 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARC-RL: A Reinforcement Learning Playground Inspired by ARC Raiders
May 20, 2026Reinforcement learning for legged locomotion has matured into a stack of multi-component reward functions and physics-engine benchmarks whose morphologies are uniformly derived from real commercial hardware. Game NPCs, however, are bound by stylistic constraints absent from sim-to-real robotics and routinely take the form of creatures with no real-robot counterpart. We introduce ARC-RL, a suite of four MuJoCo continuous-control environments featuring robotic morphologies inspired by the bestiary of ARC Raiders: the 18-DoF tall hexapod Queen, the 12-DoF armoured hexapod Bastion, the 18-DoF compact hexapod Tick, and the 12-DoF quadruped Leaper. All four robots share a unified observation template, action convention, simulation cadence, and a single closed-form multi-component reward function whose only per-morphology variation lives in a small set of weights and parameters. The reward fuses a velocity-tracking tent, a healthy survive bonus, a phase-locked gait-compliance bonus/cost pair, action regularisers, three safety penalties, and a posture anchor; no motion-capture data enters the reward at any point. We additionally provide hand-crafted Central Pattern Generator demonstrators per morphology, which serve both as fixed expert references and as sources of prior data for offline-to-online training. On this playground, we conduct a controlled empirical study comparing standard online algorithms (SAC, SPEQ, SOPE-EO) and methods augmented with prior data (SACfD, SPEQ-O2O, SOPE), and characterise how each paradigm copes with the playground's morphological diversity and animation-style stylistic constraints. Source code is available at https://github.com/CarloRomeo427/ARC_RL.git.
SOPE: Stabilizing Off-Policy Evaluation for Online RL with Prior Data
May 07, 2026Incorporating prior data into online reinforcement learning accelerates training but typically forces a difficult trade-off between high computational costs and long, multi-stage training pipelines. While fixed-length stabilization phases are significantly more computationally efficient than static update schedules, they require task-dependent manual tuning, risking either the waste of prior knowledge or severe overfitting. To address this, we propose SOPE, an algorithm that uses an actor-aligned Off-Policy Policy Evaluation (OPE) signal as an automated early-stopping mechanism to dynamically control the length of offline training phases. By evaluating the critic on a held-out validation split under the current policy's action distribution, SOPE halts gradient updates exactly when out-of-distribution benefits saturate, eliminating the need for manual schedule tuning. Evaluated on 25 continuous control tasks from the Minari benchmark suite, SOPE improves baseline performance by up to 45.6% while reducing the required TFLOPs by up to 22x, thus balancing the tradeoff between sample and computational efficiency. These findings demonstrate that adaptive, evaluation-driven update schedules are more effective than relying on static, exhaustive update schedules.
NTRL: Encounter Generation via Reinforcement Learning for Dynamic Difficulty Adjustment in Dungeons and Dragons
Jun 24, 2025Balancing combat encounters in Dungeons & Dragons (D&D) is a complex task that requires Dungeon Masters (DM) to manually assess party strength, enemy composition, and dynamic player interactions while avoiding interruption of the narrative flow. In this paper, we propose Encounter Generation via Reinforcement Learning (NTRL), a novel approach that automates Dynamic Difficulty Adjustment (DDA) in D&D via combat encounter design. By framing the problem as a contextual bandit, NTRL generates encounters based on real-time party members attributes. In comparison with classic DM heuristics, NTRL iteratively optimizes encounters to extend combat longevity (+200%), increases damage dealt to party members, reducing post-combat hit points (-16.67%), and raises the number of player deaths while maintaining low total party kills (TPK). The intensification of combat forces players to act wisely and engage in tactical maneuvers, even though the generated encounters guarantee high win rates (70%). Even in comparison with encounters designed by human Dungeon Masters, NTRL demonstrates superior performance by enhancing the strategic depth of combat while increasing difficulty in a manner that preserves overall game fairness.
SPEQ: Stabilization Phases for Efficient Q-Learning in High Update-To-Data Ratio Reinforcement Learning
Jan 15, 2025A key challenge in Deep Reinforcement Learning is sample efficiency, especially in real-world applications where collecting environment interactions is expensive or risky. Recent off-policy algorithms improve sample efficiency by increasing the Update-To-Data (UTD) ratio and performing more gradient updates per environment interaction. While this improves sample efficiency, it significantly increases computational cost due to the higher number of gradient updates required. In this paper we propose a sample-efficient method to improve computational efficiency by separating training into distinct learning phases in order to exploit gradient updates more effectively. Our approach builds on top of the Dropout Q-Functions (DroQ) algorithm and alternates between an online, low UTD ratio training phase, and an offline stabilization phase. During the stabilization phase, we fine-tune the Q-functions without collecting new environment interactions. This process improves the effectiveness of the replay buffer and reduces computational overhead. Our experimental results on continuous control problems show that our method achieves results comparable to state-of-the-art, high UTD ratio algorithms while requiring 56\% fewer gradient updates and 50\% less training time than DroQ. Our approach offers an effective and computationally economical solution while maintaining the same sample efficiency as the more costly, high UTD ratio state-of-the-art.
Offline Reinforcement Learning with Imputed Rewards
Jul 15, 2024
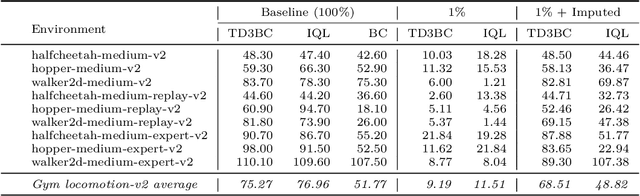

Offline Reinforcement Learning (ORL) offers a robust solution to training agents in applications where interactions with the environment must be strictly limited due to cost, safety, or lack of accurate simulation environments. Despite its potential to facilitate deployment of artificial agents in the real world, Offline Reinforcement Learning typically requires very many demonstrations annotated with ground-truth rewards. Consequently, state-of-the-art ORL algorithms can be difficult or impossible to apply in data-scarce scenarios. In this paper we propose a simple but effective Reward Model that can estimate the reward signal from a very limited sample of environment transitions annotated with rewards. Once the reward signal is modeled, we use the Reward Model to impute rewards for a large sample of reward-free transitions, thus enabling the application of ORL techniques. We demonstrate the potential of our approach on several D4RL continuous locomotion tasks. Our results show that, using only 1\% of reward-labeled transitions from the original datasets, our learned reward model is able to impute rewards for the remaining 99\% of the transitions, from which performant agents can be learned using Offline Reinforcement Learning.