential to ensure engaging gameplay mechanics, enjoyable game assets, and playable levels. In this paper, we propose an automated approach that can be leveraged for gameplay testing and validation that combines traditional scripted methods with reinforcement learning, reaping the benefits of both approaches while adapting to new situations similarly to how a human player would. We test our solution on a popular tower defense game, Plants vs. Zombies. The results show that combining a learned approach, such as reinforcement learning, with a scripted AI produces a higher-performing and more robust agent than using only heuristic AI, achieving a 57.12% success rate compared to 47.95% in a set of 40 levels. Moreover, the results demonstrate the difficulty of training a general agent for this type of puzzle-like game.
Small Dataset, Big Gains: Enhancing Reinforcement Learning by Offline Pre-Training with Model Based Augmentation
Dec 19, 2023Offline reinforcement learning leverages pre-collected datasets of transitions to train policies. It can serve as effective initialization for online algorithms, enhancing sample efficiency and speeding up convergence. However, when such datasets are limited in size and quality, offline pre-training can produce sub-optimal policies and lead to degraded online reinforcement learning performance. In this paper we propose a model-based data augmentation strategy to maximize the benefits of offline reinforcement learning pre-training and reduce the scale of data needed to be effective. Our approach leverages a world model of the environment trained on the offline dataset to augment states during offline pre-training. We evaluate our approach on a variety of MuJoCo robotic tasks and our results show it can jump-start online fine-tuning and substantially reduce - in some cases by an order of magnitude - the required number of environment interactions.
Improving Generalization in Game Agents with Data Augmentation in Imitation Learning
Sep 22, 2023



Imitation learning is an effective approach for training game-playing agents and, consequently, for efficient game production. However, generalization - the ability to perform well in related but unseen scenarios - is an essential requirement that remains an unsolved challenge for game AI. Generalization is difficult for imitation learning agents because it requires the algorithm to take meaningful actions outside of the training distribution. In this paper we propose a solution to this challenge. Inspired by the success of data augmentation in supervised learning, we augment the training data so the distribution of states and actions in the dataset better represents the real state-action distribution. This study evaluates methods for combining and applying data augmentations to observations, to improve generalization of imitation learning agents. It also provides a performance benchmark of these augmentations across several 3D environments. These results demonstrate that data augmentation is a promising framework for improving generalization in imitation learning agents.
Generating Personas for Games with Multimodal Adversarial Imitation Learning
Aug 15, 2023Reinforcement learning has been widely successful in producing agents capable of playing games at a human level. However, this requires complex reward engineering, and the agent's resulting policy is often unpredictable. Going beyond reinforcement learning is necessary to model a wide range of human playstyles, which can be difficult to represent with a reward function. This paper presents a novel imitation learning approach to generate multiple persona policies for playtesting. Multimodal Generative Adversarial Imitation Learning (MultiGAIL) uses an auxiliary input parameter to learn distinct personas using a single-agent model. MultiGAIL is based on generative adversarial imitation learning and uses multiple discriminators as reward models, inferring the environment reward by comparing the agent and distinct expert policies. The reward from each discriminator is weighted according to the auxiliary input. Our experimental analysis demonstrates the effectiveness of our technique in two environments with continuous and discrete action spaces.
Technical Challenges of Deploying Reinforcement Learning Agents for Game Testing in AAA Games
Jul 19, 2023Going from research to production, especially for large and complex software systems, is fundamentally a hard problem. In large-scale game production, one of the main reasons is that the development environment can be very different from the final product. In this technical paper we describe an effort to add an experimental reinforcement learning system to an existing automated game testing solution based on scripted bots in order to increase its capacity. We report on how this reinforcement learning system was integrated with the aim to increase test coverage similar to [1] in a set of AAA games including Battlefield 2042 and Dead Space (2023). The aim of this technical paper is to show a use-case of leveraging reinforcement learning in game production and cover some of the largest time sinks anyone who wants to make the same journey for their game may encounter. Furthermore, to help the game industry to adopt this technology faster, we propose a few research directions that we believe will be valuable and necessary for making machine learning, and especially reinforcement learning, an effective tool in game production.
Efficient Ground Vehicle Path Following in Game AI
Jul 07, 2023This short paper presents an efficient path following solution for ground vehicles tailored to game AI. Our focus is on adapting established techniques to design simple solutions with parameters that are easily tunable for an efficient benchmark path follower. Our solution pays particular attention to computing a target speed which uses quadratic Bezier curves to estimate the path curvature. The performance of the proposed path follower is evaluated through a variety of test scenarios in a first-person shooter game, demonstrating its effectiveness and robustness in handling different types of paths and vehicles. We achieved a 70% decrease in the total number of stuck events compared to an existing path following solution.