 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation Learning with Concurrent Actions in 3D Games
Sep 06, 2018

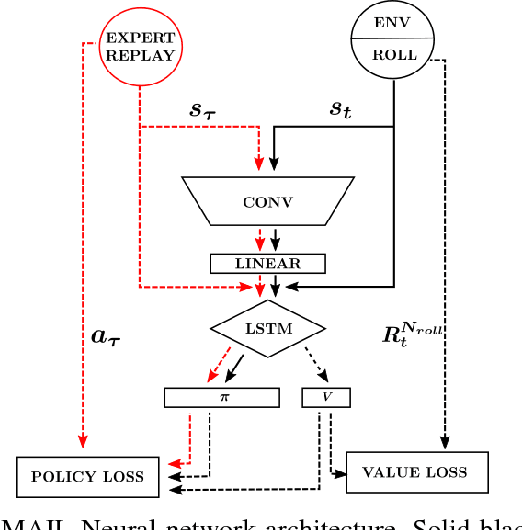

In this work we describe a novel deep reinforcement learning architecture that allows multiple actions to be selected at every time-step in an efficient manner. Multi-action policies allow complex behaviours to be learnt that would otherwise be hard to achieve when using single action selection techniques. We use both imitation learning and temporal difference (TD) reinforcement learning (RL) to provide a 4x improvement in training time and 2.5x improvement in performance over single action selection TD RL. We demonstrate the capabilities of this network using a complex in-house 3D game. Mimicking the behavior of the expert teacher significantly improves world state exploration and allows the agents vision system to be trained more rapidly than TD RL alone. This initial training technique kick-starts TD learning and the agent quickly learns to surpass the capabilities of the expert.